Java HashMap 源代码分析
Java HashMap
jdk 1.8
Java8相对于java7来说HashMap变化比较大,在hash冲突严重的时候java7会退化为链表,Java8会退化为TreeMap
我们先来看一下类图:
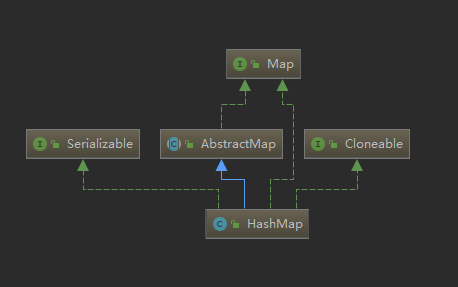
可见,HashMap继承了AbstractMap,但是Map并没有扩展Collection接口
我们先来看一下put方法
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
K,V分别是键值,首先对key执行hash方法,
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
首先取key的hashCode然后和hashcode右移16位(高位用0补全)然后进行异或
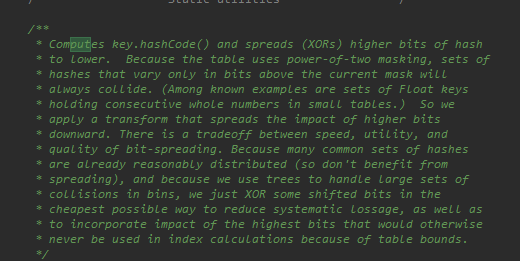
不用hashCode直接接返回的原因在这,我在下面的注释也稍微解释了一下
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//首先把table赋值给tab 检查是不是null 如果是null 那么初始化一下(resize)
//饭后返回table的长度给n
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//(n-1)&hash作为桶的标号
//我们知道桶的数量是 2^n
//2^n - 1 在二进制中表示就是全是1 按位与就比较平均的分配桶了
//但是为什么不直接用hashcode作为hash呢?
//由于使用桶数量-1作为掩码,那么注定高位的hashcode无法参与运算
//我们把高16位与低16使用xor运算,让高位参与hash,减少一定的冲突
//但是如果 桶的数量不是 2^n 那么这么做hash就不那么平均了
//在这里判断是不是有节点,如果没有,那么证明这里没有Hash冲突直接创建一个节点放这里就好了
if ((p = tab[i = (n - 1) & hash]) == null){
//在这里创建一个节点赋值给第i个桶
tab[i] = newNode(hash, key, value, null);
}
else {
//这里证明有Hash冲突了
Node<K,V> e; K k;
//判断当前的hash是不是相等,然后判断key相等
//因为key是个对象,相对来讲equals运算时间更长,先比较hash,如果不相等就不用equals比较了
//如果是相同的键,那么赋值给一个临时引用,先不覆盖
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//这里判断当前桶里的头结点是不是TreeNode,如果是TreeNode,那就把这个节点插到红黑树里面
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//如果不是Tree节点,那么说明现在还是个链表
//开始遍历
for (int binCount = 0; ; ++binCount) {
//判断是不是尾节点
if ((e = p.next) == null) {
//是尾节点那就直接插后面
p.next = newNode(hash, key, value, null);
//判断链表多长
//如果超过阈值,那就把链表变成二叉树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//hash相等之后在进行equals判断如果相等,证明这个已经key已经存在了break
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//e是key所在的节点如果是null那么证明是新插的,否则覆盖引用
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
//如果旧值是null或onlyIfAbsent==0那么覆盖值然后直接返回就可以了
//因为并没有改变table结构或者链表什么的
e.value = value;
//这个是空的,需要子类覆盖一下
//但是绝不能改变table结构什么的
afterNodeAccess(e);
return oldValue;
}
}
//更改迭代器
++modCount;
//大于阈值 扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
先看一下注释
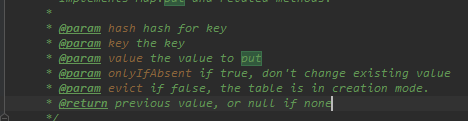
第一个值是key 哈希之后的值,第二个是key 第三个 是value 第四个就是是否覆盖原来存在的值,第五个是当前表是不是正在处于创建状态(false表示不是create)
看一下resize 操作
实际上就是扩容,解释写在注释里面了
/**
* Initializes or doubles table size. If null, allocates in
* accord with initial capacity target held in field threshold.
* Otherwise, because we are using power-of-two expansion, the
* elements from each bin must either stay at same index, or move
* with a power of two offset in the new table.
*
* @return the table
*/
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
//如果是null那么说明是新创建的
//下面的几个变量,Cap桶容量,Thr阈值
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
//先判断旧桶有没有
if (oldCap > 0) {
//如果旧的长度大于最大阈值,那么把桶扩大到最大Integer.MAX,然后不会发生resize了
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
//桶容量*2如果比最大容量小以及旧的大于默认桶容量
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
//旧的没桶数量 但是有阈值 说明第一次创建
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
//没有阈值,没有旧桶容量,说明默认初始化的
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
//新阈值 为0 说明需要计算阈值
float ft = (float)newCap * loadFactor;
//cap*factor但是如果太大,那么就扩大到Integer.MAX_VALUE
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
//按照计算好的桶的数量扩容
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
//把旧的桶所有东西放在新桶里面
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
//先清空旧的桶那个位置
oldTab[j] = null;
//如果只有一个元素 直接放在新桶对应的位置
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
//如果是树节点
else if (e instanceof TreeNode)
//对应的放在新桶里面
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
//链表节点 遍历,然后对应的放新桶里面
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
//开始遍历链表
do {
next = e.next;
//这里挺有意思的
//判断 oldCap那个位置是0还是1
//如果是0 那么扩容后不变
//如果是1 那么扩容后桶是原来位置+原来桶的数量
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
//对应的链表放进去就行
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
红黑树那部分先不看了
可以参考一下这个,里面有图很好理解:
https://www.cnblogs.com/mzc-blogs/p/5800084.html
Java HashMap 源代码分析的更多相关文章
- Android系统进程间通信Binder机制在应用程序框架层的Java接口源代码分析
文章转载至CSDN社区罗升阳的安卓之旅,原文地址:http://blog.csdn.net/luoshengyang/article/details/6642463 在前面几篇文章中,我们详细介绍了A ...
