02 python网络爬虫《Http和Https协议》
一.HTTP协议
1.概念:
Http协议就是服务器(Server)和客户端(Client)之间进行数据交互(相互传输数据)的一种形式。
之间形成的特殊行话(黑话:(土匪)天王盖地虎,(我)宝塔镇河妖)称为协议。
2.Http工作原理:
Http协议工作于客户端-服务端架构上。浏览器作为Http客户端通过URl 向Http服务器(web服务器)发送所有请求。Web服务器根据接收到的请求后,向客户端发送相应信息。
3.Http四点注意事项:
-Http允许传输任意类型的数据对象。正在传输的类型油Content-Type加以标记。
-Http是无连接的:无连接的含义是限制每次连接只处理一个请求。服务器处理完成客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
-Http是无状态的:无状态是指对处理事务没有记忆功能,缺少状态意味着如果处理以前处理过的信息必须要重新传输,导致每次连接传送的数据量增大。另一方面在服务器不需要先前信息时他的应答比较快。
- Http是媒体独立的:这意味着,只要客户端和服务器知道如何处理的数据内容,任何类型的数据都可以通过HTTP发送。客户端以及服务器指定使用适合的MIME-type内容类型。
4.Http之request
客户端发送一个HTTP请求到服务器的请求消息包括以下组成部分:
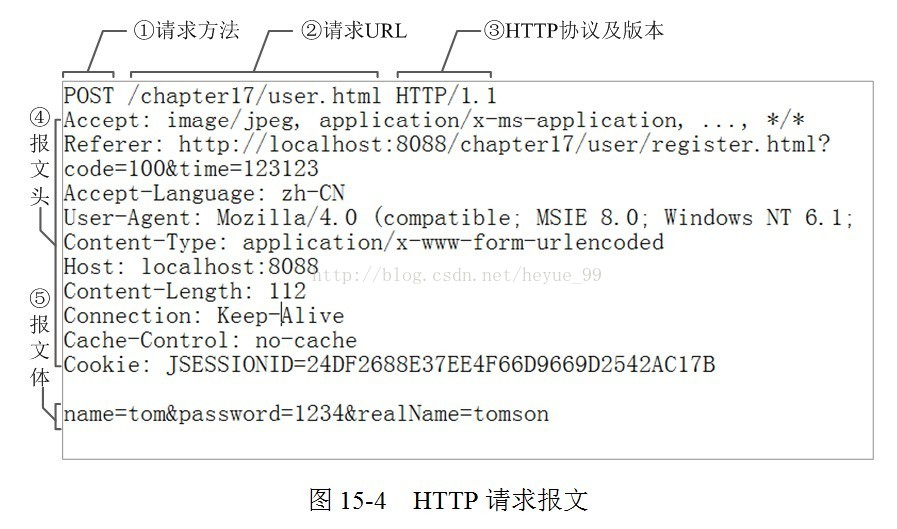
报文头:常被叫做请求头,请求头中存储的是该请求的一些主要说明(自我介绍)。服务器据此获取客户端的信息。
常见的请求头:
accept:浏览器通过这个头告诉服务器,它所支持的数据类型
Accept-Charset:浏览器通过这个头告诉服务器,它所支持哪种字符集
Accept-Encoding:浏览器通过这个头告诉服务器,支持的压缩格式
Accept-Language:浏览器通过这个头告诉服务器,它的语言环境
Host:浏览器通过这个头告诉服务器,想访问哪台主机
User-Agent:请求载体的身份标识
Connection:浏览器通过这个头告诉服务器,请求完后是断开链接还是何持链接
报文体:常被叫做请求体,请求体中存储的是将要传输/发送给服务器的数据信息。
4.Http之response
服务器回传一个HTTP响应到客户端的响应消息包括以下组成部分:

状态码:以“清晰明确”的语言告诉客户端本次请求的处理结果。
HTTP的响应状态码由5段组成:
1xx 消息,一般是告诉客户端,请求已经收到了,正在处理,别急...
2xx 处理成功,一般表示:请求收悉、我明白你要的、请求已受理、已经处理完成等信息.
