[机器学习] 简单的机器学习算法和sklearn实现
机器学习基础算法理解和总结
KNN算法
理解
KNN其实是最好理解的算法之一,其实就是依次和空间中的每个点进行距离比较,取距离最近的N个点,看这N个点的类别,那么要判断的点的类别就是这N个点中类别占比最大的点的类别了(投票表决),这就是暴力的KNN方法。还有一种是通过构造kd树的方式实现。kd树算法并没有从一开始就去计算测试样本和训练样本之间的距离,而是先去训练构造一个kd树,然后用kd树对测试样本进行预测(平衡二叉树)。
实现步骤
对于分类问题,实现步骤为
- 不需要训练,需要提供超参数k
- 取样本空间D中离测试样本最近的k个点
- 投票决定测试样本的类别
对于回归问题,实现步骤为
- 不需要训练,需要提供超参数k
- 取样本空间D中离测试样本最近的k个点
- 取k点的均值为预测值
补充
关于距离:
- 欧式距离
- Mahalanobis距离:给定向量x、y以及矩阵S,其定义为
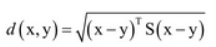
当S为单位矩阵的时候,其距离描述的就是欧式距离,为了求出矩阵S,引出了距离度量学习。(S也可以由样本的协方差矩阵得到,但准确率可能不一样)。 - Bhatlacharyya距离:
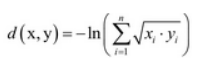
,其中 xi和yi为取某一值的概率。
代码实验
# -*- coding: utf-8 -*-
"""
Created on Sun Oct 7 13:24:30 2018
@author: ar45
"""
from sklearn.model_selection import train_test_split
from sklearn import datasets
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
iris = datasets.load_iris()#加载训练集
X = iris.data#数据集
y = iris.target#结果
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.3)#测试集和训练集划分
#print(X_train[1:3,:])
knn = KNeighborsClassifier(4,weight="uniform")
#加载分类器,让k=4,分配权重方式为uniform,也就是权重相等,weights = 'distance'表示的是权重与距离成反比
knn.fit(X_train,y_train)# 开始训练
result = knn.predict(X_test)# 在测试集上预测结果
print(np.mean(result==y_test))#对比测试集的结果和预测结果,得到准确率
'''
输出结果
0.9777777777777777
'''
决策树
理解
决策树其实是基于信息论的算法,通过递归实现训练决策的节点。我只学习了ID3、C4.5和CART算法,所以会记录这三种算法,刚学了概率论,对这里的理解更深了。
先验知识
ID3算法
信息熵
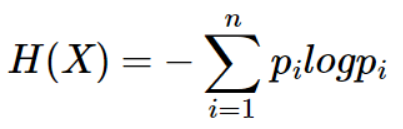
就这么一个公式,其中pi代表是结果的概率。
信息增益
定义条件熵为: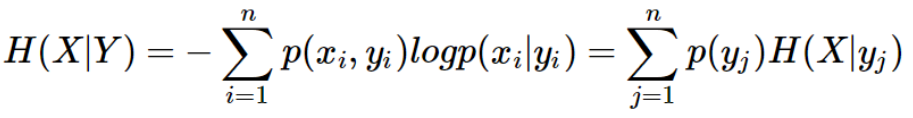
那么前者信息熵与条件熵的差值就是信息增益,表征的是信息的该变量。
C4.5算法
信息增益率
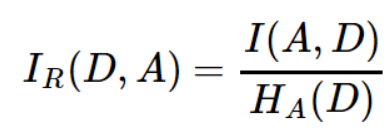
用信息增益率来表征信息变化的多少
CART算法
Gini指数
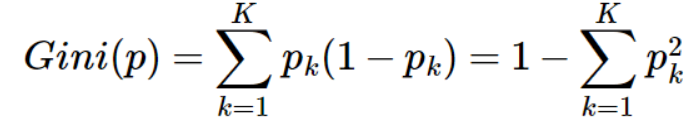
其中pk指的是结果中第k个类别的概率。公式表征的是不纯度大小,越纯Gini指数越小。
这里是针对离散量的也就是分类问题的loss度量公式,如果是回归问题就要用均方误差来衡量了。具体的不讨论。
学习过程
- 先用样本构造根节点,找到用哪个label怎么分,使得信息增益或者不纯度更小(为不纯度的时候,得到分别的不纯度,也就是左右子树不纯度按照样本数量权重求和),并设计阈值,小于阈值并且最小的分裂方式就最为最佳分裂方式,否则就不分裂。
- 将样本集划分为左右子树,分别将左右叶节点设为本节点在训练样本中出现最大的子类。
- 递归进行分裂,直到不纯度都小于阈值停止迭代,训练完成。
剪枝
决策树算法很容易再训练集上过拟合,所以我们采用剪枝的方法来防止其过拟合。
假设我们已经完成了上面的学习过程生成了一颗决策树,下面我们将对其进行剪枝操作:
- 在上面的决策树基础上生成所有可能的剪枝后的决策树(说白了就是一个一个剪掉或者留下这样试),从叶节点开始自下而上进行考察。
- 通过交叉验证的方法在数据集上进行验证,看看剪枝后的该节点处验证准确率是否有提升
- 如果有提升,则保留剪枝后的树;如果有下降,则保留原节点。循环对所有节点进行上面操作。
预测过程
很好理解,就是树状分类器满足一定条件往哪个方向分,相当于if then的结构。
代码实验
# -*- coding: utf-8 -*-
"""
Created on Sun Oct 7 13:24:30 2018
@author: ar45
"""
from sklearn.model_selection import train_test_split
from sklearn import datasets
from sklearn import tree
import numpy as np
