Redis集群搭建很easy
前言
哨兵模式虽然让读写分离更加高可用,但单台服务器由于本身的内存和CPU瓶颈,对于高并发和大数据业务的应用场景还是远远不能满足;对于这种情况,有点经验的小伙伴会毫不犹豫的想到集群,搞他好几个节点,负载均衡再加上故障转移,岂不美哉。是的,就是这个理,接下来玩玩。
正文
集群,相信这个词小伙伴应该听的耳朵起茧子了吧;多搞几台服务器,让请求/命令平均分发到各个服务器,避免单台服务器承载过大压力;对于Redis集群来说,为了实现自动故障转移,还需要在每个主节点上增加一个或多个从节点,当主节点发生故障时,从节点自动补上,实现高可用。
总的来说,Redis集群有以下作用:
- 多主节点的实现可以应对高并发场景,并发量增大,节点可以随时扩展满足需求;
- 多主节点的实现可以存储更多的数据,因为数据均匀分布到各个节点;
- 多主节点搭配多从节点的实现让高可用更加稳定,即当有主节点发生故障时,对应下面的从节点会升级为主节点,正常提供功能;
老规矩不变,一边实操一边总结,接下来搭建一个3主3从的集群,这是最简单的。 Redis集群中最少需要3个主节点,再加上为了实现高可用,每个主节点至少得跟一个从节点,不然一个主节点挂了,找不到完整的数据,整个集群就不能用了;至于为什么会找不到完整的数据,下面会聊到。
接下来要搭建的集群环境如下:
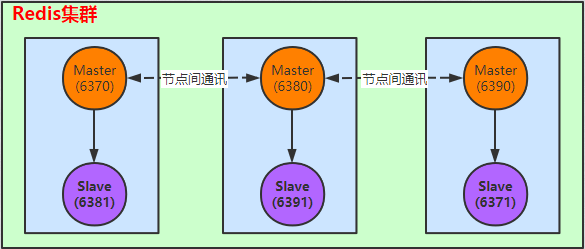
简要说明:
- 6370为主节点,6381为6370的从节点;
- 6380为主节点,6391为6380的从节点;
- 6390为主节点,6371为6390的从节点;
- 在集群环境中主节点之间是相互通讯的(这里没有哨兵),每一个节点都是数据节点;
这里集群方案使用redis-cli自动指定主从关系(小伙伴的主从关系可能会和我这不一样哦),也可以手动指定;反正思路都一样;
以下演示在同一台机器上,通过端口区分各个节点;在实际开发中,一般都是用不同的服务器。
案例演示
准备六个节点的配置文件,开启集群相关配置;
拷贝最初默认的配置文件,然后进行更改,主要更改以下项:
port 6370 # 指定Redis节点端口
pidfile /var/run/redis_6370.pid # 指定对应进程文件
dbfilename dump6370.rdb # 每个节点的rdb持久化文件
cluster-enabled yes # 开启集群,这个比较重要
