hadoop之一:概念和整体架构
什么是hadoop?
Apache Hadoop是一款支持数据密集型分布式应用并以Apache 2.0许可协议发布的开源软件框架。它支持在商品硬件构建的大型集群上运行的应用程序。Hadoop是根据Google公司发表的MapReduce和Google档案系统的论文自行实作而成。
Hadoop框架透明地为应用提供可靠性和数据移动。它实现了名为MapReduce的编程范式:应用程序被分割成许多小部分,而每个部分都能在集群中的任意节点上执行或重新执行。此外,Hadoop还提供了分布式文件系统,用以存储所有计算节点的数据,这为整个集群带来了非常高的带宽。MapReduce和分布式文件系统的设计,使得整个框架能够自动处理节点故障。它使应用程序与成千上万的独立计算的电脑和PB级的数据。
hadoop历史
Hadoop由 Apache Software Foundation 于 2005 年秋天作为Lucene的子项目Nutch的一部分正式引入。它受到最先由 Google Lab 开发的 Map/Reduce 和 Google File System(GFS) 的启发。
2006 年 3 月份,Map/Reduce 和 Nutch Distributed File System (NDFS) 分别被纳入称为 Hadoop 的项目中。Hadoop 是最受欢迎的在 Internet 上对搜索关键字进行内容分类的工具,但它也可以解决许多要求极大伸缩性的问题。例如,如果您要 grep 一个 10TB 的巨型文件,会出现什么情况?在传统的系统上,这将需要很长的时间。但是 Hadoop 在设计时就考虑到这些问题,采用并行执行机制,因此能大大提高效率。
- Hadoop Common:在0.20及以前的版本中,包含HDFS、MapReduce和其他项目公共内容,从0.21开始HDFS和MapReduce被分离为独立的子项目,其余内容为Hadoop Common
- HDFS:Hadoop分布式文件系统(Distributed File System)-HDFS(Hadoop Distributed File System)
- MapReduce:并行计算框架,0.20前使用org.apache.hadoop.mapred旧接口,0.20版本开始引入org.apache.hadoop.mapreduce的新API
- Apache HBase:分布式NoSQL列数据库,类似谷歌公司BigTable。
- Apache Hive:构建于hadoop之上的数据仓库,通过一种类SQL语言HiveQL为用户提供数据的归纳、查询和分析等功能。Hive最初由Facebook贡献。
- Apache Mahout:机器学习算法软件包。
- Apache Sqoop:结构化数据(如关系数据库)与Apache Hadoop之间的数据转换工具。
- Apache ZooKeeper:分布式锁设施,提供类似Google Chubby的功能,由Facebook贡献。
- Apache Avro:新的数据序列化格式与传输工具,将逐步取代Hadoop原有的IPC机制。
