3.4 目录和spooling
文件管理部分主要讲文件目录.文件目录它是用于检索文件的.文件目录它是一种文件系统实现按0存取的一种重要手段.一个文件目录它由若干个目录项组成的.每一个目录项它记录了一个文件的相关信息.这个文件信息指明了文件的文件名,文件类型,文件的物理信息,存储的相关的位置,包括建立日期啊相关的一些属性.所以通过对文件的目录项进行分析,就可以得到文件的一些常用的信息.
文件目录有三种目录结构形式.一级目录有一个很大的问题,就是文件名它不能够同名.因为只有一个目录,一个目录如果有多个用户在使用它,用户有自己的取名的习惯,那么很有可能它就会有文件名相同的.一级目录只有一个目录,那么它就不允许存在文件名同名.所以这种形式的目录结构只适用于单用户的系统.
第二种是二级目录结构.二级目录结构它分了两级,第一级的就是主文件目录,主文件目录有很多目录项,这个目录项是按用户来分配的.二级目录把每一个用户分配了一个目录,这些目录之间就可以存在同名了.在不同的目录允许有同名的现象.
windows和doc系统都是使用的是树型目录结构.树型目录结构可以分很多级了.


在树型的目录结构当中,任何一个文件或者是目录,它的路径表示法有两种:一种表示法是绝对路径表示法.绝对路径表示法是指的从根目录开始,逐级的标出这个路径来.从根目录到每一个目录、每一个文件它都有唯一的一条路径.这一条路径就是绝对路径.当前目录底下我们可以直接访问里面的文件.也就是说有一个相对路径,相对路径它是从当前目录开始写这个目录结构的.相对路径的提出使得这个结构变得简化了.W1/f1是相对路径.
二级目录讲过在不同的目录底下我们是允许有同样名字的文件的,但是相同目录底下是不允许有同名的.树型目录结构相当于是二级目录的扩充,每一个用户目录它可以根据自己的情况创建任何名字的一个文件.如果用户D2他创建了一个f2文件是用于存储email地址的一个列表,而D1用户他存储的这个f2不是这个含义,他是存的他的重要资料的一个目录.
方式1采用的是一个相对路径,方式2采用的是一个绝对路径.相对路径和绝对路径它的一个最大区别就是一个必须要从根目录开始一级一级往下找,另外一个就从当前目录往下找就可以了.很明显从当前目录往下面找它要找的这个范围就小了很多.范围小了它的效率也就高了,所以说方式1之所以效率高,是因为它可以从当前路径开始查找所需要的文件.
C选项提到方式1只需要访问1次磁盘,那么实际情况并不是这样子.前面提过目录项里面是存了一个文件的大致信息,它这些信息包括了它的修改时间、创建时间、作者、文件的性质、文件的扩展名等等等等,还包括一个重要东西:文件的起始地址.所以从这个意义上来讲,存储一个文件是把它拆分成了两个部分,一个是目录项,记录了大致的信息,这个是存放在目录表里面的,目录文件里面的.然后就是具体的文件的内容,是存在另外一块空间的.而根据这个目录项我们就可以找到这块空间.所以要访问/打开这个f1,它就要两次访问这个磁盘.第1次是找到/访问这个目录项,把这个目录项的内容找出来,然后取出它目录项里面记录的文件的真实首地址,就把这个文件全部都读出来.所以它要经历两次读取磁盘.所以C和D都是错误的.

Spooling技术
属于设备管理的内容.缓冲的机制.假脱机技术.理解SPOOLING靠技术的含义.