cluster-config-file nodes-6370.conf #指定每个节点的集群配置文件,这个比较重要
以上配置文件内容在其他节点(6370,6371,6380,6381,6390,6391)都需要进行修改,只是将其中6370改为对应节点的端口即可,目的就是为了不同节点使用不同端口并区分用到的不同文件即可;比如需要修改6371节点的配置文件如下:
port 6371 # 指定Redis节点端口
pidfile /var/run/redis_6371.pid # 指定对应进程文件
dbfilename dump6371.rdb # 每个节点的rdb持久化文件
cluster-enabled yes # 开启集群,这个比较重要
cluster-config-file nodes-6371.conf #指定每个节点的集群配置文件,这个比较重要
其中cluster-enabled和cluster-config-file是集群配置的重点。
启动六个节点,刚开始各个节点是相互独立的;
准备好配置文件之后,就可以使用redis-server指定配置文件启动节点啦,如果节点多,小伙伴可以编写脚本哦;
./redis-server ZoeCluster/redis6370.conf # 启动6370节点
./redis-server ZoeCluster/redis6371.conf # 启动6371节点
./redis-server ZoeCluster/redis6380.conf # 启动6380节点
./redis-server ZoeCluster/redis6381.conf # 启动6381节点
./redis-server ZoeCluster/redis6390.conf # 启动6390节点
./redis-server ZoeCluster/redis6391.conf # 启动6391节点
启动效果如下:
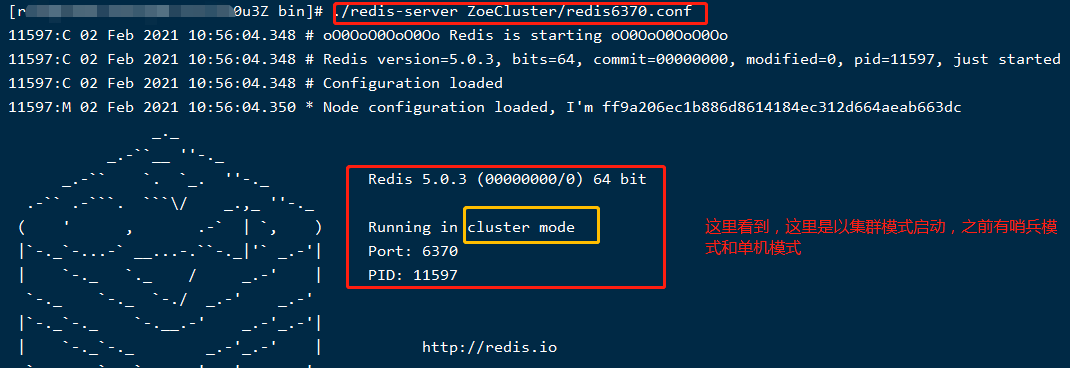
这样只是将各个节点启动起来,集群关系还没创建呢,如果不信,可以使用redis-cli连接任意一个节点查看集群信息,如下:
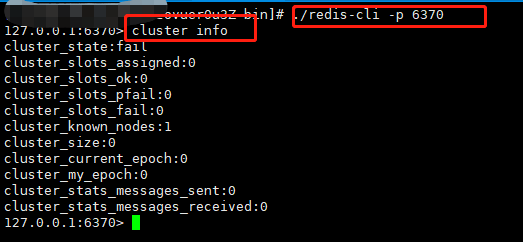
如上图,cluster-size为0,集群的关键,槽也还没有分配;那接下来肯定是要将各节点的集群关系搞起来;
建立节点集群关系
