认识HDFS分布式文件系统
1.设计基础目标
(1) 错误是常态,需要使用数据冗余
(2)流式数据访问。数据批量读而不是随机速写,不支持OLTP,hadoop擅长数据分析而不是事物处理。
(3)文件采用一次性写多次读的模型,文件一旦写入就无法修改。所以一致性模型非常简单。
(4)程序采用 数据就近 原则分配节点执行。(MapReduce)
2.hdf体系结构
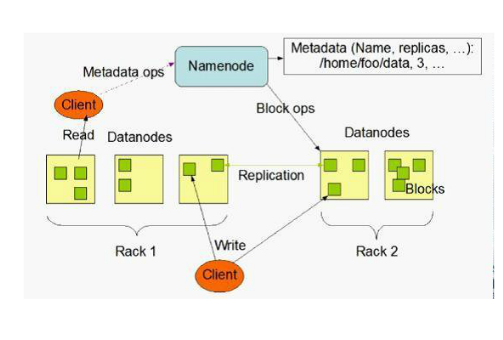
hadfs设计十分简单,在我的1个master和两个slave节点的集群中,通过jps,可以查看在master节点上运行着SecondaryNameNode ,NameNode,JobTracker
在slave结点上运行着DataNode和TaskTracker进程
1.NameNode:管理文件系统的命名空间,记录每个文件数据快在各个DataNode上的位置和副本信息,记录命名空间内的改动或空间本身属性的改动;协调客户端对文件的访问;
NameNode使 用事物日志记录HDFS元数据的变化,使用映像文件存储文件系统的命名空间,
2.DataNode:管理存储节点,一次写入,多次读取,不支持修改。文件由数据块组成,包括文件映射,文件属性。默认的数据块大小为64MB,数据块尽量散布在各个节点中,负载均衡。
3.读取数据流程:客户端要访问HDFS中的文件,首先从NameNode获取组成这个文件的数据块位置列表,根据数据块位置列表,知道存储数据块的DataNode,访问DataNode获取数据,NameNode并不参与数据实际传输。
3.HDFS分布式文件系统的可靠性
- 副本冗余:在hdfs-site.xml中可以设置副本的数量,DataNode启动时,首先会遍历本地的文件系统,产生一份hdfs数据块和本地文件的对应关系列表(blockreport)汇报给namenode。
- 机架策略:通过“机架感知”,将数据块副本存储在不同的机架中。
- 心跳机制:NameNode周期性的从datanode接受心跳信号和块报告。根据块报告验证元数据,副本数量、磁盘错误、节点宕机。
- 安全模式:NameNode启动时会经过“安全模式”阶段,安全模式不会产生数据写。可以通过命令强制集群进入安全模式。
- 校验和:文件创立的时候,每个文件都会产生校验和,校验和会作为一个隐藏文件保存在命名空间下,客户端获取数据时可以检查校验和是否相同,从而法相数据块是否损坏。
- 回收站:HDFS提供回收站功能。
- 元数据保护:映像文件和事物日志是Namenode的核心数据。可以配置为拥有多个副本,副本会降低Name的处理速度,但是增加安全性。
- 快照
4.HDFS文件操作(命令行操作和API调用的方式)
列出文件:hadoop dfs -ls 后可接上目录
文件上传:hadoop dfs -put 本地文件 hdfs目录
文件复制到本地:hadoop dfs -get
文件删除:hadoop dfs -rmr 目录或文件名
文件查看:hadoop dfs -cat 文件名
查看HDFS的基本统计信息:hadoop dfsasmin -report
进入/退出安全模式:hadoop dfsadmin -safemode enter/leave
5.增加节点
- 在新节点安装好hadoop
- 把namenode的有关配置文件复制到该节点
- 修改masters和slaves文件,增加该节点
- 设施ssh免密码进入该结点
- 单独启动该节点上的datanode和tasktracker(hadoop-daemon.sh start datanode/tasktracker)
- 运行start-balancer.sh进行负载均衡。
认识HDFS分布式文件系统的更多相关文章
- HDFS分布式文件系统资源管理器开发总结
HDFS,全称Hadoop分布式文件系统,作为Hadoop生态技术圈底层的关键技术之一,被设计成适合运行在通用硬件上的分布式文件系统.它和现有的分布式文件系统有很多共同点,但同时,它和其他的分布式 ...
- 通过Thrift访问HDFS分布式文件系统的性能瓶颈分析
通过Thrift访问HDFS分布式文件系统的性能瓶颈分析 引言 Hadoop提供的HDFS布式文件存储系统,提供了基于thrift的客户端访问支持,但是因为Thrift自身的访问特点,在高并发的访问情 ...
