kylin streaming原理介绍与特点浅析
前言
最近搭了Kylin Streaming并初步测试了下,觉得这个东西虽然有些限制,但还是蛮好用的,所以系统写篇文章总结下其原理和一些配置。
Kylin Streaming是Kylin3.0最新引入的一个功能,意为OLAP查询提供亚秒级的数据延迟,即在摄入数据后,立即可以在OLAP查询中体现出来。
用过Kylin应该都知道,它主要是通过预构建的方式,将数据从Hive预先计算然后存储到Hbase。查询的时候一些复杂操作直接转成Hbase的scan和filter操作,大大降低OLAP查询响应时间。
而在比较早版本的Kylin其实是有提供从kafka构建流式应用的,只是那时候走的还是预构建然后存到hbase的路子。这其实是微批的思路,缺点是延迟会比较高(十几分钟级别的延迟)。
这个延迟在某些场景下肯定是无法使用的,所以19年Kylin开始对实时计算这块进行开发,20年5月份时候的kylin3.0.2算是第一个正式可用的streaming版本(另外2020.7.2,kylin3.1.0已发布)。数据源还是kafka,只是现在增加了其他模块已支持亚秒级的数据延迟。
接下来主要从架构说起,再说到底层一些组件的实现方式,最后讨论下一些功能方面的实现以及具体的配置。
kylin streaming设计和原理
架构介绍
kylin streaming在架构上增加了两个模块,可以看看架构图。
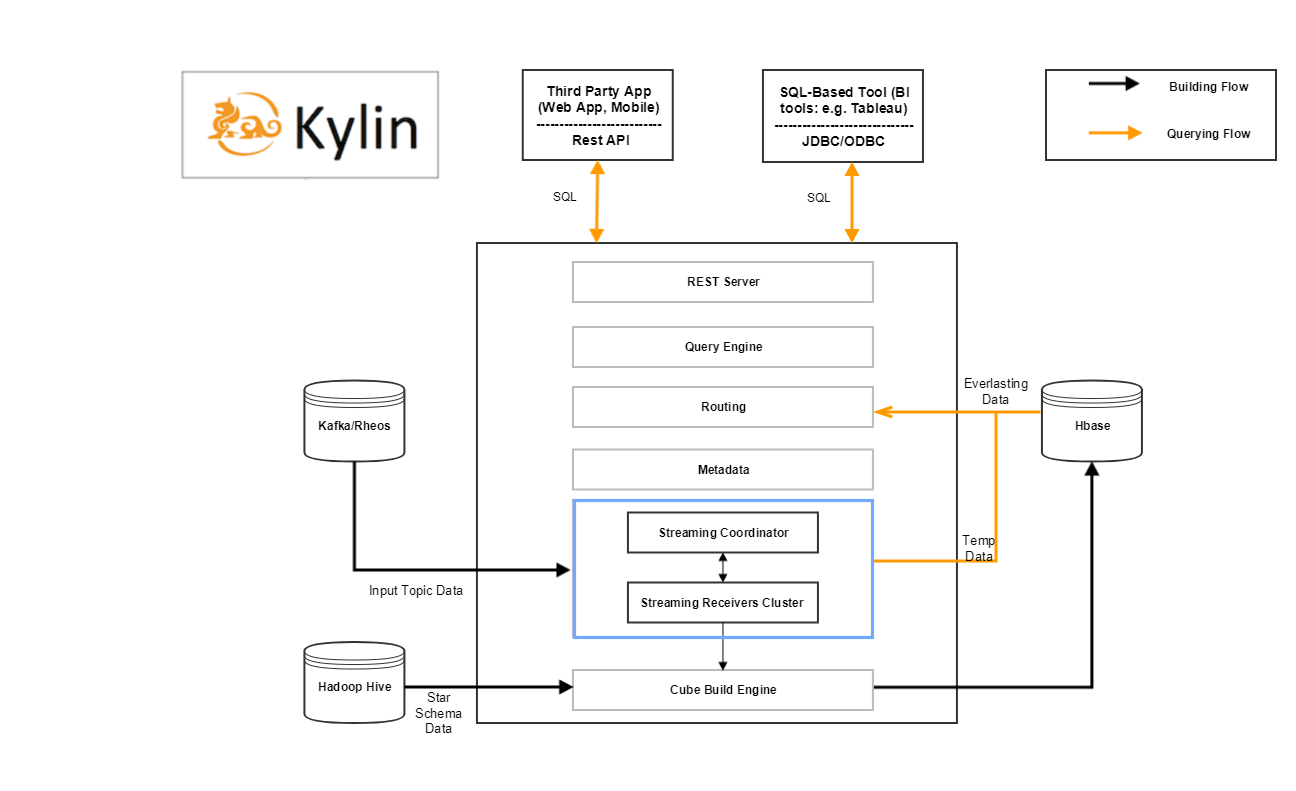
其中蓝色方框内的就是增加的组件内容,那么整个kylin streaming 包含的组件有:
- Kafka Cluster [data source]
- HBase Cluster [historical part storage]
- Zookeeper Cluster [receiver metadata storage]
- MapReduce [distributed computation]
- HDFS [distributed storage]
- Kylin Process [job server/query server/coordinator]