由于我使用的Redis版本是5.0,直接可以使用redis-cli就可以进行集群搭建,在此版本之前都推荐使用redis-trib.rb进行相关操作,这个是一个Ruby脚本,需要安装相关环境,小伙伴可以下来尝试;
使用命令如下:
./redis-cli --cluster create --cluster-replicas 1 127.0.0.1:6370 127.0.0.1:6380 127.0.0.1:6390 127.0.0.1:6371 127.0.0.1:6381 127.0.0.1:6391
参数简介:
-- cluster : 指定是用于创建集群环境;
-a:密码,即如果有密码,可以通过-a传参,这里没有设置密码;
--cluster-replicas:这里设置为1, 用于配置主节点上的从节点数,1就代表一主一从,2就代表一主二从,依次类推;
后面的是节点IP:节点端口,一般前面的是主节点,后面的是从节点;
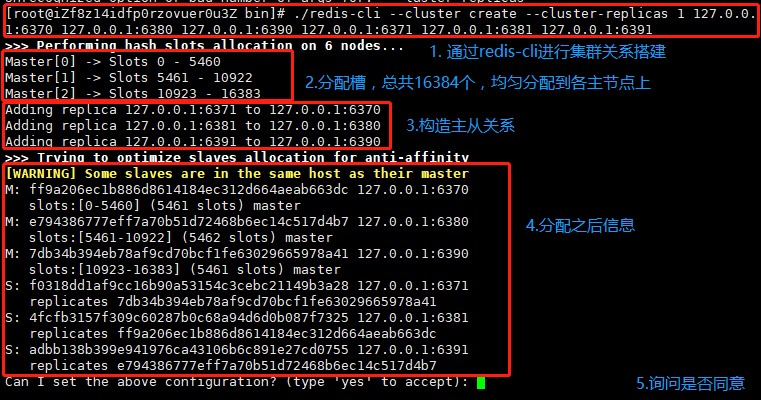
如果同意集群方案,然后就开始进行相关操作,如下:
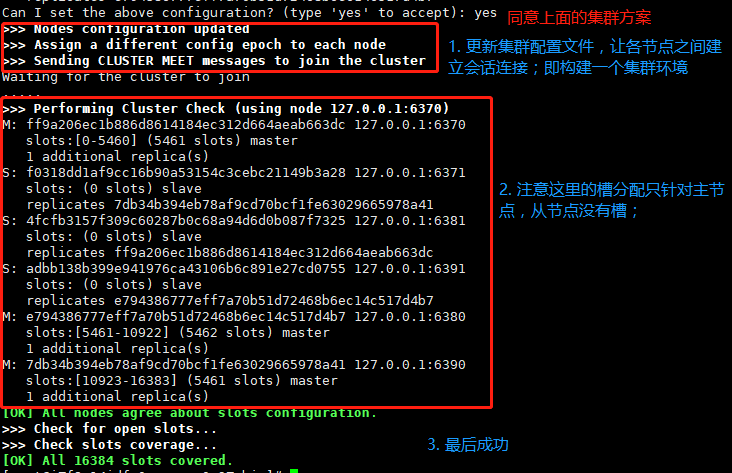
同样,可以连接到任意一个节点,查看集群情况,如下:
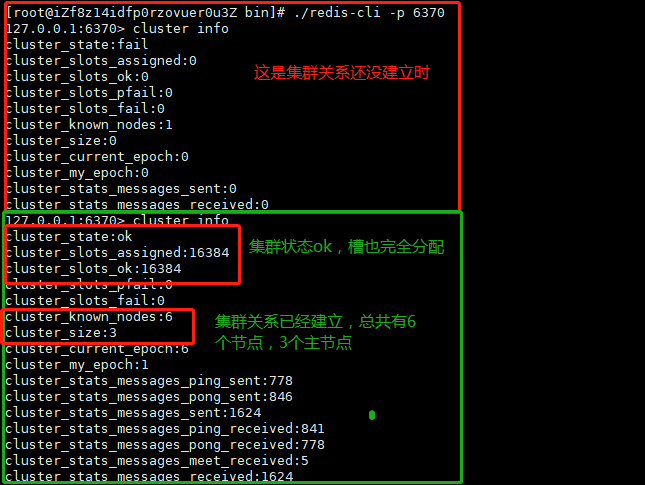
注:关于主从节点之间的主从复制过程就不在这说了,和之前说过的主从复制一样;
演示访问操作;
使用redis-cli连接任意节点写入数据,如果不指定集群连接的话,会写入数据失败,如下:

由于集群环境下,数据的存储位置是根据Key来计算而来的(这里牵涉到一致性哈希算法),使得数据可以均匀分配到各节点上,所以在redis-cli连接的时候需要指定集群模式,如下:

如上图所示,指定集群模式之后就可以正常存取了;
故障演示
既然集群环境,肯定少不了要好好测测;
模拟从节点挂掉
找个从节点停掉试试,这里停掉6371节点,根据创建集群信息知道,它的主节点是6390;
主节点显示从节点断开连接,看看它的主节点反应:

其他集群节点只是将从节点标记为failing状态,即下线状态,如下:

对于存取数据也不受影响,这里就不截图了,小伙伴自行尝试吧;
当故障的从节点6371重新连上时,主节点恢复主从关系,并进行主从复制操作;其他集群节点会清除原来标记的下线状态,将其改为上线;
模拟主节点挂掉
这里就手动将6390这个节点停掉,会有怎样的反应呢?