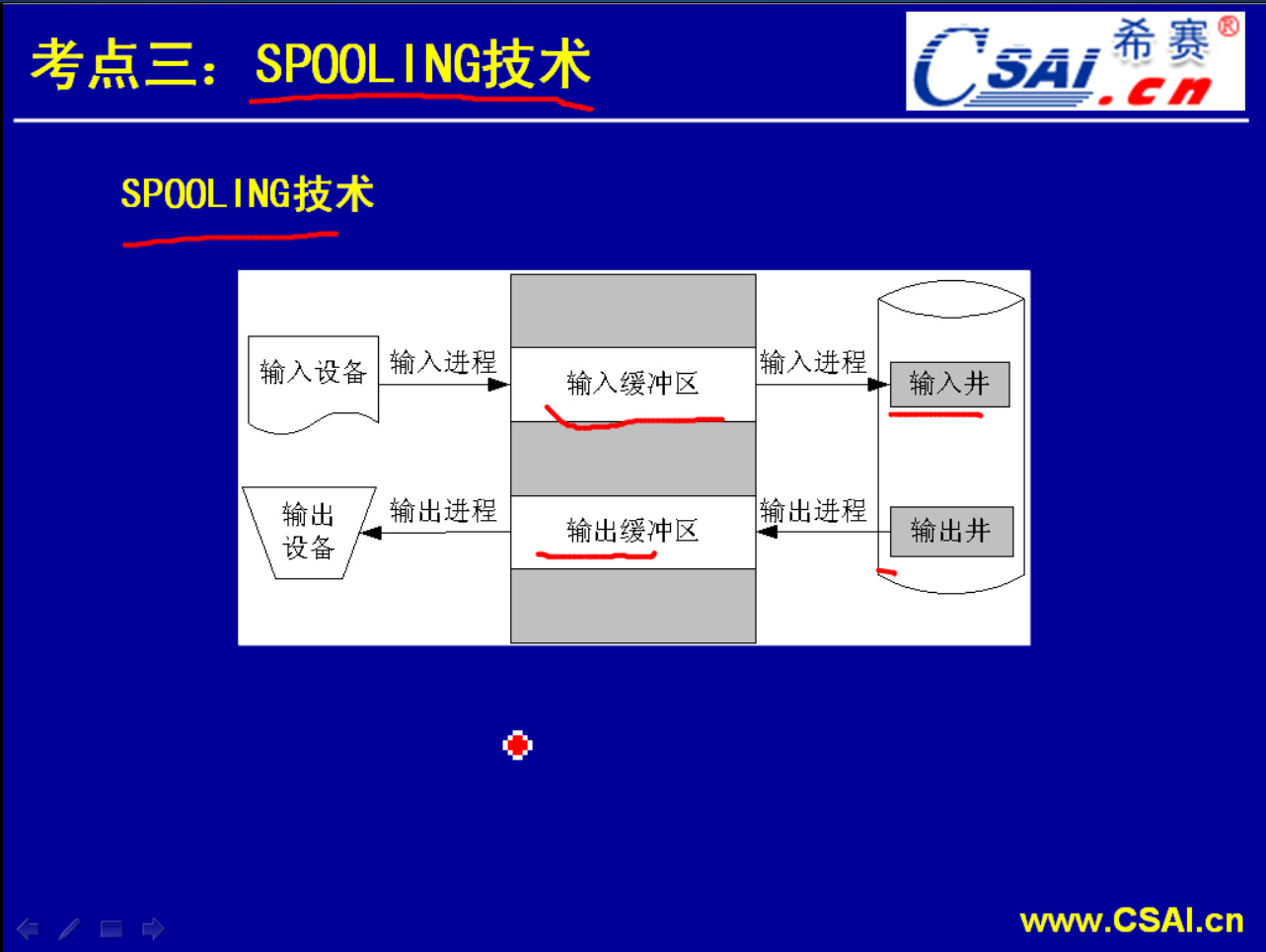
因为打印机是独占设备,它不能够同时几个人打印.关键问题是我们现在不晓得A要用多久,是1分钟呢还是1个小时呢还是10个小时呢?这样B、C、D要做的工作是隔一会儿就提交一次打印,结果就会发现失败.打印机仅仅会告诉你提交失败,现在有人在用这个资源但是它不会告诉你你什么时候申请能够得到资源.这种状态就比较麻烦了,B、C、D老是在尝试但是老是无法完成它的工作.是不是有一种方案我提交之后我就不管了,打印完之后我去拿就可以了呢?这就是SPOOLING技术的想法了.也就是说它们提交作业A、B、C、D并不是直接提交给打印机,而是提交给虚拟打印机,这个虚拟打印机是缓冲池/输入井,它们提交的内容会一条一条的记录在这个缓冲区当中,然后由缓冲区给打印机派发任务,这样子即使A、B、C、D四个人同时提交打印,也不会发生冲突因为你的信息会暂时放在缓冲区当中,逐个的提交给这个打印机.打印机会逐个的完成这些打印任务.然后A、B、C、D直接隔一段时间去取就可以了.而不要老是反复地去提交而提交又失败.这种形式就被称为SPOOLING技术.

3.4 目录和spooling的更多相关文章
- flume 前世今生
Cloudera 开发的分布式日志收集系统 Flume,是 hadoop 周边组件之一.其可以实时的将分布在不同节点.机器上的日志收集到不同的存储系统.Flume 初始的发行版本目前被统称为 Flum ...