- java TreeMap 源代码分析 平衡二叉树
TreeMap 的实现就是红黑树数据结构,也就说是一棵自平衡的排序二叉树,这样就可以保证当需要快速检索指定节点. TreeSet 和 TreeMap 的关系 为了让大家了解 TreeMap 和 Tre ...
- Java ThreadLocal 源代码分析
Java ThreadLocal 之前在写SSM项目的时候使用过一个叫PageHelper的插件 可以自动完成分页而不用手动写SQL limit 用起来大概是这样的 最开始的时候觉得很困惑,因为直接使 ...
- Java ConcurrentHashMap 源代码分析
Java ConcurrentHashMap jdk1.8 之前用到过这个,但是一直不清楚原理,今天抽空看了一下代码 但是由于我一直在使用java8,试了半天,暂时还没复现过put死循环的bug 查了 ...
- Java ArrayList 源代码分析
Java ArrayList 之前曾经参考 数据结构与算法这本书写过ArrayList的demo,本来以为实现起来都差不多,今天抽空看了下jdk中的ArrayList的实现,差距还是很大啊 首先看一下 ...
- Android应用程序进程启动过程的源代码分析
文章转载至CSDN社区罗升阳的安卓之旅,原文地址: http://blog.csdn.net/luoshengyang/article/details/6747696 Android 应用程序框架层创 ...
- Java集合源代码剖析(二)【HashMap、Hashtable】
HashMap源代码剖析 ; // 最大容量(必须是2的幂且小于2的30次方.传入容量过大将被这个值替换) static final int MAXIMUM_CAPACITY = 1 << ...
- Java设计模式-代理模式之动态代理(附源代码分析)
Java设计模式-代理模式之动态代理(附源代码分析) 动态代理概念及类图 上一篇中介绍了静态代理,动态代理跟静态代理一个最大的差别就是:动态代理是在执行时刻动态的创建出代理类及其对象. 上篇中的静态代 ...
- 【Java集合源代码剖析】HashMap源代码剖析
转载请注明出处:http://blog.csdn.net/ns_code/article/details/36034955 您好,我正在參加CSDN博文大赛,假设您喜欢我的文章.希望您能帮我投一票.谢 ...
随机推荐
- Sybase常用时间日期函数
Sybase日期函数日期函数getdate()得到当前时间,可以设置得到各种时间格式.datepart(日期部分,日期)取指定时间的某一个部分,年月天时分秒.datediff(日期部分,日期1,日期2 ...
- Win10笔记本显卡驱动更新升级
对于游戏玩家来说,对显卡的关注度要高于电脑其它硬件,一般来说,显卡越好,游戏性能往往越强.不过要持续发挥显卡的最佳游戏性能,经常更新显卡驱动也是很有必要的.那么笔记本显卡驱动怎么更新?下面小编以自己的 ...
- ab 压测工具使用
转自:http://www.cnblogs.com/lemtree/articles/1676641.html 就是APACHE自带的测试工具AB(apache benchmark).在APACHE的 ...
- Manjaro 更新vim插件或者系统后 YCM失效
manjaro 更新之后,ycm总会多少有些毛病: 第一次遇到的问题: PluginUpdate之后ycm失效.使用命令:YcmToggleLogs查看ycmd_39047_stderr_Pp1GpB ...
- Android App 注射&&Drozer Use
x01 准备工作 测试环境: 1) 手机root权限 2) Adb.exe 3) 手机usb连接开启debug模式(在设置>关于手机>连续点击多次版本号,即可开启开发者模式) 4) Win ...
- 8、Node.js Buffer(缓冲区)
内容:Buffer与字符编码,Buffer创建.写入.读取.转换成JSON对象.合并.比较.拷贝.裁剪.长度 Buffer 与字符编码Buffer 实例一般用于表示编码字符的序列,比如 UTF-8 . ...
- Debian 静态网络配置
allow-hotplug enp6s0 iface enp6s0 inet static address gateway 192.168.2.1 # dns-* options are implem ...
- Linux的ssh的known_host文件
在平时工作中,有时候需要SSH登陆到别的Linux主机上去,但有时候SSH登陆会被禁止,并弹出如下类似提示: WARNING: REMOTE HOST IDENTIFICATION HAS CHANG ...
- centos7源码安装vim8.0
centos 6和7通过yum安装的vim版本仍为7.4,若想尝鲜,可获取源码包编译安装. 准备工作 1.检查vim旧版本,若已存在,将其卸载. $ vim$ yum remove vim* -y 2 ...
- luogu P3381【模板】最小费用最大流
嘟嘟嘟 没错,我开始学费用流了! 做法也是比较朴素的\(spfa\). 就是每一次以费用为权值跑一遍\(spfa\)找到一条最短路,然后把这条道全流满,并把这一次的流量和费用累加到答案上.因此我们需要 ...