自身从节点会每隔一秒检测连接,如果超时(默认是15秒),会选举从节点做为集群的主节点来提供服务,如下图:
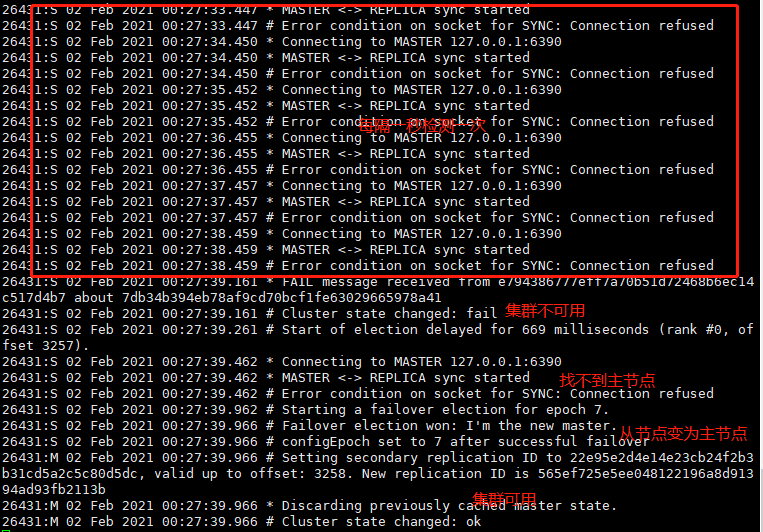
数据存取最终还是不受影响;
对于其他集群节点,将故障节点标记为failing,让新上任的主节点提供服务,如下图:

存取数据也是不受影响的;
挂掉的主节点6390如果恢复,那它只能变为6371的从节点啦,并进行相关主从复制操作;而集群的其他节点只是将其原有的Fail状态清除,表示可以正常连接;
Redis集群就是这样简单,只要思路对,就是手工活;小伙伴可以编写脚本自动执行哦;
接下来说说集群数据的存储;
数据存储简单分析
在Redis集群环境中,数据的存储位置是根据对Key的Hash计算进行指定的; Redis集群为了在节点改变时保证数据分布均匀,引入了槽(slot)作为迁移的基本单位,槽解耦了数据和实际节点的关系,使得实际节点数的改变对系统影响较小;
在整个集群中,槽(slot)总共有16384,会将其均匀分配到集群的主节点上,其中每一份槽对应一个存储空间(这里的存储空间可以理解为一个容器,是可以存很多数据的),以上集群环境的槽分配如下:
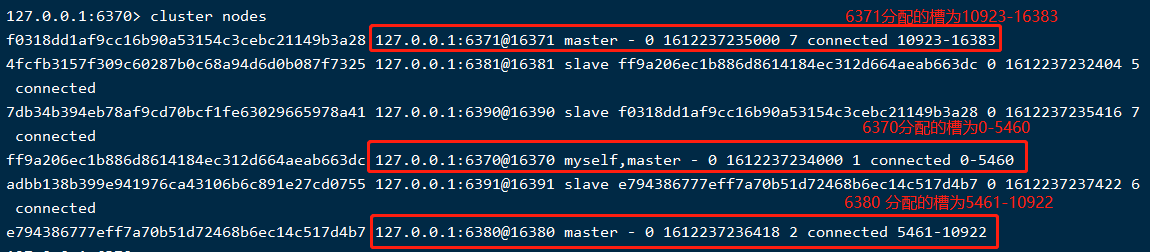
存储数据的过程,如下:
连接6380主节点,执行如下操作:

具体过程如下:
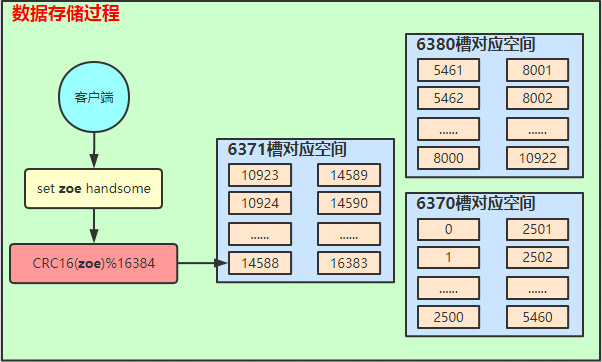
简要说明:
- 客户端发起命令;
- 服务器将Key进行CRC16计算,并与总槽位计算出Key需要存储的位置;
- 这里模拟的Key为zoe,计算出的槽位为14588,不在6380这个节点上,集群节点会将其重定向到对应槽位的节点上;
- 然后找到6371上的14588槽位进行数据存储;(注,这里的6371已经是主节点了,因为上面做过一次故障转移模拟);
那集群节点是如何知道其他节点的槽范围和其他信息呢?