- 分布式日志收集收集系统:Flume(转)
Flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统.支持在系统中定制各类数据发送方,用于收集数据:同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力.Fl ...
- FLUME NG的基本架构
Flume简介 Flume 是一个cloudera提供的 高可用高可靠,分布式的海量日志收集聚合传输系统.原名是 Flume OG (original generation),但随着 FLume 功能 ...
- Nginx日志通过Flume导入到HDFS中
关注公众号:分享电脑学习回复"百度云盘" 可以免费获取所有学习文档的代码(不定期更新) flume上传到hdfs: 当我们的数据量比较大时,比如每天的日志文件达到5G以上 使用ha ...
- Flume-ng-1.4.0 spooling source的方式增加了对目录的递归检测的支持
因为flume的spooldir不支持子目录文件的递归检测,并且业务需要,所以修改了源码,重新编译 代码修改参考自:http://blog.csdn.net/yangbutao/article/det ...
- 把Flume的Source设置为 Spooling directory source
把Flume的Source设置为 Spooling directory source,在设定的目录下放置需要读取的文件,一些文件在读取过程中会报错. 文件格式和报错如下: 实验一 读取汉子和“:&qu ...
- 带你看懂大数据采集引擎之Flume&采集目录中的日志
一.Flume的介绍: Flume由Cloudera公司开发,是一种提供高可用.高可靠.分布式海量日志采集.聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于采集数据:同时,flum ...
- 1.8-1.10 大数据仓库的数据收集架构及监控日志目录日志数据,实时抽取之hdfs系统上
一.数据仓库架构 二.flume收集数据存储到hdfs 文档:http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html#hd ...
- Flume-Spooling Directory Source 监控目录下多个新文件
使用 Flume 监听整个目录的文件,并上传至 HDFS. 一.创建配置文件 flume-dir-hdfs.conf https://flume.apache.org/FlumeUserGuide.h ...
随机推荐
- STL源码分析之第二级配置器
前言 第一级是直接调用malloc分配空间, 调用free释放空间, 第二级三就是建立一个内存池, 小于128字节的申请都直接在内存池申请, 不直接调用malloc和free. 本节分析第二级空间配置 ...
- NFV
转载: NFV介绍定义:NFV,即网络功能虚拟化,Network Function Virtualization.通过使用x86等通用性硬件以及虚拟化技术,来承载很多功能的软件处理.从而降低网络昂贵的 ...
- 洛谷 2574 XOR的艺术
[题解] 线段树维护区间中1的个数就好了.每次修改就打上标记并把区间的sum改为len-sum. #include<cstdio> #include<algorithm> #i ...
- STM32 实现 4*4 矩阵键盘扫描(HAL库、标准库 都适用)
本文实现的代码是基于STM32HAL库的基础上的,不过标准库也可以用,只是调用的库函数不同,逻辑跟配置是一样的,按我这里的逻辑来配置即可. 1.键盘原理图: 原理举例:先把 F0-F7 内部拉高,这样 ...
- 处理回车提交、ctrl+enter和shift+enter都不提交->textarea正常换行
<input type="textarea" @on-keypress="handlerMultiEnter"> handlerMultiEnter ...
- 在此计算机中仅有部分visual studio2010产品已升级到SP1,只有全部升级,产品才能正常运行
先说废话: 本人机子刚装系统Win10 专业版 1709 开始安装vs2010的时候中途报错了,有一个什么驱动不兼容,被我给关闭了,继续安装完,然后找不到vs的启动快捷方式,开始里面没有,于是我开始修 ...
- 【Codeforces 364A】Matrix
[链接] 我是链接,点我呀:) [题意] 让你求出b[i][j]=s[i]*s[j]规则构成的矩阵 的所有子矩阵中子矩阵的和为a的子矩阵的个数 [题解] (x,y,z,t) 会发现它的和就是sum(x ...
- 【转】建立一个更高级别的查询 API:正确使用Django ORM 的方式
这个就比较深入啦... http://www.oschina.net/translate/higher-level-query-api-django-orm 结论: 在视图和其他高级应用中使用源生的O ...
- J - A Bug's Life 并查集
Background Professor Hopper is researching the sexual behavior of a rare species of bugs. He assumes ...
- PageUtil ,简单的分页工具
public class PageUtil { private int totalCount;//总数 private int pageSize=10;//每页显示数量 private int cur ...