3xx 重定向到其它地方。它让客户端再发起一个请求以完成整个处理。
4xx 处理发生错误,责任在客户端,如客户端的请求一个不存在的资源,客户端未被授权,禁止访问等。
5xx 处理发生错误,责任在服务端,如服务端抛出异常,路由出错,HTTP版本不支持等。
响应头:响应的详情展示
常见的相应头信息:
Location: 服务器通过这个头,来告诉浏览器跳到哪里
Server:服务器通过这个头,告诉浏览器服务器的型号
Content-Encoding:服务器通过这个头,告诉浏览器,数据的压缩格式
Content-Length: 服务器通过这个头,告诉浏览器回送数据的长度
Content-Language: 服务器通过这个头,告诉浏览器语言环境
Content-Type:服务器通过这个头,告诉浏览器回送数据的类型
Refresh:服务器通过这个头,告诉浏览器定时刷新
Content-Disposition: 服务器通过这个头,告诉浏览器以下载方式打数据
Transfer-Encoding:服务器通过这个头,告诉浏览器数据是以分块方式回送的
Expires: -1 控制浏览器不要缓存
Cache-Control: no-cache
Pragma: no-cache
相应体:根据客户端指定的请求信息,发送给客户端的指定数据
二.Https协议:
1. 概念:加密安全版的Http协议。
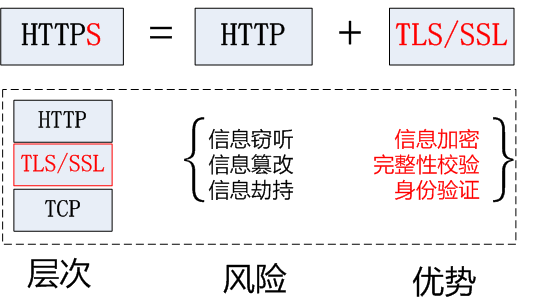
2. Https采用的加密技术:
2.1 SSL加密技术(对称密钥加密)
SSL采用的加密技术叫做“共享密钥加密”,也叫作“对称密钥加密”,这种加密方法是这样的,比如客户端向服务器发送一条信息,首先客户端会采用已知的算法对信息进行加密,比如MD5或者Base64加密,接收端对加密的信息进行解密的时候需要用到密钥,中间会传递密钥,(加密和解密的密钥是同一个),密钥在传输中间是被加密的。这种方式看起来安全,但是仍有潜在的危险,一旦被窃听,或者信息被挟持,就有可能破解密钥,而破解其中的信息。因此“共享密钥加密”这种方式存在安全隐患:
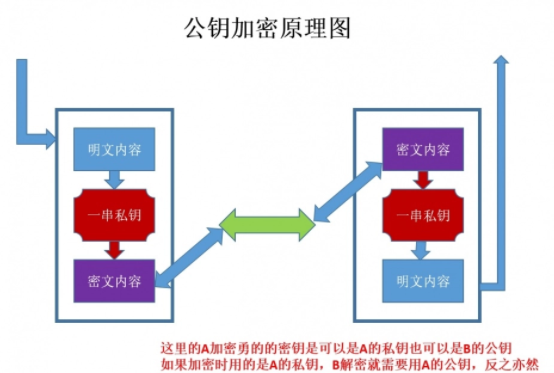
2.2 非对称密钥加密技术
“非对称加密”使用的时候有两把锁,一把叫做“私有密钥”,一把是“公开密钥”,使用非对象加密的加密方式的时候,服务器首先告诉客户端按照自己给定的公开密钥进行加密处理,客户端按照公开密钥加密以后,服务器接受到信息再通过自己的私有密钥进行解密,这样做的好处就是解密的钥匙根本就不会进行传输,因此也就避免了被挟持的风险。就算公开密钥被窃听者拿到了,它也很难进行解密,因为解密过程是对离散对数求值,这可不是轻而易举就能做到的事。以下是非对称加密的原理图:

但是非对称秘钥加密技术也存在如下缺点:
第一个是:如何保证接收端向发送端发出公开秘钥的时候,发送端确保收到的是预先要发送的,而不会被挟持。只要是发送密钥,就有可能有被挟持的风险。
第二个是:非对称加密的方式效率比较低,它处理起来更为复杂,通信过程中使用就有一定的效率问题而影响通信速度
2.3 Http证书机制
在上面我们讲了非对称加密的缺点,其中第一个就是公钥很可能存在被挟持的情况,无法保证客户端收到的公开密钥就是服务器发行的公开密钥。此时就引出了公开密钥证书机制。数字证书认证机构是客户端与服务器都可信赖的第三方机构。证书的具体传播过程如下:
1:服务器的开发者携带公开密钥,向数字证书认证机构提出公开密钥的申请,数字证书认证机构在认清申请者的身份,审核通过以后,会对开发者申请的公开密钥做数字签名,然后分配这个已签名的公开密钥,并将密钥放在证书里面,绑定在一起

2:服务器将这份数字证书发送给客户端,因为客户端也认可证书机构,客户端可以通过数字证书中的数字签名来验证公钥的真伪,来确保服务器传过来的公开密钥是真实的。一般情况下,证书的数字签名是很难被伪造的,这取决于认证机构的公信力。一旦确认信息无误之后,客户端就会通过公钥对报文进行加密发送,服务器接收到以后用自己的私钥进行解密。
备注:本文参考:https://www.cnblogs.com/bobo-zhang/p/9645715.html
02 python网络爬虫《Http和Https协议》的更多相关文章
- Python网络爬虫http和https协议
一.HTTP协议 1.官方概念: HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文 ...
