大数据学习——java操作hdfs环境搭建以及环境测试
1 新建一个maven项目
打印根目录下的文件的名字
添加pom依赖
pom.xml
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>com.cyf</groupId>
<artifactId>hdfstest</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>war</packaging> <name>hdfstest Maven Webapp</name>
<!-- FIXME change it to the project's website -->
<url>http://www.example.com</url> <properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.9</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.4</version>
</dependency>
</dependencies>
</project>
2 测试
TestHDFS.java
package cn.itcast.hdfs; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator; public class TestHDFS {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
//1首先需要一个hdfs的客户端对象
conf.set("fs.defaultFS", "hdfs://mini1:9000");
FileSystem fs = FileSystem.get(conf);
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), false);
//通过迭代器可以遍历出我们hdfs文件系统的根目录下的文件
while (listFiles.hasNext()) {
LocatedFileStatus fileStatus = listFiles.next();
Path path = fileStatus.getPath(); String fileName = path.getName();
System.out.println(fileName);
} }
}
运行结果如下图


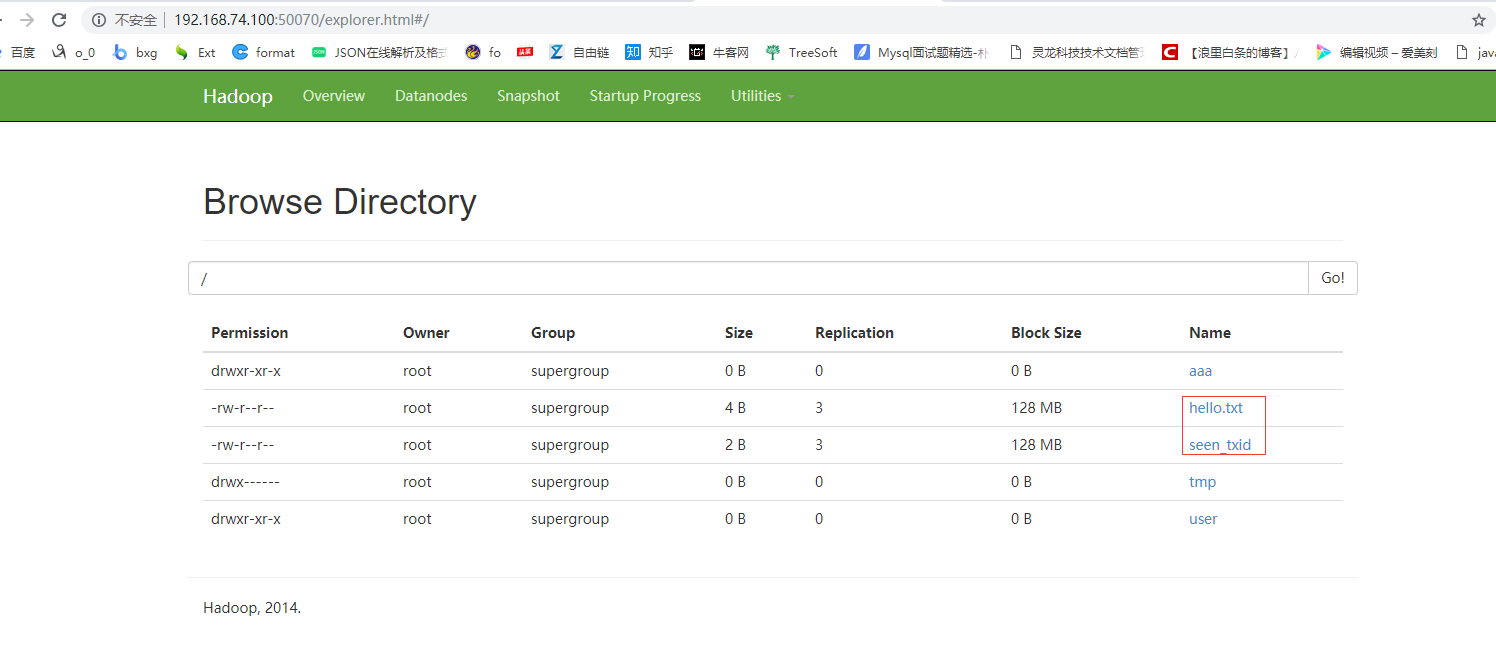
大数据学习——java操作hdfs环境搭建以及环境测试的更多相关文章
- 大数据学习之路-hdfs
1.什么是hadoop hadoop中有3个核心组件: 分布式文件系统:HDFS —— 实现将文件分布式存储在很多的服务器上 分布式运算编程框架:MAPREDUCE —— 实现在很多机器上分布式并行运 ...
