SQL调优学习之——sqlserver分页从低效到高效
背景
首先感谢网友@aixuexi 在评论中的提醒,原博文介绍的几种都不是最高效,现已修改加入另一种更高效的方法。
以前都是使用mysql和oracle,对sqlserver的使用不多。最近因项目原因,要读取其他项目的数据库,取出某个门的开关历史记录,而对方使用的是sqlserver,所以研究起了sqlserver的分页,经过几次实践,慢慢的从低效的分页写到了高效的分页。
表结构
history表
历史记录ID:id(唯一引索)
操作时间:time
开门或关门:flag
由谁操作:user_Id
属于哪个设备:device_id
下面我们先介绍四种分页的方法,以【一种低效】——【两种较高效】——【一种高效】的顺序进阶的介绍,在最后再附上测试结果。
修改:经过网友@aixuexi 的提醒,加入最后一种【更高效】的方法介绍
低效的sql
思路:

最里层:先从history表根据时间倒序查出前50010条记录
中间层:从以上的查询结果中根据时间正序查出前10条记录,一正一反刚好就拿出了第10000条到10010条记录了。
最外层:根据时间倒序拿出以上的查询结果
SQL代码:
select * from
(
select top 10 * from
(
select top 50010 * from history
order by
time desc
) h
order by
h.time asc
) hh
order by
hh.time desc
经下面的检验,这种查询效率比较低下。
其原因是因为每一层的查询都使用了select * ,即扫描所有的这段,但是 “最里层” 和 “中间层” 根本就没必要select * ,这两层目的只是为了把最后一层的搜索范围定位在第10000-10010条之间,所以,在这两层里,我们只要拿出关键字ID和排序字段time就好。
较高效的SQL(1)————使用where ... =
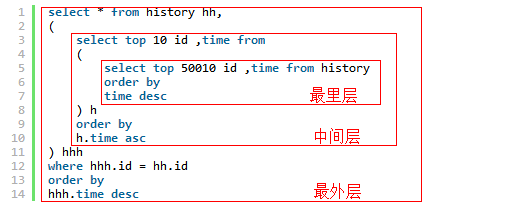
最里层:先从history表根据时间倒序查出前50010条记录,只拿出id和time
中间层:从以上的查询结果中根据时间正序查出前10条记录,只拿出id和time,一正一反刚好就拿出了第10000条到10010条记录了。
最外层:根据时间倒序拿出以上的查询结果,select *拿出所有字段,查询范围用where ... = ... 来匹配。
SQL代码:
select * from history hh,
(
select top 10 id ,time from
(
select top 50010 id ,time from history
order by
time desc
) h
order by
h.time asc
) hhh
where hhh.id = hh.id
order by
hhh.time desc
经检验,这种分页 方法比上一种快一点点。
主要原因在与“最里层”和“中间层”的两次查询,都只是查出id和time,而不是select * ,从这个角度讲提升了效率。但最后又用了where...=语法,比起上一种分页方法,又降低了一点效率。但是where...=语法速度很快,所以总体上还是这种分页方法更快一些。
较高效的分页(2)————使用where...in

最里层:先从history表根据时间倒序查出前50010条记录,只拿出id和time
中间层:从以上的查询结果中根据时间正序查出前10条记录,只拿出id和time,一正一反刚好就拿出了第10000条到10010条记录了。
最外层:根据时间倒序拿出以上的查询结果,select *拿出所有字段,查询范围用where...in ()来匹配
SQL代码:
select * from history hh
where id in
(
select top 10 id from
(
select top 50010 id ,time from history
order by
time desc
) h
order by
h.time asc
)
order by
hh.time des
这种分页方法,与上一种分页方法比起来,区别是这种使用了where...in(),而不是where...=,原理上差别不大,但可能是SQLServer内部优化的原因,使用where...in比使用where...=要快一些。具体在下面的计较表格可以看出。
高效的分页————使用row_number() over
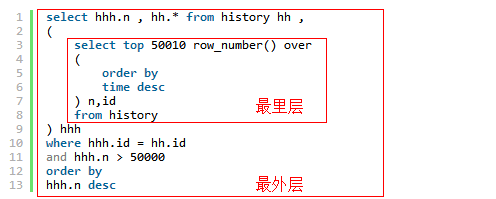
最里层:查询出前50010条数据,只拿出ID字段,同时使用row_number() over 语法,增加一个n字段,代表该条数据时第几行。
最外层:根据where...来匹配id,同时直接拿出 n>50000 的数据。
SQL代码:
select hhh.n , hh.* from history hh ,
(
select top 50010 row_number() over