- Kylin streaming receiver Cluster [real-time part computation and storage]
- Query Engine,Build Engine
后面两个就是在kylin streaming中新增加的模块,即streaming coordinator和streaming receiver cluster。其他的还有用于构建源表的kafka,存储数据的Hdfs和Hbase,计算结果用的MapReduce。这里只重点介绍后面两个。
streaming coordinator
streaming coordinator相当于streaming receiver cluster的master,主要负责做一些协调分配工作,比如分配kafka哪个分区的数据分配到哪个streaming receiver的副本,控制消费速率等等。
而具体要指定哪个节点为streaming coordinator,只需要指定kylin.server.mode配置为all(all模式还包含了query server和job server模块)或stream_coordinator就行。另外可以部署多台机器为streaming coordinator以预防单点故障。
streaming receiver cluster
streaming receiver即streaming receiver cluster的worker,被streaming coordinator管理。主要负责:
- 摄入实时数据
- 构建基础的cuboid
- 接收查询请求,根据自身数据执行请求并返回
- 将自己缓存的segment信息持久化到HDFS
另外为了容灾,多个streaming receiver可以组成一个Replica Set。这一个Replica Set中的streaming receiver都会执行同样的任务(即消费同样的kafka分区),它们的作用仅仅是当某个receiver失效的时候可以快速切换。
当然还有Query Engine和Build Engine,即查询引擎和构建引擎,这些都是kylin原先就有的模块。用于执行查询SQL和构建cube。在kylin streaming中,都对原先的模块做了拓展,以支持实时情况下的查询和构建。那么接下来来看看实时情况下构建和查询的流程。
