Python开发【数据结构】:算法(二)
堆排序
1、—树与二叉树简介
树是一种数据结构 比如:目录结构
树是一种可以递归定义的数据结构
树是由n个节点组成的集合:
- 如果n=0,那这是一棵空树;
- 如果n>0,那存在1个节点作为树的根节点,其他节点可以分为m个集合,每个集合本身又是一棵树;
一些概念
- 根节点、
- 叶子节点
- 树的深度(高度)
- 树的度
- 孩子节点/父节点
- 子树
示图:

2、二叉树
二叉树:度不超过2的树(节点最多有两个叉)
示图:

3、两种特殊二叉树
- 满二叉树
- 完全二叉树
示图:

4、二叉树的存储方式
- 链式存储方式
- 顺序存储方式(列表)
示图:

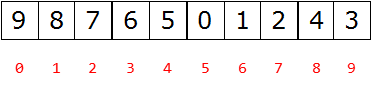
父节点和左孩子节点的编号下标有什么关系?
- 0-1 1-3 2-5 3-7 4-9
i ~ 2i+1
父节点和右孩子节点的编号下标有什么关系?
- 0-2 1-4 2-6 3-8 4-10
i – 2i+2
5、堆
堆:
- 大根堆:一棵完全二叉树,满足任一节点都比其孩子节点大
- 小根堆:一棵完全二叉树,满足任一节点都比其孩子节点小
大根堆:

小根堆:

6、堆排序过程
- 建立堆
- 得到堆顶元素,
- 为最大元素 去掉堆顶,将堆最后一个元素放到堆顶,此时可通过一次调整重新使堆有序。
- 堆顶元素为第二大元素
- 重复步骤3,直到堆变空
7、构造堆
def sift(data,low,high):
#low 要调整范围的根节点
#high 整个data的最后一个节点
i = low
j = 2 * i + 1 #左孩子
tmp = data[i] #去出跟节点
while j <= high: #左孩子在列表里面,表明i有孩子
if j+1 <= high and data[j] < data[j+1]: #如果有右孩子并且右孩子比左孩子大
j = j + 1
if data[j] > tmp:
data[i] = data[j]
i = j
j = 2 *i +1
else:
break
data[i] = tmp def heap_sort(data):
n = len(data)
for i in range(n//2-1,-1,-1): # n//2-1 固定用法
sift(data,i,n-1) # 构造堆
8、堆排序
完整代码:
import time
import random def call_time(func):
def inner(*args,**kwargs):
t1 = time.time()
re = func(*args,**kwargs)
t2 = time.time()
print('Time cost:',func.__name__,t2-t1)
return re
return inner def sift(data,low,high):
#low 要调整范围的根节点
#high 整个data的最后一个节点
i = low
j = 2 * i + 1 #左孩子
tmp = data[i] #去出跟节点
while j <= high: #左孩子在列表里面,表明i有孩子
if j+1 <= high and data[j] < data[j+1]: #如果有右孩子并且右孩子比左孩子大
j = j + 1
if data[j] > tmp:
data[i] = data[j]
i = j
j = 2 *i +1
else:
break
data[i] = tmp @call_time
def heap_sort(data):
n = len(data)
for i in range(n//2-1,-1,-1): # n//2-1 固定用法
sift(data,i,n-1) # 构造堆 for i in range(n): # 循环n次每次出一个数
data[0],data[n-1-i] = data[n-1-i],data[0]
sift(data,0,n-1-i-1) data = list(range(10000))
random.shuffle(data) heap_sort(data)
# Time cost: heap_sort 0.08801126480102539
时间复杂度:O(nlogn)
归并排序
将两段有序列表,将其合并为一个有序列表
例:
[2,5,7,8,91,3,4,6]
思路:

分解:将列表越分越小,直至分成一个元素
一个元素是有序的
合并:将两个有序列表归并,列表越来越大
代码:
import time
import random def call_time(func):
def inner(*args,**kwargs):
t1 = time.time()
re = func(*args,**kwargs)
t2 = time.time()
print('Time cost:',func.__name__,t2-t1)
return re
return inner def merge(li, low, mid, high):
i = low
j = mid + 1
ltmp = []
while i <= mid and j <= high:
if li[i] < li[j]:
ltmp.append(li[i])
i += 1
else:
ltmp.append(li[j])
j += 1
while i <= mid:
ltmp.append(li[i])
i += 1
while j <= high:
ltmp.append(li[j])
j += 1
li[low:high+1] = ltmp def _mergesort(li, low, high):
if low < high:
mid = (low + high) // 2
_mergesort(li,low, mid)
_mergesort(li, mid+1, high)
merge(li, low, mid, high) @call_time
def mergesort(li):
_mergesort(li, 0, len(li) - 1) data = list(range(10000))
random.shuffle(data) mergesort(data)
# Time cost: mergesort 0.0835103988647461
时间复杂度:O(nlogn)
希尔排序
希尔排序是一种分组插入排序算法。
首先取一个整数d1=n/2,将元素分为d1个组,每组相邻量元素之间距离为d1,在各组内进行直接插入排序;
取第二个整数d2=d1/2,重复上述分组排序过程,直到di=1,即所有元素在同一组内进行直接插入排序。
希尔排序每趟并不使某些元素有序,而是使整体数据越来越接近有序;最后一趟排序使得所有数据有序
代码:
import time
import random def call_time(func):
def inner(*args,**kwargs):
t1 = time.time()
re = func(*args,**kwargs)
t2 = time.time()
print('Time cost:',func.__name__,t2-t1)
return re
return inner @call_time
def shell_sort(li):
gap = len(li) // 2
while gap >= 1:
for i in range(gap, len(li)):
tmp = li[i]
j = i - gap
while j >= 0 and tmp < li[j]:
li[j + gap] = li[j]
j -= gap
li[j + gap] = tmp
gap = gap // 2 data = list(range(10000))
random.shuffle(data) shell_sort(data)
# Time cost: shell_sort 0.1275160312652588
时间复杂度:O(nlogn)
快速排序、堆排序、归并排序对比:
三种排序算法的时间复杂度都是O(nlogn)
一般情况下,就运行时间而言:
- 快速排序 < 归并排序 < 堆排序
三种排序算法的缺点:
- 快速排序:极端情况下排序效率低
- 归并排序:需要额外的内存开销
- 堆排序:在快的排序算法中相对较慢
比较时间:
quick_sort(data1) # 快排
heap_sort(data2) # 堆排
mergesort(data3) # 归排
sys_sort(data4) #系统自带 # Time cost: quick_sort 0.053006649017333984
# Time cost: heap_sort 0.08601117134094238
# Time cost: mergesort 0.08000993728637695
# Time cost: sys_sort 0.004500627517700195
视图:

第二十八章
Python开发【数据结构】:算法(二)的更多相关文章
- 用Python实现数据结构之二叉搜索树
二叉搜索树 二叉搜索树是一种特殊的二叉树,它的特点是: 对于任意一个节点p,存储在p的左子树的中的所有节点中的值都小于p中的值 对于任意一个节点p,存储在p的右子树的中的所有节点中的值都大于p中的值 ...
- Python开发【十二章】:ORM sqlalchemy
一.对象映射关系(ORM) orm英文全称object relational mapping,就是对象映射关系程序,简单来说我们类似python这种面向对象的程序来说一切皆对象,但是我们使用的数据库却 ...
- PYTHON开发--面向对象基础二
一.成员修饰符 共有成员 私有成员, __字段名 - 无法直接访问,只能间接访问 1. 私有成员 1.1 普通方法种的私有成员 class Foo: def __init__(self, n ...
- 机器学习:Python实现聚类算法(二)之AP算法
1.算法简介 AP(Affinity Propagation)通常被翻译为近邻传播算法或者亲和力传播算法,是在2007年的Science杂志上提出的一种新的聚类算法.AP算法的基本思想是将全部数据点都 ...
- Python开发【算法】:斐波那契数列两种时间复杂度
斐波那契数列 概述: 斐波那契数列,又称黄金分割数列,指的是这样一个数列:0.1.1.2.3.5.8.13.21.34.……在数学上,斐波纳契数列以如下被以递归的方法定义:F(0)=0,F(1)=1, ...
- python开发初期及二次开发C api
1,python2 or python 区别, https://wiki.python.org/moin/Python2orPython3 python software foundation 2,p ...
- Python开发——数据结构【深浅拷贝】
浅拷贝 # 浅拷贝只copy一层 s = [3,'Lucy',4,[1,2]] s1 = s.copy() 深拷贝 # 深拷贝——克隆一分 import copy s = [3,'Lucy',4,[1 ...
- python 实现排序算法(二)-合并排序(递归法)
#!/usr/bin/env python2 # -*- coding: utf-8 -*- """ Created on Tue Nov 21 22:28:09 201 ...
- python实现排序算法二:归并排序
##归并排序 ##基本思想:对于两个排好序的数组A和B,逐一比较A和B的元素,将较小值放入数组C中,当A或者B数组元素查询完后,将A或者B剩余的元素直接添加到C数组中,此时C数组即为有序数组,这就是归 ...
- Python开发——目录
Python基础 Python开发——解释器安装 Python开发——基础 Python开发——变量 Python开发——[选择]语句 Python开发——[循环]语句 Python开发——数据类型[ ...
随机推荐
- 基于Bootstrap使用jQuery实现输入框组input-group的添加与删除-改进版
上一次说到了基于Bootstrap使用jQuery实现输入框组input-group的添加与删除 ,初始状态下只有一个输入框组,可以通过点击输入框组的右侧“+”(或自定义的文字)可以在原输入框组的下面 ...
- CSS使用学习总结
尽量少使用类,因为可以层叠识别,如: .News h3而不必在h3上加类 <div class=”News”> <h3></h3> <h2></h ...
- 教您如何在Word的mathtype加载项中修改章节号
在MathType数学公式编辑器中,公式编号共有五部分内容:分别是章编号(Chapter Number).节编号(Section Number).公式编号(Equation Number).括号(En ...
- linux mint 19解决 输入法问题
安装搜狗后出现 You're currently running Fcitx with GUI, but fcitx-configtool couldn't be found, the package ...
- brew 中的时间格式转换
char * pACNowStr = NULL; JulianType jtNow; ISHELL_GetJulianDate(pIShell, , &jtNow); pACNowStr = ...
- abs()
abs() 用于返回一个数值的绝对值 In [1]: abs(10) Out[1]: 10 In [2]: abs(-10) Out[2]: 10 In [3]: abs(-10.9) Out[3]: ...
- 如何让IOS中的文本实现3D效果
本转载至 http://bbs.aliyun.com/read/181991.html?spm=5176.7114037.1996646101.25.p0So7c&pos=9 zh ...
- PyQt4消息窗口
默认情况下,如果我们单击了窗口标题栏上的X标记,窗口就会被关闭.但是有些时候我们想要改变这一默认行为.比如,我们正在编辑的文件内容发生了变化,这时若单击X标记关闭窗口,编辑器就应当但出确认窗口. #! ...
- JavaScript的记忆函数真的可以提升性能吗?
1 记忆函数是什么呢? 让函数记住曾经计算过的参数对应的结果 2 那我们为什么使用记忆函数呢? 答案是 避免重复计算 3 在工作中如何使用和实现函数记忆 ? 形成闭包,在闭包中维护一个哈希数组(其 ...
- mysql增删改查基本语句
mysql的增删改查属于基本操作,又被简称CRUD,其中删用的较少,毕竟这个功能给用户是是非常危险的,就是客户删除的数据也没有真正的删除,其中查询是十分常用的. 1 mysql数据库增加:create ...