import graphviz
digits = datasets.load_digits()
X = digits.data
y = digits.target
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.3)
cls = tree.DecisionTreeClassifier()
cls.fit(X_train,y_train)
r = cls.predict(X_test)
print(np.mean(r==y_test))
dot_data = tree.export_graphviz(cls,out_file="e:/A.dot")#输出到A.dot
'''
输出结果:
8462962962962963
'''
可视化代码:
dot -Tpdf a.dot -o output.pdf
可视化结果:
朴素贝叶斯
朴素贝叶斯主要是利用贝叶斯公式通过特征进行预测的方法,其假设是各个特征之间是相互独立的。
朴素贝叶斯利用的贝叶斯公式为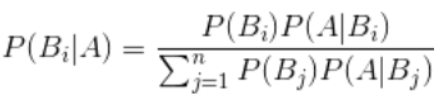
,其中条件概率公式为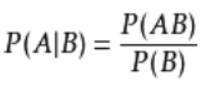
实现步骤
1. 求先验概率
利用极大似然估计法证明和求解(离散数据利用频数处以总数直接求频率),连续数据一般假设服从正态分布,求出u和σ,并且加入平滑项(拉普拉斯平滑),保证在某些类别在样本中没出现的时候,公式中概率不为0.
2. 朴素贝叶斯推断过程
朴素贝叶斯推断是根据后验概率公式,分别求各类的推断的概率,最后投票选取概率最大的类别进行输出。
3.代码实验
# -*- coding: utf-8 -*-
"""
Created on Sun Oct 7 13:24:30 2018
@author: ar45
"""
from sklearn.model_selection import train_test_split
from sklearn import datasets
from sklearn.naive_bayes import GaussianNB
import numpy as np
wine = datasets.load_wine()
X = wine.data
y = wine.target
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.3)
cls = GaussianNB()
cls.fit(X_train,y_train)
r = cls.predict(X_test)
print(np.mean(r==y_test))
'''
这里假设概率服从的是高斯分布。
输出结果:
0.9629629629629629
'''
Logistic回归
理解
logistic 回归,虽然名字里有 “回归” 二字,但实际上是解决分类问题的一类线性模型。
逻辑函数
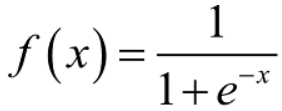
,可以将结果映射到(0,1)的区间上去,相当于输出了一个概率值(概率映射)。
公式过程理解
- 对n个label下的样本集,用W矩阵表示学习的权重,用wTx矩阵相乘之后可以得到每个样本对应的估计值,将逻辑函数中的x替换成wTx + b,结果就被映射成了概率。
- 由于结果被映射成了一个概率值,我们就可以通过极大似然估计的方法,使得在每个样本集的条件下对应真实输出的概率最大,求得此时的参数估计W。
- 由于我们将h(x)的结果映射成了P(y=1|x)的概率值,y的取值不是0就是1,那就简单了,可以写成这样的形式:
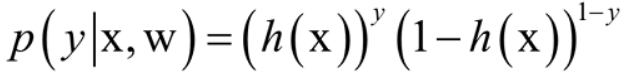
,其表示的是每个样本对应每个类别的概率。 - 由于样本之间相互独立,样本训练集的似然函数为
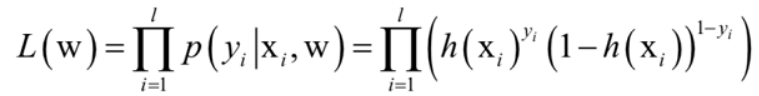
,求他的对数似然函数的最大值,转化为求其相反数的最小值,就又转化为了一个凸优化问题。 - 对于凸优化问题,我们就可以用传统的梯度下降法来求解这个问题了。
代码实验
# -*- coding: utf-8 -*-
"""
Created on Sun Oct 7 13:24:30 2018
@author: ar45
"""
from sklearn.model_selection import train_test_split
from sklearn import datasets
from sklearn.linear_model.logistic import LogisticRegression
import numpy as np
iris = datasets.load_iris()
X = iris.data
y = iris.target
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.3)
cls = LogisticRegression()
cls.fit(X_train,y_train)
print(cls.score(X_test,y_test))
# 代码都是一样的。。。
'''
0.9777777777777777
'''
[机器学习] 简单的机器学习算法和sklearn实现的更多相关文章
- sklearn简单实现机器学习算法记录
sklearn简单实现机器学习算法记录 需要引入最重要的库:Scikit-learn 一.KNN算法 from sklearn import datasets from sklearn.model_s ...