kylin streaming数据构建流程
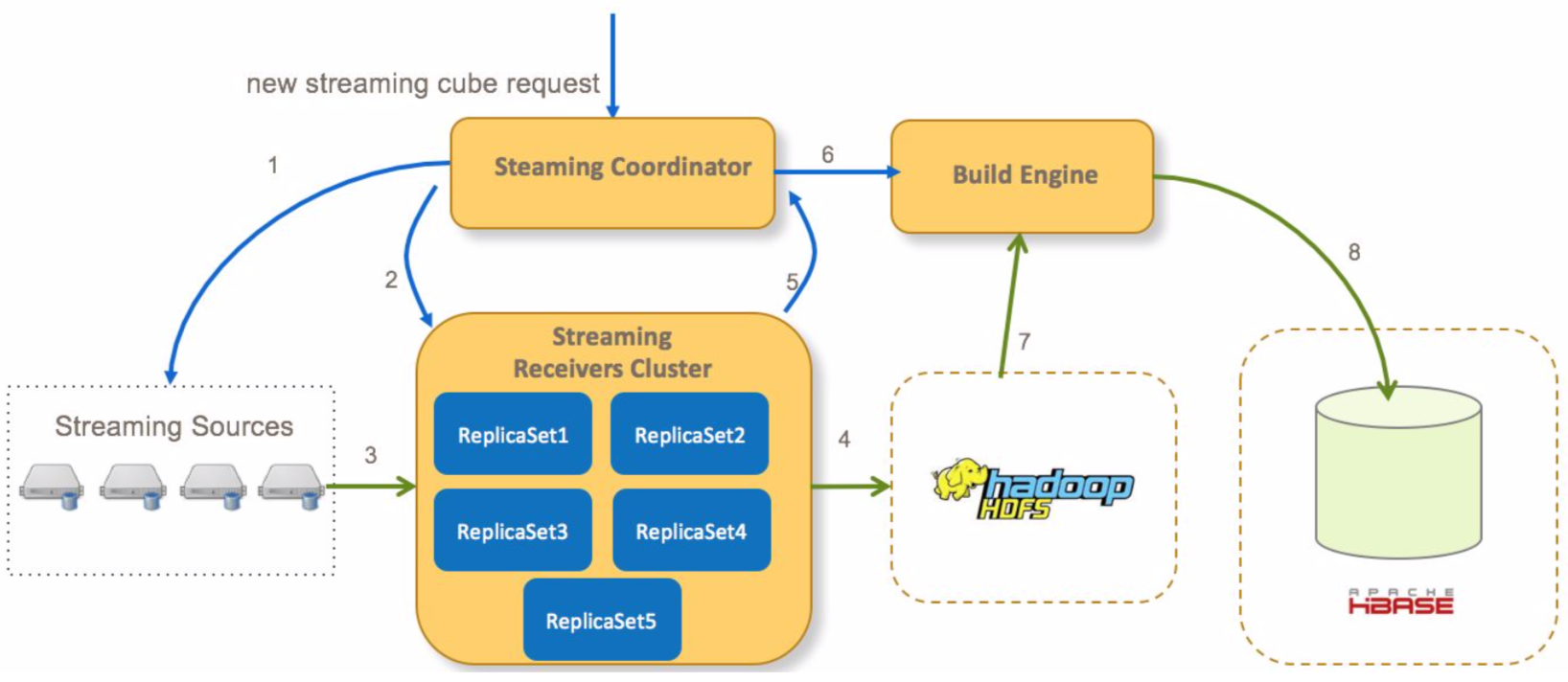
在kylin streaming种,数据会先存储在内存中,经过一定时间后会通过构建cube的方式持久化到hdfs/hbase中,而这里的数据构建流程,则是包含整个数据的生命周期。
这里主要将文档种的内容搬过来,主要流程如下:
- Coordinator向流式cube的所有分区的streaming source发送请求确认信息
- Coordinator分配哪一个receivers消费streaming数据,并向receivers发送请求开始消费数据
- receiver消费数据并构建索引
- 一段时间以后,receiver将immutable状态的segment从本地持久化到hdfs(关于streaming segment状态变更参见下文)
- receiver通知coordinator一个segment已经持久化到hdfs
- 在所有receivers(多个分区)提交其对应segment后,coordinator提交一个全量cube构建任务(在内存中segment只构建最基础的cuboid)到build engine
- build engine从hdfs文件中构建全量的cuboid
- build engine村宁次cuboid数据到hbase,然后coordinator会通知receivers删除本地存储的实时数据
然后接下来再看看查询的流程
kylin streaming查询流程
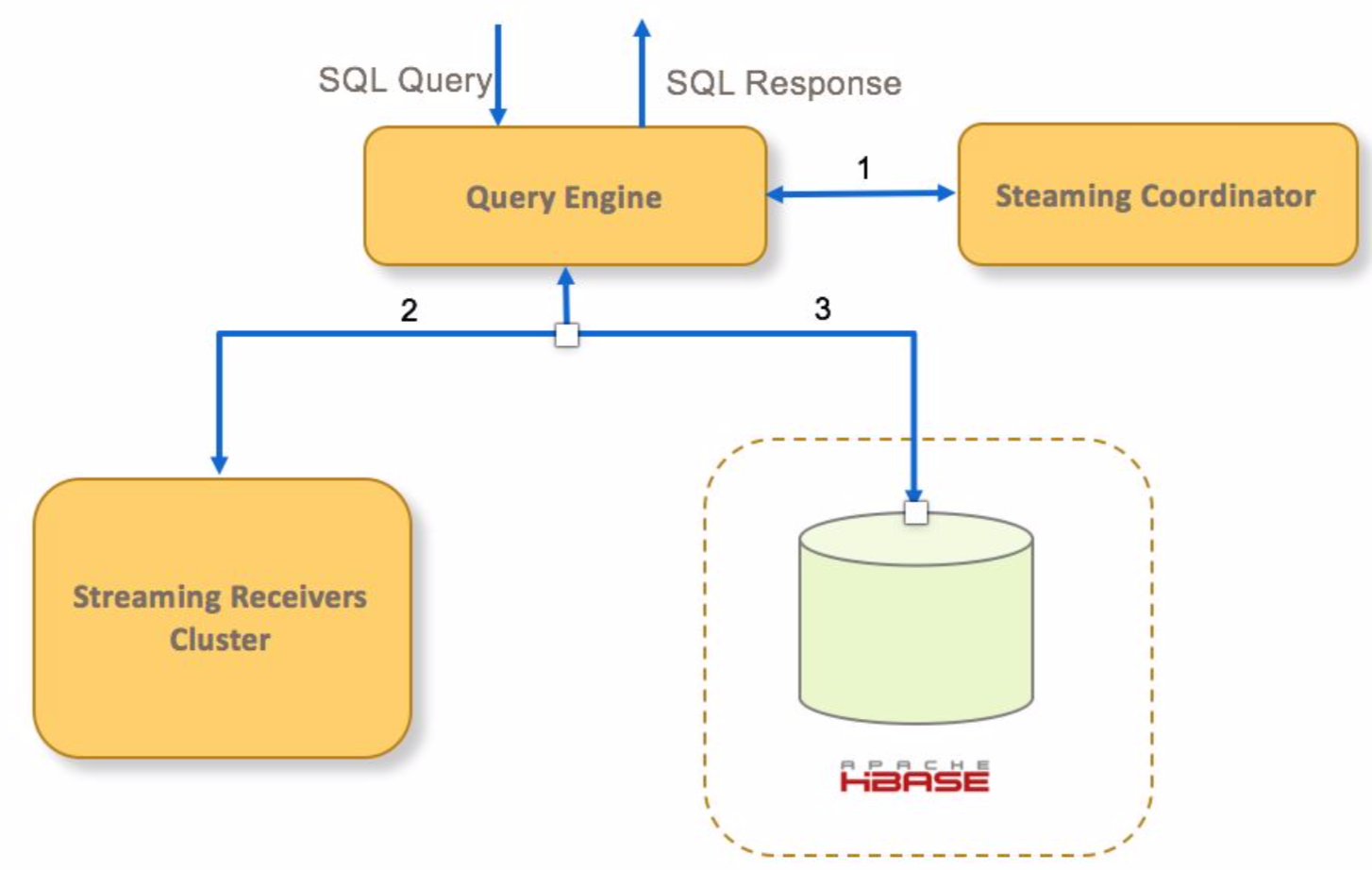
- 如果查询命中一个streaming cube,query engine向cube的receivers的Coordinator发送请求
- query engine发送查询请求到对应的receivers查询实时segment
- query engine发送请求到hbase查询已经持久化的历史segment
- query engine聚合实时和历史数据,然后返回给客户端