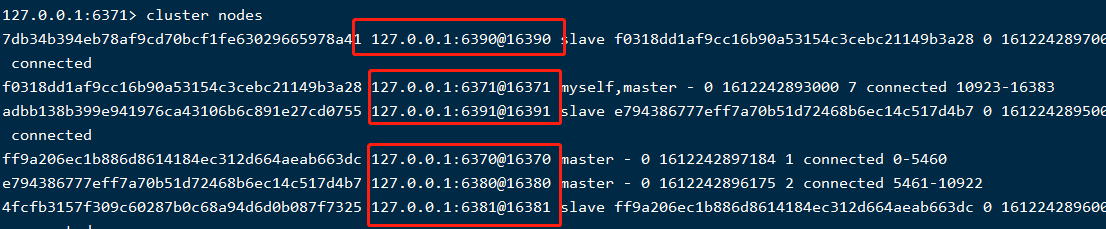
那是因为各节点之间有通讯,通讯端口是对应的redis端口+10000,比如节点6371的集群通讯端口为16371(如果多台机器,别忘了防火墙放开这个端口哦),可以通过cluster nodes看到,如下:
并且将各节点的信息保存在自己对应的集群配置文件中,这个集群文件名是通过配置项cluster-config-file指定的,在集群节点启动时会检查该文件是否存在,如果不存在,会自动创建,如果存在,就加载里面的相关配置信息;里面有哪些信息,随便找个节点的配置文件看一下:
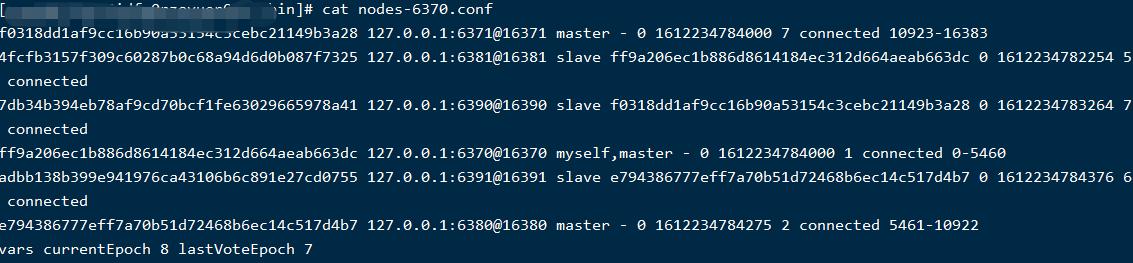
如上图所示,各节点的配置文件中记录了其他节点的主从关系,分配的槽位,各节点的状态;这样的话,集群关系就算重新启动也还存在。
集群伸缩(节点增删)演示
在实际应用场景中,会根据业务需要,对集群进行伸缩,即节点的增删;业务并发大了加节点进行扩展, 节点需要调整时可能需要进节点删除;
加节点
这里进行节点扩展,加一个6360主节点,6361作为6360的从节点;参照以上集群搭建时配置文件更改,然后将其都启动,如下:
6360节点
port 6360 # 指定Redis节点端口
pidfile /var/run/redis_6360.pid # 指定对应进程文件
dbfilename dump6360.rdb # 每个节点的rdb持久化文件
cluster-enabled yes # 开启集群,这个比较重要
cluster-config-file nodes-6360.conf #指定每个节点的集群配置文件,这个比较重要
6361节点
port 6361 # 指定Redis节点端口
pidfile /var/run/redis_6361.pid # 指定对应进程文件
dbfilename dump6361.rdb # 每个节点的rdb持久化文件
cluster-enabled yes # 开启集群,这个比较重要
cluster-config-file nodes-6361.conf #指定每个节点的集群配置文件,这个比较重要
两个节点都启动,然后将6360加入到集群主节点中,执行以下命令:
./redis-cli --cluster add-node 127.0.0.1:6360 127.0.0.1:6370
注:其中127.0.0.1:6360是需要加入的新增节点,127.0.0.1:6370是现有集群中的任意一个节点;
可以通过以下命令检测集群状态,如下:
./redis-cli --cluster check 127.0.0.1:6370 # 后面的地址是任意的集群节点
可以看到6360已经加入到集群环境中,但现在还没有从节点和槽分配,所以接下来先将6361作为6360的从节点加入,如下:
./redis-cli --cluster add-node --cluster-slave --cluster-master-id eaa814dc56beb0d5edb6a4fbb14f1384e78d4764 127.0.0.1:6361 127.0.0.1:6370
参数说明:
- --cluster-slave : 意思就是加入的是从节点;
- --cluster-master-id:后面紧跟主节点的id,这里就是6360的节点id;通过cluster nodes可以查看到节点id;
- 127.0.0.1:6361:需要加入的从节点;
- 127.0.0.1:6370:现有集群的任意主节点;
现在还差槽分配了,如果需要直接将16384个槽平均分配到所有节点话,直接执行以下命令即可:
./redis-cli --cluster rebalance --cluster-threshold 1 --cluster-use-empty-masters 127.0.0.1:6370
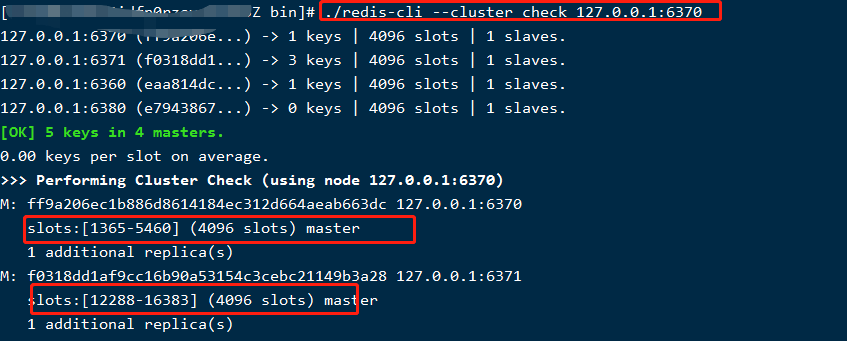
使用命令./redis-cli --cluster check 127.0.0.1:6370查看分配结果,如下图,只截了部分:
如果不想均匀分配,根据自定义需要进行配置,可以执行以下命令,会提示一步一步配置;
./redis-cli --cluster reshard 127.0.0.1:6360 #后面是新加入的主节点
# 也可以执行以下指令直接配置想要的数据
./redis-cli --cluster reshard --cluster-from all --cluster-to 需要分配槽的节点id --cluster-slots 1000 --cluster-yes 127.0.0.1:6370 # 1000 指分配的槽数
这里就不截图演示了,留给小伙伴自己动手操作吧;
删除节点
先对节点进行分片工作,防止数据丢失,即将指定节点上的槽分配到其他节点;
./redis-cli --cluster reshard 要删除节点ip:port移除节点,推荐先删除从节点,再删除主节点;
./redis-cli --cluster del-node 节点ip:port 节点id
集群配置项
- cluster-enabled(是否开启集群模式):设置为yes,将该节点开启为集群模式;
- cluster-config-file(设置每个集群节点对应的配置文件名称):文件是自动生成的,不用手动创建;
- cluster-node-timeout(设置超时时间,即集群节点不可用的最大时间,如果超过这个时间就认为该节点不可用):默认为15000(以毫秒为单位);
- cluster-migration-barrier(配置一个主机最少可用的从机的个数):默认是1,表示一个主机的从机迁移之后,至少得有一个从机可用,否则不进行节点迁移;
- cluster-require-full-coverage(配置集群服务的可用性):默认yes开启,即集群没完全覆盖所有slot,集群就挂了;设置为no,就算槽没有全分配,也能提供服务,需要自己保证槽分配;
总结
到这集群的搭建就完啦,本来想着写着很简单的,没想到又干了4000字;对于集群,使用有一些限制,比如Keys命令只能针对当前节点,需要针对多节点的情况进行处理;集群中各节点只支持db0数据库,其他数据库不支持等等;所以使用要注意哦,后续抽时间单独整理一篇注意事项吧,篇幅有点长,不继续聊啦; 下篇说说熟悉的缓存穿透、缓存击穿、缓存雪崩吧;
一个被程序搞丑的帅小伙,关注"Code综艺圈",跟我一起学~~~
Redis集群搭建很easy的更多相关文章
- Redis 集群搭建详细指南
先有鸡还是先有蛋? 最近有朋友问了一个问题,说毕业后去大城市还是小城市?去大公司还是小公司?我的回答都是大城市!大公司! 为什么这么说呢,你想一下,无论女孩男孩找朋友都喜欢找个子高胸大的.同样的道理嘛 ...
- redis集群搭建及注意事项
上一篇:redis的安装及注意事项 这里,在一个Linux虚拟机上搭建6个节点的redis伪集群,思路很简单,一台虚拟机上开启6个redis实例,每个redis实例有自己的端口.这样的话,相当于模拟出 ...
- Linux Redis集群搭建与集群客户端实现(Python)
硬件环境 本文适用的硬件环境如下 Linux版本:CentOS release 6.7 (Final) Redis版本: Redis已经成功安装,安装路径为/home/idata/yangfan/lo ...
