Python开发【数据结构】:算法(二)
堆排序
1、—树与二叉树简介
树是一种数据结构 比如:目录结构
树是一种可以递归定义的数据结构
树是由n个节点组成的集合:
- 如果n=0,那这是一棵空树;
- 如果n>0,那存在1个节点作为树的根节点,其他节点可以分为m个集合,每个集合本身又是一棵树;
一些概念
- 根节点、
- 叶子节点
- 树的深度(高度)
- 树的度
- 孩子节点/父节点
- 子树
示图:

2、二叉树
二叉树:度不超过2的树(节点最多有两个叉)
示图:

3、两种特殊二叉树
- 满二叉树
- 完全二叉树
示图:

4、二叉树的存储方式
- 链式存储方式
- 顺序存储方式(列表)
示图:

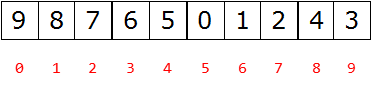
父节点和左孩子节点的编号下标有什么关系?
- 0-1 1-3 2-5 3-7 4-9
i ~ 2i+1
父节点和右孩子节点的编号下标有什么关系?
- 0-2 1-4 2-6 3-8 4-10
i – 2i+2
5、堆
堆:
- 大根堆:一棵完全二叉树,满足任一节点都比其孩子节点大
- 小根堆:一棵完全二叉树,满足任一节点都比其孩子节点小
大根堆:

小根堆:

6、堆排序过程
- 建立堆
- 得到堆顶元素,
- 为最大元素 去掉堆顶,将堆最后一个元素放到堆顶,此时可通过一次调整重新使堆有序。
- 堆顶元素为第二大元素
- 重复步骤3,直到堆变空
7、构造堆
def sift(data,low,high):
#low 要调整范围的根节点
#high 整个data的最后一个节点
i = low
j = 2 * i + 1 #左孩子
tmp = data[i] #去出跟节点
while j <= high: #左孩子在列表里面,表明i有孩子
if j+1 <= high and data[j] < data[j+1]: #如果有右孩子并且右孩子比左孩子大
j = j + 1
if data[j] > tmp:
data[i] = data[j]
i = j
j = 2 *i +1
else:
break
data[i] = tmp def heap_sort(data):
n = len(data)
for i in range(n//2-1,-1,-1): # n//2-1 固定用法
sift(data,i,n-1) # 构造堆
8、堆排序
完整代码:
import time
import random def call_time(func):
def inner(*args,**kwargs):
t1 = time.time()
re = func(*args,**kwargs)
t2 = time.time()
print('Time cost:',func.__name__,t2-t1)
return re
return inner def sift(data,low,high):
#low 要调整范围的根节点
#high 整个data的最后一个节点
i = low
j = 2 * i + 1 #左孩子
tmp = data[i] #去出跟节点
while j <= high: #左孩子在列表里面,表明i有孩子
if j+1 <= high and data[j] < data[j+1]: #如果有右孩子并且右孩子比左孩子大
j = j + 1
if data[j] > tmp:
data[i] = data[j]
i = j
j = 2 *i +1
else:
break
data[i] = tmp @call_time
def heap_sort(data):
n = len(data)
for i in range(n//2-1,-1,-1): # n//2-1 固定用法
sift(data,i,n-1) # 构造堆 for i in range(n): # 循环n次每次出一个数
data[0],data[n-1-i] = data[n-1-i],data[0]
sift(data,0,n-1-i-1) data = list(range(10000))
random.shuffle(data) heap_sort(data)
# Time cost: heap_sort 0.08801126480102539
时间复杂度:O(nlogn)
归并排序
将两段有序列表,将其合并为一个有序列表
例:
[2,5,7,8,91,3,4,6]
思路:

分解:将列表越分越小,直至分成一个元素
一个元素是有序的
合并:将两个有序列表归并,列表越来越大
代码:
import time
import random def call_time(func):
def inner(*args,**kwargs):
t1 = time.time()
re = func(*args,**kwargs)
t2 = time.time()
print('Time cost:',func.__name__,t2-t1)
return re
return inner def merge(li, low, mid, high):
i = low
j = mid + 1
ltmp = []
while i <= mid and j <= high:
if li[i] < li[j]:
ltmp.append(li[i])
i += 1
else:
ltmp.append(li[j])
j += 1
while i <= mid:
ltmp.append(li[i])
i += 1
while j <= high:
ltmp.append(li[j])
j += 1
li[low:high+1] = ltmp def _mergesort(li, low, high):
if low < high:
mid = (low + high) // 2
_mergesort(li,low, mid)
_mergesort(li, mid+1, high)
merge(li, low, mid, high) @call_time
def mergesort(li):
_mergesort(li, 0, len(li) - 1) data = list(range(10000))
random.shuffle(data) mergesort(data)
# Time cost: mergesort 0.0835103988647461
时间复杂度:O(nlogn)
希尔排序
希尔排序是一种分组插入排序算法。
首先取一个整数d1=n/2,将元素分为d1个组,每组相邻量元素之间距离为d1,在各组内进行直接插入排序;
取第二个整数d2=d1/2,重复上述分组排序过程,直到di=1,即所有元素在同一组内进行直接插入排序。
希尔排序每趟并不使某些元素有序,而是使整体数据越来越接近有序;最后一趟排序使得所有数据有序
代码:
import time
import random def call_time(func):
def inner(*args,**kwargs):
t1 = time.time()
re = func(*args,**kwargs)
t2 = time.time()
print('Time cost:',func.__name__,t2-t1)
return re
return inner @call_time
def shell_sort(li):
gap = len(li) // 2
while gap >= 1:
for i in range(gap, len(li)):
tmp = li[i]
j = i - gap
while j >= 0 and tmp < li[j]:
li[j + gap] = li[j]
j -= gap
li[j + gap] = tmp
gap = gap // 2 data = list(range(10000))
random.shuffle(data) shell_sort(data)
# Time cost: shell_sort 0.1275160312652588
时间复杂度:O(nlogn)
快速排序、堆排序、归并排序对比:
三种排序算法的时间复杂度都是O(nlogn)
一般情况下,就运行时间而言:
- 快速排序 < 归并排序 < 堆排序
三种排序算法的缺点:
- 快速排序:极端情况下排序效率低
- 归并排序:需要额外的内存开销
- 堆排序:在快的排序算法中相对较慢
比较时间:
quick_sort(data1) # 快排
heap_sort(data2) # 堆排
mergesort(data3) # 归排
sys_sort(data4) #系统自带 # Time cost: quick_sort 0.053006649017333984
# Time cost: heap_sort 0.08601117134094238
# Time cost: mergesort 0.08000993728637695
# Time cost: sys_sort 0.004500627517700195
视图:

第二十八章
Python开发【数据结构】:算法(二)的更多相关文章
- 用Python实现数据结构之二叉搜索树
二叉搜索树 二叉搜索树是一种特殊的二叉树,它的特点是: 对于任意一个节点p,存储在p的左子树的中的所有节点中的值都小于p中的值 对于任意一个节点p,存储在p的右子树的中的所有节点中的值都大于p中的值 ...
- Python开发【十二章】:ORM sqlalchemy
一.对象映射关系(ORM) orm英文全称object relational mapping,就是对象映射关系程序,简单来说我们类似python这种面向对象的程序来说一切皆对象,但是我们使用的数据库却 ...
- PYTHON开发--面向对象基础二
一.成员修饰符 共有成员 私有成员, __字段名 - 无法直接访问,只能间接访问 1. 私有成员 1.1 普通方法种的私有成员 class Foo: def __init__(self, n ...
- 机器学习:Python实现聚类算法(二)之AP算法
1.算法简介 AP(Affinity Propagation)通常被翻译为近邻传播算法或者亲和力传播算法,是在2007年的Science杂志上提出的一种新的聚类算法.AP算法的基本思想是将全部数据点都 ...
- Python开发【算法】:斐波那契数列两种时间复杂度
斐波那契数列 概述: 斐波那契数列,又称黄金分割数列,指的是这样一个数列:0.1.1.2.3.5.8.13.21.34.……在数学上,斐波纳契数列以如下被以递归的方法定义:F(0)=0,F(1)=1, ...
- python开发初期及二次开发C api
1,python2 or python 区别, https://wiki.python.org/moin/Python2orPython3 python software foundation 2,p ...
- Python开发——数据结构【深浅拷贝】
浅拷贝 # 浅拷贝只copy一层 s = [3,'Lucy',4,[1,2]] s1 = s.copy() 深拷贝 # 深拷贝——克隆一分 import copy s = [3,'Lucy',4,[1 ...
- python 实现排序算法(二)-合并排序(递归法)
#!/usr/bin/env python2 # -*- coding: utf-8 -*- """ Created on Tue Nov 21 22:28:09 201 ...
- python实现排序算法二:归并排序
##归并排序 ##基本思想:对于两个排好序的数组A和B,逐一比较A和B的元素,将较小值放入数组C中,当A或者B数组元素查询完后,将A或者B剩余的元素直接添加到C数组中,此时C数组即为有序数组,这就是归 ...
- Python开发——目录
Python基础 Python开发——解释器安装 Python开发——基础 Python开发——变量 Python开发——[选择]语句 Python开发——[循环]语句 Python开发——数据类型[ ...
随机推荐
- perl 脚本将phred33 转换为phred64
今天用fastx_tookit 时遇到问题, 我的fastq 文件的碱基质量值格式为phred33, 而fastq_tookit 默认碱基质量值的格式为phred64, 所以报错了,提示我的fastq ...
- 动态调用WCF不添加服务(svcutil.exe)
记录下 首先用svcutil.exe把指定wcf接口的信息下载下来. 生成代理类 比如说接口地址为 http://localhost:6666/Service1.svc 以管理员身份打开cmd 执形 ...
- 【Java面试题】4 静态变量和实例变量的区别?详细解析
在语法定义上的区别:静态变量前要加static关键字,而实例变量前则不加.在程序运行时的区别:实例变量属于某个对象的属性,必须创建了实例对象,其中的实例变量才会被分配空间,才能使用这个实例变量.静态变 ...
- POJ 3211 Washing Clothes 背包题解
本题是背包问题,可是须要转化成背包的. 由于是两个人洗衣服,那么就是说一个人仅仅须要洗一半就能够了,由于不能两个人同一时候洗一件衣服,所以就成了01背包问题了. 思路: 1 计算洗完同一颜色的衣服须要 ...
- Unity带参数的协程
两种方法都可以传递参数,代码如下: using UnityEngine; using System.Collections; public class Test : MonoBehaviour { v ...
- 关于BSTR数据类型
关于BSTR数据类型 - 极品垃圾 - C++博客 http://www.cppblog.com/bestcln/articles/82712.html VC++常用数据类型及其操作详解(非常经典,共 ...
- 记录下DynamicXml和HtmlDocument 使用方式
之前解析都是XmlDocument.Load 而现在可以利用DynamicXml生成Dynamic对象实现强类型操作,很好用. /// <summary> /// 根据Xml路径动态解析成 ...
- Messages: No result defined for action cn.itcast.oa.test.TestAction and result SUCCESS
Struts Problem Report Struts has detected an unhandled exception: Messages: No result defined for ac ...
- python2.0_s12_day19_前端模版使用
Django中引用bootstrap实现在前端可以创建客户信息,可以修改客户信息我们需要设计一个前端用户交互系统.我们在设计之前,讨论一些需求:前端实现:1. 不同角色的用户,看到的东西是不一样的 销 ...
- mySQL数据库一:数据类型
integer(整型)varchar(字符串类型,必须要跟最大字符串)text(大文本)float(单精度,即七到八位有效数字)double(双精度,即15到16位有效数字)date(只有年月日)ti ...