hadoop平台子项目
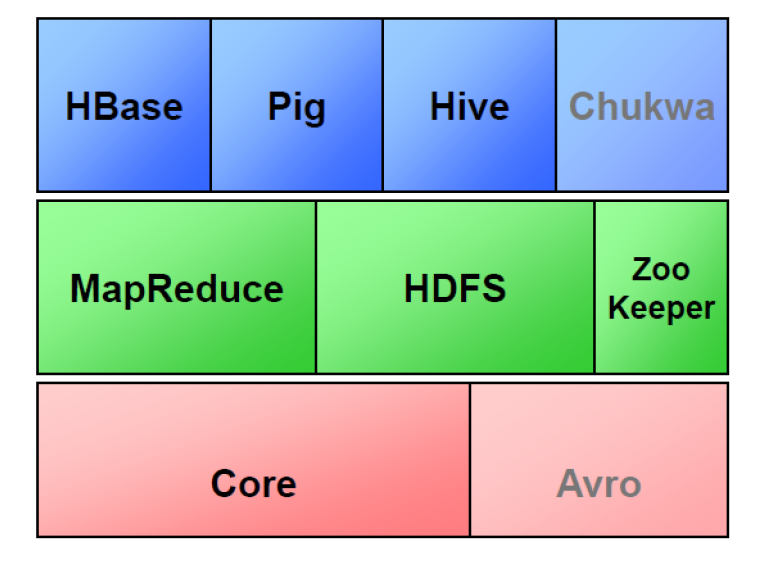
现在普遍认为整个Apache Hadoop“平台”包括Hadoop内核、MapReduce、Hadoop分布式文件系统(HDFS)以及一些相关项目,有Apache Hive和Apache HBase等等。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
如图,最下面一层就是hadoop的核心代码,核心代码之上实现了两个最核心的功能:MapReduce和HDFS,这是hadoop的两大支柱!因为hadoop是Java写的,为了方便其他对Java语言不熟悉的程序员,在这之上又有Pig,这是一个轻量级的语言,用户可以使用Pig用于数据分析和处理,系统会自动把它转化为MapReduce程序。
还有一个Hive,很重要!这是一个传统的SQL到MapReduce的映射器,面向传统的数据库工程师。但是不支持全部SQL。还有一个子项目叫HBase,一个非关系数据库,NoSQL数据库,数据是列存储的,提高响应速度,减少IO量,可以做成分布式集群。
ZooKeeper负责服务器节点和进程间的通信,是一个协调工具,因为Hadoop的几乎每个子项目都是用动物做logo,故这个协调软件叫动物园管理员。
Hadoop架构
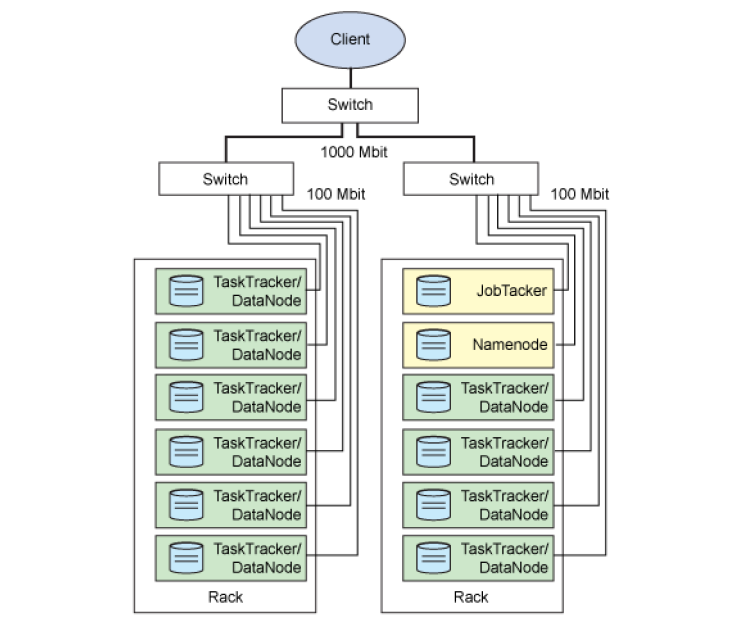
如图,两个服务器机柜,每个圆柱代表一个物理机,各个物理节点通过网线连接,连接到交换机,然后客户端通过互联网来访问。其中各个物理机上都运行着Hadoop的一些后台进程。
Namenode

也叫名称节点,是HDFS的守护程序(一个核心程序),对整个分布式文件系统进行总控制,会纪录所有的元数据分布存储的状态信息,比如文件是如何分割成数据块的,以及这些数据块被存储到哪些节点上,还有对内存和I/O进行集中管理,用户首先会访问Namenode,通过该总控节点获取文件分布的状态信息,找到文件分布到了哪些数据节点,然后在和这些节点打交道,把文件拿到。故这是一个核心节点。
不过这是个单点,发生故障将使集群崩溃。
Secondary Namenode
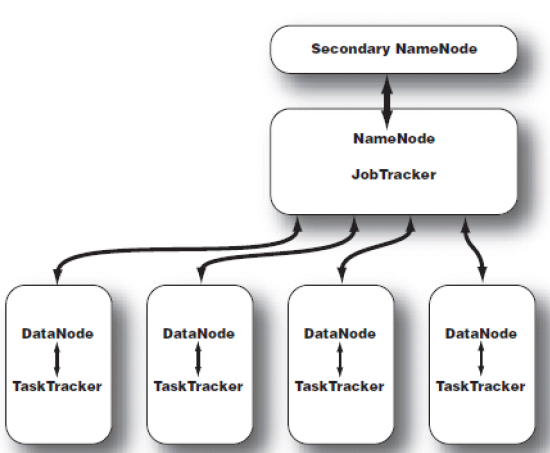
在Hadoop中,有一些命名不好的模块,Secondary NameNode是其中之一。从它的名字上看,它给人的感觉就像是NameNode的备份,比如有人叫它第二名称节点,仿佛给人感觉还有后续……但它实际上却不完全是。
最好翻译为辅助名称节点,或者检查点节点,它是监控HDFS状态的辅助后台程序,可以保存名称节点的副本,故每个集群都有一个,它与NameNode进行通讯,定期保存HDFS元数据快照。NameNode故障可以作为备用NameNode使用,目前还不能自动切换。但是功能绝不仅限于此。所谓后备也不是它的主要功能。后续详细解释。
DataNode

叫数据节点,每台从服务器节点都运行一个,负责把HDFS数据块读、写到本地文件系统。这三个东西组成了Hadoop平台其中一个支柱——HDFS体系。