- [转载] Redis集群搭建最佳实践
转载自http://blog.csdn.net/sweetvvck/article/details/38315149?utm_source=tuicool 要搭建Redis集群,首先得考虑下面的几个问 ...
- Linux Redis集群搭建与集群客户端实现
硬件环境 本文适用的硬件环境如下 Linux版本:CentOS release 6.7 (Final) Redis版本: Redis已经成功安装,安装路径为/home/idata/yangfan/lo ...
- Redis集群搭建-韩国庆
认真一步一步搭建下来,就可以成功.... Redis-cluster集群架构讲解 redis集群专业名词称之为Redis-cluster,redis集群是从3.0版本以后才有的概念,也就是说在3.0之 ...
- redis 集群搭建: redis-cluster
前言 redis数据存储在内存中, 就会受到内存的限制, 大家都知道, 一台电脑, 硬盘可以有1T, 但是内存, 没有听说有1T的内存吧. 那如果数据非常多, 超过一台电脑的内存空间, 怎么办呢? 正 ...
- Redis集群搭建最佳实践
要搭建Redis集群.首先得考虑以下的几个问题; Redis集群搭建的目的是什么?或者说为什么要搭建Redis集群? Redis集群搭建的目的事实上也就是集群搭建的目的.全部的集群主要都是为了解决一个 ...
- Redis集群搭建的三种方式
一.Redis主从 1.1 Redis主从原理 和MySQL需要主从复制的原因一样,Redis虽然读取写入的速度都特别快,但是也会产生性能瓶颈,特别是在读压力上,为了分担压力,Redis支持主从复制. ...
随机推荐
- Javascript函数闭包及案例详解
什么情况下会形成闭包,什么是闭包 闭包(Closure):函数和其周围的状态(词法环境)的引用捆绑在一起形成闭包 可以在另一个作用域中调用一个函数的内部函数并访问到该函数的作用域中的成员 下面来看一个 ...
- cornerstoneTools 作用,用法,api使用心得
一.cornerstoneTools的用途 1.作用可以响应一些事件,例如鼠标按下的事件,鼠标滚轮的事件或按键或触摸事件 2.可以对视口进行缩放平移 3.可以在图像上绘制图形 4.可以在图像上绘制文本 ...
- 从 Java 代码到 CPU 指令
从 Java 代码到 CPU 指令 我们都知道,编写的 Java 代码,最终还是要转化为 CPU 指令才能执行的.为了理解 Java 内存模型的作用,我们首先就来回顾一下从 Java 代码到最终执行的 ...
- int和Integer的区别?包装类?装箱?拆箱?
int和Integer的区别: 1) int是基本数据类型,直接存储的数值,默认是0; 2) Integer 是int的包装类,是个对象,存放的是对象的引用,必须实例化之后才能使用,默认是null; ...
- 断言封装整合到requests封装中应用(纠错False,Result循环,tag测试)
检查json_key_value: 检查: requests.py # -*- coding: utf-8 -*-#@File :demo_04.py#@Auth : wwd#@Time : 2020 ...
- 【Spring Boot】创建一个简单的Spring Boot的 Demo
走进Spring Boot 文章目录 走进Spring Boot 环境搭建 新建Spring Boot项目 开始创建项目 配置JDK版本 和 Initializr Service URL 配置Proj ...
- 2021年正确的Android逆向开发学习之路
2021年正确的Android逆向开发学习之路 说明 文章首发于HURUWO的博客小站,本平台做同步备份发布.如有浏览或访问异常或者相关疑问可前往原博客下评论浏览. 原文链接 2021年正确的Andr ...
- 代码审计 - BugkuCTF
extract变量覆盖: 相关函数: extract()函数:从数组中将变量导入到当前的符号表.把数组键名作为变量名,数组的键值作为变量值.但是当变量中有同名的元素时会默认覆盖掉之前的变量值. tri ...
- C# 合并和拆分PDF文件
一.合并和拆分PDF文件的方式 PDF文件使用了工业标准的压缩算法,易于传输与储存.它还是页独立的,一个PDF文件包含一个或多个"页",可以单独处理各页,特别适合多处理器系统的工作 ...
- 并发编程常用工具类(一) countDownLatch和cyclicBarrier的使用对比
1.CountDownLatch countDownLatch的作用是让一组线程等待其他线程完成工作以后在执行,相当于加强版的join(不懂可以百度一下join的用法),一般在初始 ...