大数据学习——java操作hdfs环境搭建以及环境测试
1 新建一个maven项目
打印根目录下的文件的名字
添加pom依赖
pom.xml
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>com.cyf</groupId>
<artifactId>hdfstest</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>war</packaging> <name>hdfstest Maven Webapp</name>
<!-- FIXME change it to the project's website -->
<url>http://www.example.com</url> <properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.9</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.4</version>
</dependency>
</dependencies>
</project>
2 测试
TestHDFS.java
package cn.itcast.hdfs; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator; public class TestHDFS {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
//1首先需要一个hdfs的客户端对象
conf.set("fs.defaultFS", "hdfs://mini1:9000");
FileSystem fs = FileSystem.get(conf);
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), false);
//通过迭代器可以遍历出我们hdfs文件系统的根目录下的文件
while (listFiles.hasNext()) {
LocatedFileStatus fileStatus = listFiles.next();
Path path = fileStatus.getPath(); String fileName = path.getName();
System.out.println(fileName);
} }
}
运行结果如下图


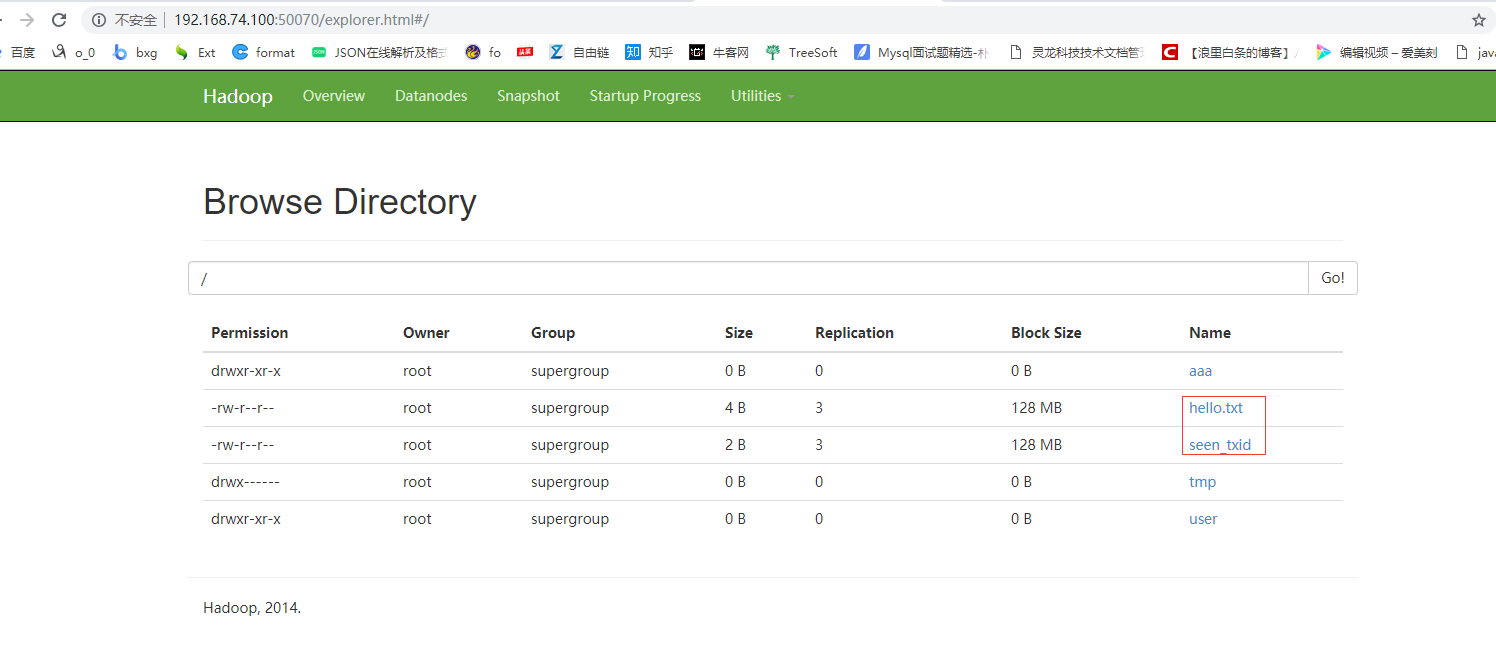
大数据学习——java操作hdfs环境搭建以及环境测试的更多相关文章
- 大数据学习之路-hdfs
1.什么是hadoop hadoop中有3个核心组件: 分布式文件系统:HDFS —— 实现将文件分布式存储在很多的服务器上 分布式运算编程框架:MAPREDUCE —— 实现在很多机器上分布式并行运 ...