再看另一个支柱——MapReduce,有两个后台进程。
JobTracker
叫作业跟踪器,运行到主节点(Namenode)上的一个很重要的进程,是MapReduce体系的调度器。用于处理作业(用户提交的代码)的后台程序,决定有哪些文件参与作业的处理,然后把作业切割成为一个个的小task,并把它们分配到所需要的数据所在的子节点。
Hadoop的原则就是就近运行,数据和程序要在同一个物理节点里,数据在哪里,程序就跑去哪里运行。这个工作是JobTracker做的,监控task,还会重启失败的task(于不同的节点),每个集群只有唯一一个JobTracker,类似单点的nn,位于Master节点(稍后解释Master节点和slave节点)。
TaskTracker
叫任务跟踪器,MapReduce体系的最后一个后台进程,位于每个slave节点上,与datanode结合(代码与数据一起的原则),管理各自节点上的task(由jobtracker分配),每个节点只有一个tasktracker,但一个tasktracker可以启动多个JVM,用于并行执行map或reduce任务,它与jobtracker交互通信,可以告知jobtracker子任务完成情况。
Master与Slave
Master节点:运行了Namenode、或者Secondary Namenode、或者Jobtracker的节点。还有浏览器(用于观看管理界面),等其它Hadoop工具。Master不是唯一的!
Slave节点:运行Tasktracker、Datanode的机器。
数据分析者面临的问题和Hadoop的思想
目前需要我们处理的数据日趋庞大,无论是入库和查询,都出现性能瓶颈,用户的应用和分析结果呈整合趋势,对实时性和响应时间要求越来越高。使用的模型越来越复杂,计算量指数级上升。
故,人们希望出现一种技术或者工具来解决性能瓶颈,在可见未来不容易出现新瓶颈,并且学习成本尽量低,使得过去所拥有的技能可以平稳过渡。比如SQL、R等,还有转移平台的成本能否控制最低,比如平台软硬件成本,再开发成本,技能再培养成本,维护成本等。
而Hadoop就能解决如上问题——分而治之,化繁为简。
hadoop之一:概念和整体架构的更多相关文章
- hadoop学习(一)----概念和整体架构
程序员就得不停地学习啊,故步自封不能满足公司的业务发展啊!所以我们要有搞事情的精神.都说现在是大数据的时代,可以我们这些码农还在java的业务世界里面转悠呢.好不容易碰到一个可能会用到大数据技术的场景 ...
- Hadoop学习笔记(1):概念和整体架构
Hadoop简介和历史 Hadoop架构体系 Master和Slave节点 数据分析面临的问题和Hadoop思想 由于工作原因,必须学习和深入一下Hadoop,特此记录笔记. 什么是hadoop? A ...
- ODI 系列学习--整体架构概念
ODI 系列学习--整体架构概念 ODI整体架构没有Oracle Database复杂,因为它属于程序功能的使用,更多是程序开发和配置的工作,当然ODI的优化涉及到很多数据库优化的工作,从整体架构入手 ...