以上就是kylin streaming查询引擎和构建引擎的大致流程,接下来再说说一些内部实现细则。
kylin streaming实现细节
kylin streaming segment存储实现
常见的流处理处理的数据时间,通常有两种,包括事件时间(event time),处理时间(process time)。kylin streaming的存储结构是,按照事件时间,将数据存储成一个一个的segment。
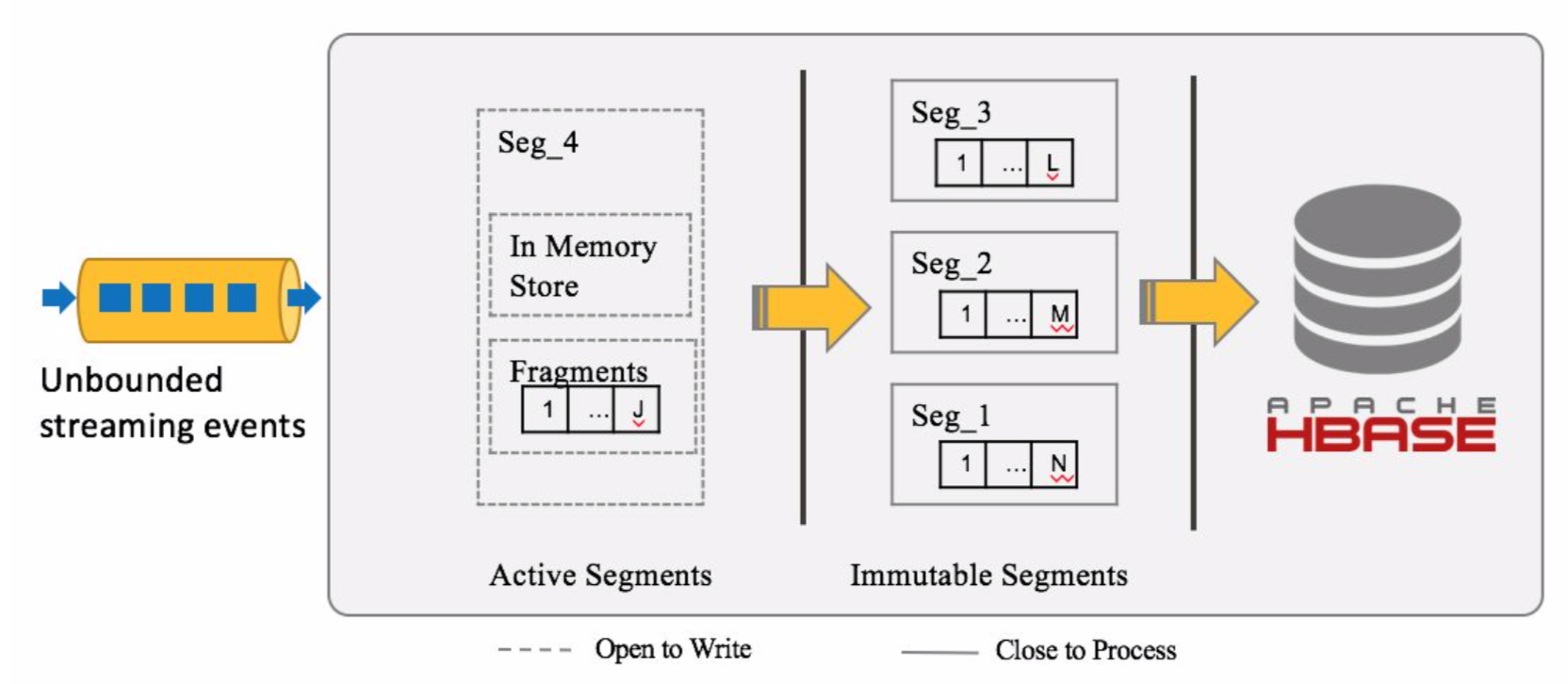
先说下消息接收消息的存储逻辑,当一个消息到达的时候,会根据事件时间查询对应的segment存在否,如果不存在则去创建对应的segment。
而segment在一开始创建的时候,它的状态是Active,但是当一定时间(这个时间根据配置)没有消息到达,该segment的状态就会变成Immutable,然后存储到Hdfs中。
初始的segment是在内存中进行数据聚合和度量计算的(注意receiver只计算基础的coboid和指定的coboid,而非离线数据那样计算全量的cuboid),但是到达一定大小(也是配置)后,会刷到磁盘上存储成fragment文件,而fragment文件到达一定大小后,又会触发merge操作,异步将多个fragment文件进行合并。
其中相同cuboid的数据会存储在同一文件夹下,而metadata则以json格式另外存储。
为了提高查询性能,fragment的存储格式是列式存储格式,如下图所示:
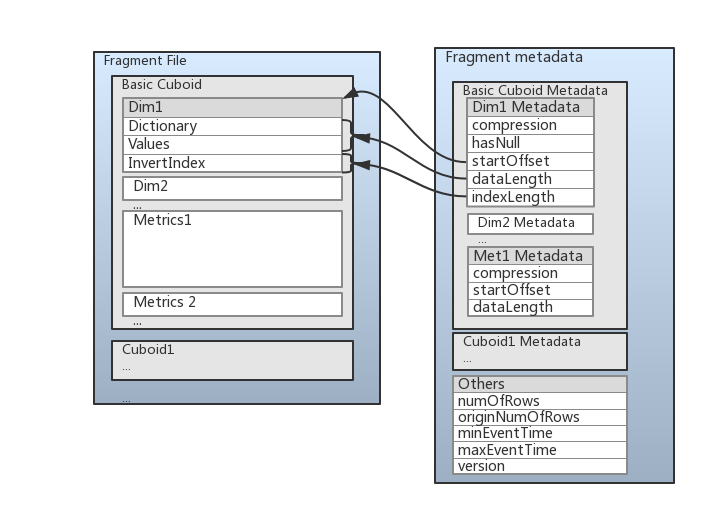
这张图将前面讲到的东西都基本包含了,数据中存储了维度数据(dim)和度量数据(Metrics)。维度数据存储成三个部分数据:
- 第一部分是Dictionary(字典)编码部分,当维度的encoding属性设置为‘Dict’时存在。
- 第二部分则是数据的值/dictionary编码后的值,这部分数据会被压缩。
- 第三部分是倒排索引,存储倒排索引是数据结构是Roaring Bitmap,一种优化过后的bitmap结构。
重平衡/重分配