(
order by
time desc
) n,id
from history
) hhh
where hhh.id = hh.id
and hhh.n > 50000
order by
hhh.n desc
这种分页方法,首先只是两次查询,这无非提高了效率。最里层查询出来的“虚列”——n,sqlserver不知道会不会为其加上索引,个人认为会,但想不出什么验证的方法。假如有加入索引的话,那在这个地方,使用 “n >某个数字” 的查询方法,又比前几次查询快了一点。
更高效的分页——row_number() over + 只查询一次

最里层:查询出前50010条数据,使用row_number() over 语法,增加一个n字段,代表该条数据时第几行,同时查出我们想要的信息,这里跟其他方法一样查询出所有:*。
最外层:根据where...来匹配n,同时直接拿出 n>50000 且 n<50010 行的数据。
SQL代码:
select * from
(
select *,row_number() over
(
order by
time desc
) n
from history
) hhh
where hhh.n > 50000
and hhh.n <= 50010
几种分页方法速度比较
以下进行两种测试,第一种是查询出1000-1010条数据,第二种是查询出第50000-50010条数据。记录的秒数是查询50次总共的用时,每组测试5次,最后取平均值。
| 【查询1000-1010条数据】 | 第一次 | 第二次 | 第三次 | 第四次 | 第五次 | 平均 |
| 低效的分页 | 6.344s | 5.687s | 5.797s | 5.704s | 5.641s | 5.835s |
| 较高效的分页(1)——where...= | 4.485s | 5.281s | 5.094s | 5.281s | 5.313s | 5.091s(胜出) |
| 较高效的分页(1)——where...in | 5.093s | 5.328s | 5.14s | 5.406s | 5.297s | 5.253s |
| 高效的分页——row_number() over | 5.437s | 5.39s | 5.156s | 5.016s | 5.344s | 5.269 |
| 更高效的分页——row_number() over + 只查询一次 | 5.188s | 4.875s | 5.172s | 4.953s | 4.875s | 5.0126s(胜出) |
从中可以看出,在查询的行数较少时,使用 【更高效的分页——row_number() over + 只查询一次】是最快的一种分页方法。
| 【查询50000-50010条数据】 | 第一次 | 第二次 | 第三次 | 第四次 | 第五次 | 平均 |
| 低效的分页 | 10.844s | 9.985s | 10.172s | 10.0s | 10.297s | 10.260s |
| 较高效的分页(1)——where...= | 9.625s | 9.469s | 9.14s | 9.171s | 9.219s | 9.325s |
| 较高效的分页(1)——where...in | 9.156s | 9.61s | 9.187s | 9.218s | 9.219s | 9.278s |
| 高效的分页——row_number() over | 7.844s | 6.765s | 6.422s | 7.359s | 6.875s | 7.05s(胜出) |
| 更高效的分页——row_number() over + 只查询一次 | 6.730s | 6.109s | 7.109s | 5.328s | 5.515s | 6.086s(胜出) |
从中可用看出,在查询的行数较多时,使用【更高效的分页——row_number() over + 只查询一次】是最快的一种分页方法,而且快了好几个档次!
SQL调优学习之——sqlserver分页从低效到高效的更多相关文章
- 《高性能SQL调优精要与案例解析》一书谈SQL调优(SQL TUNING或SQL优化)学习
<高性能SQL调优精要与案例解析>一书上市发售以来,很多热心读者就该书内容及一些具体问题提出了疑问,因读者众多外加本人日常工作的繁忙 ,在这里就SQL调优学习进行讨论并对热点问题统一作答. ...
- SQL调优
# 问题的提出 在应用系统开发初期,由于开发数据库数据比较少,对于查询SQL语句,复杂视图的的编写等体会不出SQL语句各种写法的性能优劣,但是如果将应用 系统提交实际应用后,随着数据库中数据的增加,系 ...
- 记一次SQL调优/优化(SQL tuning)——性能大幅提升千倍以上
好久不写东西了,一直忙于各种杂事儿,恰巧昨天有个用户研发问到我一个SQL调优的问题,说性能太差,希望我能给调优下,最近有些懒,可能和最近太忙有关系,本来打算问问现在的情况,如果差不多就不调了,那哥们儿 ...
