国人之光:大数据分析神器Apache Kylin
一、简介
二、基本概念
| ID | 客户号 | 交易日期 | 交易类型 | 金额 |
| 1 | 001 | 20201230 | 工资代发 | 1000000 |
| 2 | 002 | 20210101 | 转账 | 66666 |
| 3 | 003 | 20210115 | 信用卡还款 | 1888 |
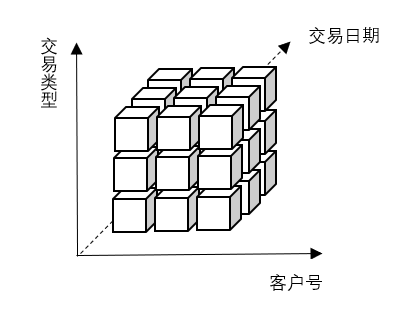
查询某个客户在哪个时间进行某种交易的金额,这种是多维分析,其中客户号、交易日期和交易类型是维度(Dimensions),金额是度量(Measures)。
三、作用及原理
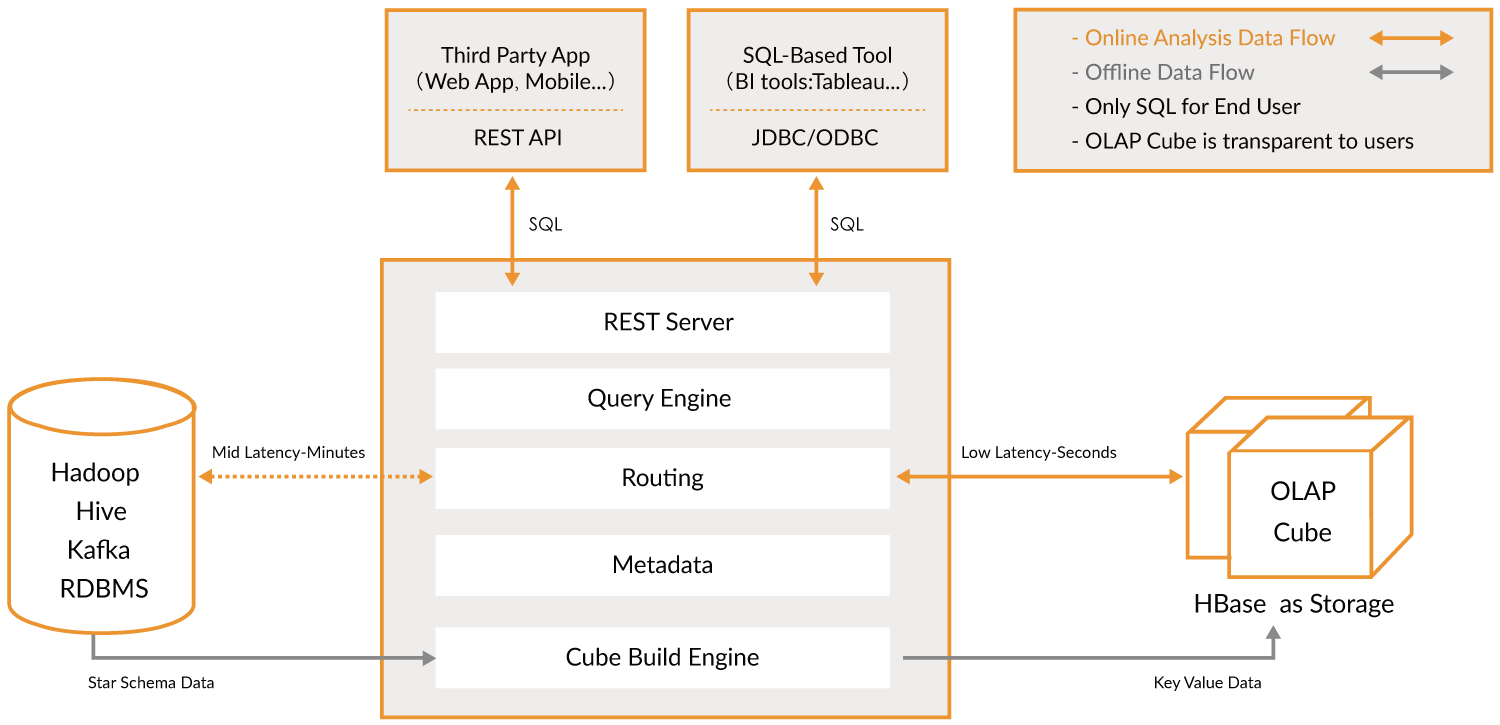
四、Kylin的架构
五、总结
本文大概介绍了Kylin以及一些相关的概念和原理、架构。更多内容可以去Kylin 官网进行了解.