- 02.Python网络爬虫第二弹《http和https协议》
一.HTTP协议 1.官方概念: HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文 ...
- 02.python网络爬虫第二弹(http和https协议)
一.HTTP协议 1.官方概念: HTTP协议是 Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(www.world wide web) 服务器传输超 ...
- python网络爬虫学习笔记
python网络爬虫学习笔记 By 钟桓 9月 4 2014 更新日期:9月 4 2014 文章文件夹 1. 介绍: 2. 从简单语句中開始: 3. 传送数据给server 4. HTTP头-描写叙述 ...
- 《精通python网络爬虫》笔记
<精通python网络爬虫>韦玮 著 目录结构 第一章 什么是网络爬虫 第二章 爬虫技能概览 第三章 爬虫实现原理与实现技术 第四章 Urllib库与URLError异常处理 第五章 正则 ...
- Python 网络爬虫干货总结
Python 网络爬虫干货总结 爬取 对于爬取来说,我们需要学会使用不同的方法来应对不同情景下的数据抓取任务. 爬取的目标绝大多数情况下要么是网页,要么是 App,所以这里就分为这两个大类别来进行了介 ...
- Python网络爬虫与信息提取
1.Requests库入门 Requests安装 用管理员身份打开命令提示符: pip install requests 测试:打开IDLE: >>> import requests ...
- 第三次作业-MOOC学习笔记:Python网络爬虫与信息提取
1.注册中国大学MOOC 2.选择北京理工大学嵩天老师的<Python网络爬虫与信息提取>MOOC课程 3.学习完成第0周至第4周的课程内容,并完成各周作业 第一周 Requests库的爬 ...
- 假期学习【六】Python网络爬虫2020.2.4
今天通过Python网络爬虫视频复习了一下以前初学的网络爬虫,了解了网络爬虫的相关规范. 案例:京东的Robots协议 https://www.jd.com/robots.txt 说明可以爬虫的范围 ...
随机推荐
- 牛客网Java刷题知识点之四种不同的方式创建线程
不多说,直接上干货! 有4种方式可以用来创建线程: 第一种:继承Thread类,重写run方法 第二种:实现Runnable接口,并实现该接口的run方法(一般我们在编程的时候推荐用这种) 第三种:实 ...
- java 从List<Integer> 中随机获取6个数
List<Integer> list 为不重复的数字集合,例如:1,2,3,4,5,6,7,8,9,10 从中随机获取不重复的6个数.代码如下. List<Integer> l ...
- MyBatis总结与复习
Spring 主流框架 依赖注入容器/AOP实现 声明式事务 简化JAVAEE应用 粘合剂,将大家组装到一起 SpringMVC 1. 结构最清晰的MVC Model2实现 2. 高度可配置,支持 ...
- [LeetCode]3. Longest Substring Without Repeating Characters无重复字符的最长子串
Given a string, find the length of the longest substring without repeating characters. Example 1: In ...
- Js常见算法实现汇总
/*去重*/ <script> function delRepeat(arr){ var newArray=new Array(); var len=arr.length; for(var ...
- Vue日历
Vue生成日历,根据返回值将日期标红 HTML: <h1>CSS 日历</h1> <div id="calendar"> <div cla ...
- 《C++面向对象程序设计》之变量的生存期
<C++面向对象程序设计>之变量的生存期 静态生存期 (1)全局静态生存期:在函数体外声明,作用域从声明处开始到文件结尾处结束,称其有文件作用域,相当于全局变量 . (2)局部静态生存期: ...
- 构建第一个Spring Boot2.0应用之集成mybatis(六)
一.环境: IDE:IntelliJ IDEA 2017.1.1 JDK:1.8.0_161 Maven:3.3.9 springboot:2.0.2.RELEASE 二.步骤 方式一:利用配置文件配 ...
- arcgis textsymbol overlap
arcgis textsymbol overlap textsymbol 重叠的问题 du?de? duration?? arcgis for javascript 如何避免 ...
- 【server 安全】更改本地安全策略及禁用部分服务以进一步增强windows server的安全性
本地安全策略 以上内容的备份 注册表路径: System\CurrentControlSet\Control\ProductOptionsSystem\CurrentControlSet\Contro ...