在某些情况下(比如Kafka消息快速增长),当前的receiver集群可能出现负载不平衡的现象,这时候需要让revicer下线,重平衡以使整个集群负载均衡。
重平衡是自动发生,这个过程可能会持续几秒的时间。
在实际过程中,重平衡是一个从CurrentAssignment状态到NewAssignment状态的过程。 整个重平衡操作是一个分布式事务,可以分为四个步骤。 如果一个步骤失败,将执行自动回滚操作。
主要流程如下:
- 停止当前分配状态(CurrentAssignment)所有Receiver,并且每个Receiver将消费的offset量报告给coordinator,coordinator合并每个分区的偏移量,保留最大偏移量(Replica Set中的Receiver可能消费进度不一样)。然后通知Receiver消费到统一(最大)偏移量,然后再次停止消耗
- coordinator向所有新分配状态(NewAssignment)下的Receiver发送一个分配请求,更新其分配情况。然后coordinator向所有newAssignment的Receiver发送一个startConsumer请求,要求他们根据上一步中的分配情况开始消费。
- 向删除的Replica Set所属的所有接收方发送ImmutableCube请求,要求它们强制将所有segment转换为Immutable segment。
- 更新元数据并将NewAssignment + RemovedAssignment记录到元数据中(已删除的Replica Set仍会接受查询请求,直到重分配完成)
故障恢复
在流处理中,由于数据是无界的,所以故障是不可避免的,哪怕是上面提到的Replica Set,也只能尽可能减少故障影响。所以对付故障的重点并非预防,而实在于如何进行故障恢复。
kylin streaming对故障恢复的做法是在receiver端定期进行checkpoint,这样当receiver故障重启后数据也能正确重新处理(依赖于kafka的上游备份能力)。
而checkpoint主要有两部分内容需要checkpoint,第一部分是消费信息,即kafka的消费offset信息。第二部分则是磁盘数据状态信息,即最新的{segment:framentID}信息。