国人之光:大数据分析神器Apache Kylin的更多相关文章
- Windows 上用IntelliJ Idea调试百度大数据分析框架Apache Doris FE
A. 环境准备 1. 安装jdk1.8+, Intelij IDEA 2. linux上编译好fe前端代码,主要目的是获取自动生成的代码,加入到前段工程里面去用于在idea中编译fe工程.具体编译请参 ...
- 大数据分析引擎Apache Flink
Apache Flink是一个高效.分布式.基于Java实现的通用大数据分析引擎,它具有分布式 MapReduce一类平台的高效性.灵活性和扩展性以及并行数据库查询优化方案,它支持批量和基于流的数据分 ...
- 【大数据安全】Apache Kylin 安全配置(Kerberos)
1. 概述 本文首先会简单介绍Kylin的安装配置,然后介绍启用Kerberos的CDH集群中如何部署及使用Kylin. Apache Kylin™是一个开源的分布式分析引擎,提供Hadoop/Spa ...
- CentOS 上使用vscode 调试百度大数据分析框架Apache Doris BE
A: 前期准备工作 1. 安装vscode,详细请参见vscode官网https://code.visualstudio.com/docs/setup/linux,摘要如下: sudo rpm --i ...
- 《基于Apache Kylin构建大数据分析平台》
Kyligence联合创始人兼CEO,Apache Kylin项目管理委员会主席(PMC Chair)韩卿 武汉市云升科技发展有限公司董事长,<智慧城市-大数据.物联网和云计算之应用>作者 ...
- 【转】使用Apache Kylin搭建企业级开源大数据分析平台
http://www.thebigdata.cn/JieJueFangAn/30143.html 本篇文章整理自史少锋4月23日在『1024大数据技术峰会』上的分享实录:使用Apache Kylin搭 ...
- 大数据分析神兽麒麟(Apache Kylin)
1.Apache Kylin是什么? 在现在的大数据时代,越来越多的企业开始使用Hadoop管理数据,但是现有的业务分析工具(如Tableau,Microstrategy等)往往存在很大的局限,如难以 ...
- 大数据分析界的“神兽”Apache Kylin有多牛?【转】
本文作者:李栋,来自Kyligence公司,也是Apache Kylin Committer & PMC member,在加入Kyligence之前曾就职于eBay.微软. 1.Apache ...
- 使用Apache Kylin搭建企业级开源大数据分析平台
转:http://www.thebigdata.cn/JieJueFangAn/30143.html 我先做一个简单介绍我叫史少锋,我曾经在IBM.eBay做过大数据.云架构的开发,现在是Kylige ...
随机推荐
- MySQL主从重新同步
主从数据不一致,重新配置主从同步也是一种解决方法. 1.从库停止主从复制 stop slave; 2.对主库数据库加锁 flush tables with read lock; 3.备份主库数据 my ...
- 【Electron Playground 系列】窗口篇
作者:Kurosaki 本文主要讲解Electron 窗口的 API 和一些在开发之中遇到的问题. 官方文档 虽然比较全面,但是要想开发一个商用级别的桌面应用必须对整个 Electron API 有 ...
- django获取choices的显示值
1,models.py #订单表 class Orders(models.Model): status_cat = ( ('0', '待装货'), ('1', '正在运输'), ('2', '已到达目 ...
- wildfly 21的domain配置
目录 简介 wildfly模式简介 domain controller的配置 Host controller的配置文件 忽略域范围的资源 Server groups Servers 总结 简介 wil ...
- [论文分享] DHP: Differentiable Meta Pruning via HyperNetworks
[论文分享] DHP: Differentiable Meta Pruning via HyperNetworks authors: Yawei Li1, Shuhang Gu, etc. comme ...
- Node.js躬行记(5)——定时任务的调试
最近做一个活动,需要用到定时任务,于是使用了 node-schedule 库. 用法很简单,就是可配置开始.结束时间,以及重复执行的时间点,如下所示,从2020-12-23T09:00:00Z开始,每 ...
- Linux课程知识点总结(二)
Linux课程知识点总结(二) 七.Shell实用功能 7.1 命令行自动补全 在Linux系统中,有太多的命令和文件名称需要记忆,使用命令行补全功能[Tab]可以快速的写出文件名和命令名 7.2 命 ...
- UDP 通讯方式
1.创建套接字:2.绑定端口:3.收发数据: 收到的数据中包含发送方的端口信息4.关闭套接字:
- JAVA并发包——锁
1.java多线程中,可以使用synchronized关键字来实现线程间的同步互斥工作,其实还有个更优秀的机制来完成这个同步互斥的工作--Lock对象,主要有2种锁:重入锁和读写锁,它们比synchr ...
- CSS系列 (05):浮动详解
浮动的框可以向左或向右移动,直到它的外边缘碰到包含框或另一个浮动框的边框为止.由于浮动框不在文档的普通流中,所以文档的普通流中的块框表现得就像浮动框不存在一样. -- W3C 文字环绕 float可以 ...