- 机器学习入门 一、理解机器学习+简单感知机(JAVA实现)
首先先来讲讲闲话 如果让你现在去搞机器学习,你会去吗?不会的话是因为你对这方面不感兴趣,还是因为你觉得这东西太难了,自己肯定学不来?如果你觉的太难了,很好,相信看完这篇文章,你就会有胆量踏入机器学习这 ...
- 使用Apriori算法和FP-growth算法进行关联分析
系列文章:<机器学习实战>学习笔记 最近看了<机器学习实战>中的第11章(使用Apriori算法进行关联分析)和第12章(使用FP-growth算法来高效发现频繁项集).正如章 ...
- web安全之机器学习入门——2.机器学习概述
目录 0 前置知识 什么是机器学习 机器学习的算法 机器学习首先要解决的两个问题 一些基本概念 数据集介绍 1 正文 数据提取 数字型 文本型 数据读取 0 前置知识 什么是机器学习 通过简单示例来理 ...
- 最小生成树---Prim算法和Kruskal算法
Prim算法 1.概览 普里姆算法(Prim算法),图论中的一种算法,可在加权连通图里搜索最小生成树.意即由此算法搜索到的边子集所构成的树中,不但包括了连通图里的所有顶点(英语:Vertex (gra ...
- BM算法和Sunday快速字符串匹配算法
BM算法研究了很久了,说实话BM算法的资料还是比较少的,之前找了个资料看了,还是觉得有点生涩难懂,找了篇更好的和算法更好的,总算是把BM算法搞懂了. 1977年,Robert S.Boyer和J St ...
- 台球游戏的核心算法和AI(2)
前言: 最近研究了box2dweb, 觉得自己编写Html5版台球游戏的时机已然成熟. 这也算是圆自己的一个愿望, 一个梦想. 承接该序列的相关博文: • 台球游戏核心算法和AI(1) 同时结合htm ...
- mahout中kmeans算法和Canopy算法实现原理
本文讲一下mahout中kmeans算法和Canopy算法实现原理. 一. Kmeans是一个很经典的聚类算法,我想大家都非常熟悉.虽然算法较为简单,在实际应用中却可以有不错的效果:其算法原理也决定了 ...
- 转载:最小生成树-Prim算法和Kruskal算法
本文摘自:http://www.cnblogs.com/biyeymyhjob/archive/2012/07/30/2615542.html 最小生成树-Prim算法和Kruskal算法 Prim算 ...
随机推荐
- WCF大文件传输【转】
http://www.cnblogs.com/happygx/archive/2013/10/29/3393973.html WCF大文件传输 WCF传输文件的时候可以设置每次文件的传输大小,如果是小 ...
- POJ - 1458 Common Subsequence DP最长公共子序列(LCS)
Common Subsequence A subsequence of a given sequence is the given sequence with some elements (possi ...
- 732. My Calendar III (prev)
Implement a MyCalendarThree class to store your events. A new event can always be added. Your class ...
- ajax连接服务器框架
ajax.js function ajax(url, fnSucc, fnFaild) { //1.创建Ajax对象 if(window.XMLHttpRequest) { var oAjax=new ...
- iOS 根据文字字数动态确定Label宽高
iOS7中用以下方法 - (CGSize)sizeWithAttributes:(NSDictionary *)attrs; 替代过时的iOS6中的- (CGSize)sizeWithFont:(UI ...
- [SDOI2013]随机数生成器
Description Input 输入含有多组数据,第一行一个正整数T,表示这个测试点内的数据组数. 接下来T行,每行有五个整数p,a,b,X1,t,表示一组数据.保证X1和t都是合法的页码. 注意 ...
- BestCoder Round #81 (div.2) 1003 String
题目地址:http://bestcoder.hdu.edu.cn/contests/contest_showproblem.php?cid=691&pid=1003题意:找出一个字符串满足至少 ...
- Win10专业版系统下添加其他国家语言
Win10专业版系统下如何添加其他国家语言?国内的win10专业版系统默认情况下是安装简体中文,但是有的用户出于工作原因需要使用其它字体.比如外国友人就需要使用英语,西班牙等.其实win10专业版是支 ...
- NET Core迁移
向ASP.NET Core迁移 有人说.NET在国内的氛围越来越不行了,看博客园文章的浏览量也起不来.是不是要转Java呢? 没有必要扯起语言的纷争,Java也好C#都只是语言是工具,各有各的 ...
- Hypertext Application Language(HAL)
Hypertext Application Language(HAL) HAL,全称为Hypertext Application Language,它是一种简单的数据格式,它能以一种简单.统一的形式, ...