【机器学习算法-python实现】协同过滤(cf)的三种方法实现
(转载请注明出处:http://blog.csdn.net/buptgshengod)
1.背景
icf指的是item collaborative filtering,是将商品进行分析推荐。同理ucf的u指的是user,他是找出知趣类似的人,进行推荐。
通常来讲icf的准确率可能会高一些。通过这次參加天猫大数据比赛。我认为仅仅有在数据量很庞大的时候才适合用cf,假设数据量很小。cf的准确率会很可怜。
博主在比赛s1阶段,大概仅仅有几万条数据的时候,尝试了icf,准确率不到百分之中的一个。
。。
。。
2.经常用法

(1)欧氏距离法
数值越小。表示类似的越高。
def OsDistance(vector1, vector2):
sqDiffVector = vector1-vector2
sqDiffVector=sqDiffVector**2
sqDistances = sqDiffVector.sum()
distance = sqDistances**0.5
return distance
(2)皮尔逊相关系数
两个变量之间的相关系数越高。从一个变量去预測还有一个变量的准确度就越高,这是由于相关系数越高,就意味着这两个变量的共变部分越多,所以从当中一个变量的变化就可越多地获知还有一个变量的变化。
假设两个变量之间的相关系数为1或-1,那么你全然可由变量X去获知变量Y的值。
· 当相关系数为0时。X和Y两变量无关系。
· 当X的值增大。Y也增大。正相关关系,相关系数在0.00与1.00之间
· 当X的值减小,Y也减小,正相关关系。相关系数在0.00与1.00之间
· 当X的值增大。Y减小,负相关关系。相关系数在-1.00与0.00之间
当X的值减小。Y增大,负相关关系,相关系数在-1.00与0.00之间
相关系数的绝对值越大。相关性越强,相关系数越接近于1和-1,相关度越强,相关系数越接近于0,相关度越弱。

在python中用函数corrcoef实现。详细方法见http://infosec.pku.edu.cn/~dulz/doc/Numpy_Example_List.htm
(3)余弦类似度
0度角的余弦值是1,而其它不论什么角度的
在比較过程中。向量的规模大小不予考虑,仅仅考虑到向量的指向方向。余弦相
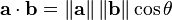
def cosSim(inA,inB):
num = float(inA.T*inB)
denom = la.norm(inA)*la.norm(inB)
return 0.5+0.5*(num/denom)
【机器学习算法-python实现】协同过滤(cf)的三种方法实现的更多相关文章
- python每次处理一个字符的三种方法
python每次处理一个字符的三种方法 a_string = "abccdea" print 'the first' for c in a_string: print ord(c) ...
- Python 文件行数读取的三种方法
Python三种文件行数读取的方法: #文件比较小 count = len(open(r"d:\lines_test.txt",'rU').readlines()) print c ...
- Python 判断文件是否存在的三种方法
通常在读写文件之前,需要判断文件或目录是否存在,不然某些处理方法可能会使程序出错.所以最好在做任何操作之前,先判断文件是否存在. 这里将介绍三种判断文件或文件夹是否存在的方法,分别使用os模块.Try ...
- python webdriver api-上传文件的三种方法
上传文件: 第一种方式,sendkeys(),最简单的 #encoding=utf-8 from selenium import webdriver import unittest import ti ...
- Python 中删除列表元素的三种方法
列表基本上是 Python 中最常用的数据结构之一了,并且删除操作也是经常使用的. 那到底有哪些方法可以删除列表中的元素呢?这篇文章就来总结一下. 一共有三种方法,分别是 remove,pop 和 d ...
- python列表删除重复元素的三种方法
给定一个列表,要求删除列表中重复元素. listA = ['python','语','言','是','一','门','动','态','语','言'] 方法1,对列表调用排序,从末尾依次比较相邻两个元素 ...
- 用Python获取Linux资源信息的三种方法
方法一:psutil模块 #!usr/bin/env python # -*- coding: utf-8 -*- import socket import psutil class NodeReso ...
- Python判断文件是否存在的三种方法
通常在读写文件之前,需要判断文件或目录是否存在,不然某些处理方法可能会使程序出错.所以最好在做任何操作之前,先判断文件是否存在. 这里将介绍三种判断文件或文件夹是否存在的方法,分别使用os模块.Try ...
- Python判断文件是否存在的三种方法【转】
转:http://www.cnblogs.com/jhao/p/7243043.html 通常在读写文件之前,需要判断文件或目录是否存在,不然某些处理方法可能会使程序出错.所以最好在做任何操作之前,先 ...
- python删除list中元素的三种方法
a.pop(index):删除列表a中index处的值,并且返回这个值. del(a[index]):删除列表a中index处的值,无返回值. del中的index可以是切片,所以可以实现批量删除. ...
随机推荐
- SVN 如何提交 SO 库文件
今天提交代码时候发现,svn add 还是 svn st 均查看不到想要提交的 so 文件. 后来才知道原来是配置文件出了问题,把so文件的提交给屏蔽掉了. 修改步骤如下: 1.Ubuntu 系统,点 ...
- GIL 线程/进程池 同步异步
GIL 什么是GIL 全局解释器锁,本质是一把互斥锁,是加在cpython解释器上的一把锁, 同一个进程内的所有线程需要先抢到GIL锁,才能执行python代码 为什么要有GIL cpython解释器 ...
- Objective-C 正则表达式使用(1)
学习了一下OC的正则表达式备忘一下 使用正则表达式的步骤: 创建一个一个正则表达式对象:定义规则. 利用正则表达式对象测试,相应的字符串. NSString *userName = @"12 ...
- raywenderlich.com Objective-C编码规范
原文链接 : The official raywenderlich.com Objective-C style guide 原文作者 : raywenderlich.com Team 译文出自 : r ...
- bluej
他山之石,可以攻玉!吾辈之道,披荆斩棘! 个人源码地址: https://gitee.com/blue_phantom
- hdu2087
#include <stdio.h> #include <string.h> int main(){ int cnt,i,j,k; +],tmp[+]; int strl,tm ...
- z作业二总结
这是我的第二次作业,之前在课上所学的我发现已经忘得差不多了,这次的作业让我做的非常累,感觉整个人生都不太好了. 作业中的知识点:int(整型) float(单精度) double(双精度) char( ...
- HackerRank# Fibonacci Modified
原题地址 竟然64位都要爆,这是要大整数乘法的节奏吗?我才不要写大整数乘法呢,用Ruby干掉 代码: # Enter your code here. Read input from STDIN. Pr ...
- 算法复习——差分约束(ssoi种树)
题目: 题目描述 为了绿化乡村,H 村积极响应号召,开始种树了. H 村里有 n 幢房屋,这些屋子的排列顺序很有特点,在一条直线上.于是方便起见,我们给它们标上 1-n .树就种在房子前面的空地上. ...
- ftp链接、上传、下载、断开
开发环境:Jdk 1.8 引入第三方库:commons-net-2.2.jar(针对第一种方法) 一.基于第三方库FtpClient的FTP服务器数据传输 由于是基于第三方库,所以这里基本上没有太多要 ...