- 大数据学习——kafka+storm+hdfs整合
1 需求 kafka,storm,hdfs整合是流式数据常用的一套框架组合,现在 根据需求使用代码实现该需求 需求:应用所学技术实现,kafka接收随机句子,对接到storm中:使用storm集群统计 ...
- 大数据学习——hadoop2.x集群搭建
1.准备Linux环境 1.0先将虚拟机的网络模式选为NAT 1.1修改主机名 vi /etc/sysconfig/network NETWORKING=yes HOSTNAME=itcast ### ...
- 大数据学习——JAVA采集程序
1 需求 从外部购买数据,数据提供方会实时将数据推送到6台FTP服务器上,我方部署6台接口采集机来对接采集数据,并上传到HDFS中 提供商在FTP上生成数据的规则是以小时为单位建立文件夹(2016-0 ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据学习(16)—— HBase环境搭建和基本操作
部署规划 HBase全称叫Hadoop Database,它的数据存储在HDFS上.我们的实验环境依然基于上个主题Hive的配置,参考大数据学习(11)-- Hive元数据服务模式搭建. 在此基础上, ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据学习笔记——Hadoop编程实战之HDFS
HDFS基本API的应用(包含IDEA的基本设置) 在上一篇博客中,本人详细地整理了如何从0搭建一个HA模式下的分布式Hadoop平台,那么,在上一篇的基础上,我们终于可以进行编程实操了,同样,在编程 ...
随机推荐
- hbuilder 中文乱码
这是因为HBuilder默认文件编码是UTF-8,你可以在工具-选项-常规-工作空间选项中设置默认字符编码
- Squid启动报:Could not determine this machines public hostname. Please configure one or set 'visible_hostname'.
在squid.conf中添加 visible_hostname squid.packet-pushers.net 或者编辑/etc/hosts文件, 在该文件中制定主机IP地址与主机名的对应.
- wamp无法进入phpMyAdmin或localhost的解决方法
我用的是最新版的wampsever5,在win7(64位)下安装正常使用,没有无法进入phpMyAdmin的问题,但是我在虚拟机安装了win8(64位专业版),测试在win8下面的使用情况时,就有问题 ...
- 【学习笔记】深入理解js原型和闭包(4)——隐式原型
注意:本文不是javascript基础教程,如果你没有接触过原型的基本知识,应该先去了解一下,推荐看<javascript高级程序设计(第三版)>第6章:面向对象的程序设计. 上节已经提到 ...
- redis安装(windows)
软件环境:由于redis只有linux版,而windows版是微软自己做的,最新版只到3.2.100(linux的版本已经到5.x) 1.1.1. redis安装 首先去官网下载安装包 得到的安装文 ...
- Java格式规范及注释的用法
/* 需求:演示一个Hello World的Java小程序 思路: 1.定义一个类.因为Java程序都是定义在类中,Java程序都是以类的形式存在的,类的形式其实就是字节码的最终体现 2.定义一个主函 ...
- Docker 启动时报错:iptables:No chain/target/match by the name
重新启动docker后,就好了. service docker restart
- 通过JS加载XML文件,跨浏览器兼容
引言 通过JS加载XML文件,跨多种浏览器兼容. 在Chrome中,没有load方法,需要特殊处理! 解决方案 部分代码 try //Internet Explorer { xmlDoc=new Ac ...
- String系列之replaceAll方法替换.
直接使用String类的replaceall方法的第一个参数并不是简单的字符串,而是一个正则表达式.在正则表达式中,英文点号(.)表示任意字符,所以你原先的写法会把所有字符都替换成空白. 转义使用所以 ...
- 【传智播客】Libevent学习笔记(三):事件循环
目录 00. 目录 01. event_base_loop函数 02. event_base_dispatch函数 03. event_base_loopexit函数 04. event_base_l ...