- 梁敬彬老师的《收获,不止SQL优化》,关于如何缩短SQL调优时间,给出了三个步骤,
梁敬彬老师的<收获,不止SQL优化>,关于如何缩短SQL调优时间,给出了三个步骤, 1. 先获取有助调优的数据库整体信息 2. 快速获取SQL运行台前信息 3. 快速获取SQL关联幕后信息 ...
- MySQL索引和SQL调优手册
MySQL索引 MySQL支持诸多存储引擎,而各种存储引擎对索引的支持也各不相同,因此MySQL数据库支持多种索引类型,如BTree索引,哈希索引,全文索引等等.为了避免混乱,本文将只关注于BTree ...
- SQL调优常用方法
在使用DBMS时经常对系统的性能有非常高的要求:不能占用过多的系统内存和 CPU资源.要尽可能快的完成的数据库操作.要有尽可能高的系统吞吐量.如果系统开发出来不能满足要求的所有性能指标,则必须对系统进 ...
- 读《程序员的SQL金典》[4]--SQL调优
一.SQL注入 如果程序中采用sql拼接的方式书写代码,那么很可能存在SQL注入漏洞.避免的方式有两种: 1. 对于用户输入过滤敏感字母: 2. 参数化SQL(推荐). 二.索引 ①索引分类 聚簇索引 ...
- [SQL SERVER系列]读书笔记之SQL注入漏洞和SQL调优
最近读了程序员的SQL金典这本书,觉得里面的SQL注入漏洞和SQL调优总结得不错,下面简单讨论下SQL注入漏洞和SQL调优. 1. SQL注入漏洞 由于“'1'='1'”这个表达式永远返回 true, ...
- SQL调优日志--内存问题
SQL调优日志--内存问题排查入门篇 概述 很多系统的性能问题,是由内存导致的.内存不够会导致页面频繁换入换出,IO队列高,进而影响数据库整体性能. 排查 内存对数据库性能非常重要.那么我当出现问 ...
随机推荐
- JavaSE集合(八)之Map
前面给大家介绍了集合家族中的Collection家族,这一篇给大家分享的是集合中的另一个家族就是Map家族.以前的时候学习Map的时候没有很认真的去学习,我觉得很多东西还是不是很清楚. 这次我将总结的 ...
- POJ 3211 Washing Clothes 背包题解
本题是背包问题,可是须要转化成背包的. 由于是两个人洗衣服,那么就是说一个人仅仅须要洗一半就能够了,由于不能两个人同一时候洗一件衣服,所以就成了01背包问题了. 思路: 1 计算洗完同一颜色的衣服须要 ...
- Linux性能研究(总)
http://www.vpsee.com/2009/11/linux-system-performance-monitoring-introduction/ http://www.jb51.net/L ...
- hadoop基础学习---基本概念
1.组成部分HDFS和MapReduce 2.HDFS这几架构
- Ubuntu 13.10 安装 Oracle11gR2
#step 1: groupadd -g 2000 dba useradd -g 2000 -m -s /bin/bash -u 2000 grid useradd -g 2000 -m ...
- BleedTree动画混合树
通过Unity动画状态机,能帮我们轻松处理转换各个动画片断,达到想要的效果,但是如果仅仅是一个个动画的硬生生的切换,那么看起来就非常突然,而不真实了,在质量要求比较高的游戏中,特别是动作游戏,我们就不 ...
- 笔记:php有那几种错误提示和查错方法
php有哪几种错误提示 1.notice : 注意 2.waring : 警告 3.error : 错误 PHP中都有哪几种查错方法? 1.语法检查--php配置文件里,把错误显示选项都打开或者代码开 ...
- 【spring教程之中的一个】创建一个最简单的spring样例
1.首先spring的主要思想,就是依赖注入.简单来说.就是不须要手动new对象,而这些对象由spring容器统一进行管理. 2.样例结构 如上图所看到的,採用的是mavenproject. 2.po ...
- 【RF库Collections测试】Insert Into List
Name:Insert Into ListSource:Collections <test library>Arguments:[ list_ | index | value ]Inser ...
- 批处理bat文件dos命令实现文件的解压缩
::========压缩文件======================= ::将源路径“C:\Users\xcc\Desktop\多大的经济 ”路径下的文件压缩到目标路径下“D:\迅雷下载\压缩.r ...