- Hadoop HDFS分布式文件系统 常用命令汇总
引言:我们维护hadoop系统的时候,必不可少需要对HDFS分布式文件系统做操作,例如拷贝一个文件/目录,查看HDFS文件系统目录下的内容,删除HDFS文件系统中的内容(文件/目录),还有HDFS管理 ...
- Hadoop基础-HDFS分布式文件系统的存储
Hadoop基础-HDFS分布式文件系统的存储 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HDFS数据块 1>.磁盘中的数据块 每个磁盘都有默认的数据块大小,这个磁盘 ...
- 1、HDFS分布式文件系统
1.HDFS分布式文件系统 分布式存储 分布式计算 2.hadoop hadoop含有四个模块,分别是 common. hdfs和yarn. common 公共模块. HDFS hadoop dist ...
- 我理解中的Hadoop HDFS分布式文件系统
一,什么是分布式文件系统,分布式文件系统能干什么 在学习一个文件系统时,首先我先想到的是,学习它能为我们提供什么样的服务,它的价值在哪里,为什么要去学它.以这样的方式去理解它之后在日后的深入学习中才能 ...
- 大数据基础总结---HDFS分布式文件系统
HDFS分布式文件系统 文件系统的基本概述 文件系统定义:文件系统是一种存储和组织计算机数据的方法,它使得对其访问和查找变得容易. 文件名:在文件系统中,文件名是用于定位存储位置. 元数据(Metad ...
- hdfs(分布式文件系统)优缺点
hdfs(分布式文件系统) 优点 支持超大文件 支持超大文件.超大文件在这里指的是几百M,几百GB,甚至几TB大小的文件.一般来说hadoop的文件系统会存储TB级别或者PB级别的数据.所以在企业的应 ...
- 【史上最全】Hadoop 核心 - HDFS 分布式文件系统详解(上万字建议收藏)
1. HDFS概述 Hadoop 分布式系统框架中,首要的基础功能就是文件系统,在 Hadoop 中使用 FileSystem 这个抽象类来表示我们的文件系统,这个抽象类下面有很多子实现类,究竟使用哪 ...
随机推荐
- nancy中的本地化
1 建立一个文件夹 ,名称可以任意 2 添加资源文件 比如 Text.resx 3 使用 <h3>"@Text.Text.Greeting"</h3> 其中 ...
- Postgres的TOAST技术
一.介绍 首先,Toast是一个名字缩写,全写是The OverSized Attribute Storage Technique,即超尺寸字段存储技术,顾名思义,是说超长字段在Postgres的一个 ...
- DMV--sys.dm_os_ring_buffers
DMV 'sys.dm_os_ring_buffers' 可以用来诊断数据库连接和数据库内存方面的问题,但MSDN上找不到相应的介绍,网上找到以下相关资料: 1>sys.dm_os_ring_b ...
- Solr相似度算法一:DefaultSimilarity(基于TF-IDF的默认相似度算法)
默认的similarity是基于TF/IDF 模块. 该 similarity有以下配置选项: discount_overlaps –确定是否重叠的标识(标记位置增量为0)都将被忽略在正常计算的时候. ...
- bootstrap-table简单使用
开发项目时总想着能不能有一款插件包含分页,查询等常用功能,后来发现了bootstrap-table 直接看代码和效果图 <!DOCTYPE html> <html lang=&quo ...
- 获取outlook联系人寻呼字段
这称不上一篇技术文. 这边记录解决一个问题的过程和感受.这种感觉每个搞IT的人或多或少都感受过,是程序人独有的快乐之一.只是大部分人没有将这种感觉记录下来.但是当你记录时,这种感觉也早已消失. 需求: ...
- Caffe任务池GPU模型图像识别
一开始我在网上找demo没有找到,在群里寻求帮助也没有得到结果,索性将网上的易语言模块反编译之后,提取出对应的dll以及代码,然后对照官方的c++代码,写出了下面的c#版本 /*** * @pName ...
- JS 面向对象详解
面向对象详解1 OO1.html <!DOCTYPE html> <html> <head> <meta charset="utf-8" ...
- iOS Keychain 跨应用
Keychain 可以用来持久保存一些信息.通常每个应用都有自己的 Keychain Access.但有时你会需要多个应用共用一些信息.这时需要创建 Keychain Access Group. Ke ...
- 【BZOJ2084】【洛谷P3501】[POI2010]ANT-Antisymmetry(Manache算法)
题意描述 原题: 一句话描述:对于一个0/1序列,求出其中异或意义下回文的子串数量. 题解 我们可以看出,这个其实是一个对于异或意义下的回文子串数量的统计,什么是异或意义下呢?平常,我们对回文的定义是 ...