那么当重启的时候,发现磁盘上的fragment数据比checkpoint记录的磁盘信息数据新怎么办呢?答案是删除没有checkpoint的数据。
kylin streaming优化
首先先来说说Coordinator和Replica Set的数量,在实际生产环境中,为了避免单点故障问题,最好是能够将Coordinator部署两个或以上。而Replica Set的数量则与数据源,即kafka topic的分区数相关。kylin本身提供一个配置,可以让我们指定一个topic全部分区由多少个Replica Set消费,所以Replica Set的数量应该与topic的分区数呈倍数关系或冗余一两个,以便充分利用集群的负载的同时增加容错性。
还有一点,记得前面提到的一个Replica Set由多个Receiver组成吗,所以最好一个Replica Set中配置两个Receiver实例。
下面列举下跟优化相关的一些配置,并且会解释对于配置的作用。
PS:由于kylin streaming模块还处于高速迭代的阶段,有些配置的说明或默认值可能会发生更改,详细还是以官网最新资料为准。
- kylin.stream.receiver.use-threads-per-query:指定每个查询默认的线程数(The parallelism of scan in receiver side),默认是8。可以根据负载和数据情况,适当调大此参数。
- kylin.stream.index.maxrows: 指定了缓存在堆内的聚合后的事件最大行数。默认值是50000。这个参数会影响Fragment File的数量,可以根据需求适当调高。
- kylin.stream.cube-num-of-consumer-tasks: 指定了一个topic的全部消息的摄入将由多少Replica Set来负责,即一个topic的全部分区分配到多少个Replica Set,当然也跟你当前的Replica Set数量有关。如果消息速率较大,需要适当提升这个数值。默认值是3。
- kylin.stream.checkpoint.file.max.num: 指定了Receiver为每一个Cube保留的checkpoint文件数量。默认值是 5。