- 基于Hadoop的大数据平台实施记——整体架构设计[转]
http://blog.csdn.net/jacktan/article/details/9200979 大数据的热度在持续的升温,继云计算之后大数据成为又一大众所追捧的新星.我们暂不去讨论大数据到底 ...
- 基于Hadoop的大数据平台实施记——整体架构设计
大数据的热度在持续的升温,继云计算之后大数据成为又一大众所追捧的新星.我们暂不去讨论大数据到底是否适用于您的组织,至少在互联网上已经被吹嘘成无所不能的超级战舰.好像一夜之间我们就从互联网时代跳跃进了大 ...
- 【Hadoop离线基础总结】流量日志分析网站整体架构模块开发
目录 数据仓库设计 维度建模概述 维度建模的三种模式 本项目中数据仓库的设计 ETL开发 创建ODS层数据表 导入ODS层数据 生成ODS层明细宽表 统计分析开发 流量分析 受访分析 访客visit分 ...
- 深度解读MRS IoTDB时序数据库的整体架构设计与实现
[本期推荐]华为云社区6月刊来了,新鲜出炉的Top10技术干货.重磅技术专题分享:还有毕业季闯关大挑战,华为云专家带你做好职业规划. 摘要:本文将会系统地为大家介绍MRS IoTDB的来龙去脉和功能特 ...
- jQuery 2.0.3 源码分析core - 整体架构
拜读一个开源框架,最想学到的就是设计的思想和实现的技巧. 废话不多说,jquery这么多年了分析都写烂了,老早以前就拜读过, 不过这几年都是做移动端,一直御用zepto, 最近抽出点时间把jquery ...
- [转]Android App整体架构设计的思考
1. 架构设计的目的 对程序进行架构设计的原因,归根到底是为了提高生产力.通过设计使程序模块化,做到模块内部的高聚合和模块之间的低耦合.这样做的好处是使得程序在开发的过程中,开发人员只需要专注于一点, ...
随机推荐
- php信号处理
pcntl pcntl_signal 信号注册函数 pcntl_alarm 指定秒数中断程序执行任务. 每次执行只会有一个定时器生效,若之前计时器还没结束就定义新定时器,会替代之前定时器并返回之前定时 ...
- centOS解决乱码问题
问题描述:输入javac出现乱码,部分字符不能显示解决方法 echo 'export LANG=en_US.UTF-8' >> ~/.bashrc
- Portal实现原理
https://blog.csdn.net/sukyle/article/details/6456930
- The Gray World Assumption
Color Constancy 色彩恒常性(2)The Gray World Assumption act=qbbkrzydb_20150408_01" style="line-h ...
- c 字符串 函数
c编辑 strcpy 原型:extern char *strcpy(char *dest,char *src); 用法:#include <string.h> 功能:把src所指由NUL结 ...
- PHP百分号转小数
<?php $a = "20.544545%"; echo (float)$a/100; ?>
- python 基础 1.3 使用pycharm给python传递参数及pycharm调试模式
一.通过pycharm 给python传递函数 1. 在pycharm终端中写入要获取的参数,进行获取 1>启动pycharm 中Terminal(终端) 窗口 点击pycharm左下角的图标, ...
- VS2013 自动添加头部注释 -C#开发
在团队开发中,头部注释是必不可少的.但在开发每次新建一个类都要复制一个注释模块也很不爽,所以得想个办法让开发工具自动生成我们所需要的模板.....操作方法如下: 方法/步骤 1 找你的vs安装目录, ...
- 九度OJ 1165:字符串匹配 (模式匹配)
时间限制:1 秒 内存限制:32 兆 特殊判题:否 提交:3219 解决:1149 题目描述: 读入数据string[ ],然后读入一个短字符串.要求查找string[ ]中和短字符串的所有匹配,输出 ...
- 【shell】awk引用外部变量
在使用awk的过程中,经常会需要引用外部变量,但是awk需要使用单引号将print包起来,导致print后的$引用无效,可以采用下面的方式 例如: #!/bin/bash a="line1 ...