- 大数据学习——kafka+storm+hdfs整合
1 需求 kafka,storm,hdfs整合是流式数据常用的一套框架组合,现在 根据需求使用代码实现该需求 需求:应用所学技术实现,kafka接收随机句子,对接到storm中:使用storm集群统计 ...
- 大数据学习——hadoop2.x集群搭建
1.准备Linux环境 1.0先将虚拟机的网络模式选为NAT 1.1修改主机名 vi /etc/sysconfig/network NETWORKING=yes HOSTNAME=itcast ### ...
- 大数据学习——JAVA采集程序
1 需求 从外部购买数据,数据提供方会实时将数据推送到6台FTP服务器上,我方部署6台接口采集机来对接采集数据,并上传到HDFS中 提供商在FTP上生成数据的规则是以小时为单位建立文件夹(2016-0 ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据学习(16)—— HBase环境搭建和基本操作
部署规划 HBase全称叫Hadoop Database,它的数据存储在HDFS上.我们的实验环境依然基于上个主题Hive的配置,参考大数据学习(11)-- Hive元数据服务模式搭建. 在此基础上, ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据学习笔记——Hadoop编程实战之HDFS
HDFS基本API的应用(包含IDEA的基本设置) 在上一篇博客中,本人详细地整理了如何从0搭建一个HA模式下的分布式Hadoop平台,那么,在上一篇的基础上,我们终于可以进行编程实操了,同样,在编程 ...
随机推荐
- Codeforces Round #542(Div. 2) D1.Toy Train
链接:https://codeforces.com/contest/1130/problem/D1 题意: 给n个车站练成圈,给m个糖果,在车站上,要被运往某个位置,每到一个车站只能装一个糖果. 求从 ...
- 外文翻译 《How we decide》多巴胺的预言 第三节
这是第二章的最后一节. 书的导言 本章第一节 本章第二节 本节阅读感言:自我批评是自我提升的妙方. 多巴胺是我们感情的源泉.多巴胺相关的神经系统在不断的记录着我们主观意识没有注意到的一个个模式,将它们 ...
- 23中java设计模式(1)-- 策略模式
近来不太忙,就打算抽空看下源码补充一下知识,当我看了之后我发现看源码的关键是要弄清楚类之家的关系以及为何要这样的关系,否则如果只看具体的代码那不如去学习会儿算法. 于是就打算从设计模式入手,边学习边记 ...
- H+后台主题UI框架---整理(三)
这里面介绍下H+后台主题UI框架里面插件的应用,不过都是最最简单最初级的功能.主要有日历插件,input单选多选(icheck)插件,input下拉搜索(chosen)插件. 一.日历插件 有如下几种 ...
- 【学习笔记】深入理解js原型和闭包(6)——继承
为何用“继承”为标题,而不用“原型链”? 原型链如果解释清楚了很容易理解,不会与常用的java/C#产生混淆.而“继承”确实常用面向对象语言中最基本的概念,但是java中的继承与javascript中 ...
- Java String startsWith()方法
描述: 这个方法有两个变体并测试如果一个字符串开头的指定索引指定的前缀或在默认情况下从字符串开始位置. 语法 此方法定义的语法如下: public boolean startsWith(String ...
- 【Win32汇编】编译环境配置
开始学习[Win32汇编],编译过程较为繁琐,做个记录. 使用 MASM32 提供的 ml.exe 和 link.exe,以及 VS2013 中的 nmake.exe 和资源编辑器. ml.exe: ...
- SEO 第八章
SEO第八章 本次课目标: 1. 网站外部优化的外链优化 2. 网站流量分析 1. 什么叫做外链? 外链也叫反向链接,指的是从别的网站指向我自己的网站的链接. 2. 外链的作用? l 外链可 ...
- vscode 用户代码片段 vue初始化模板 Snippet #新加入开头注释 自动生成文件名 开发日期时间等内容
vue文件模板 模板变量 https://code.visualstudio.com/docs/editor/userdefinedsnippets#_variables vue.json { // ...
- Qt 之 QApplication
1.QApplication QApplication类管理GUI程序的控制流和主要设置,是基于QWidget的,为此特化了QGuiApplication的一些功能,处理QWidget特有的初始化和结 ...