- kylin.stream.index.checkpoint.intervals: 指定了Receiver进行checkpoint的间隔。默认值是 300秒。有关checkpoint内容请参阅上面介绍。
- kylin.stream.cube.window: 指定了Streaming Segment的时间间隔。比如说[2019-01-01 11:00:00, 2019-01-01 12:00:00]就是一个segment的时间间隔,在这个时间内到达的消息都会归档到这个segment中(当然不能超过配置的大小),默认值是3600。
- kylin.stream.cube.duration: 指定了Streaming Segment会等待迟到的消息多久,默认值7200。接上述的例子,意思是如果一个消息迟到7200秒以内,它还是会被归档到[2019-01-01 11:00:00, 2019-01-01 12:00:00]这个segment中。
- kylin.stream.immutable.segments.max.num: 指定了在Receiver端,一个Cube最多可以保持多少个IMMUTABLE segment,因为Receiver端的性能和Fragment File的数量呈负相关。默认值是 100。
- kylin.stream.segment.retention.policy: 当Segment状态变为IMMUTABLE,该配置指定了Receiver如何处理本地Segment Cache。可选值包含purge和fullBuild。设置为purge后,Receiver会等待一定时间后删除本地数据;设置为fullBuild后,数据会上传到HDFS并等待构建。默认值是fullBuild。
- kylin.stream.consume.offsets.latest:指定了Receiver从什么位置开始消费,设置成true则从最新的offset开始消费,false则从最早的(earliest)位置消费。默认值是 true。
至于上述参数的最佳实践,暂时没有,kylin streaming还是比较新的,可能有些配置还需要不断试错才能知道哪个比较好~
总结
小结一下,本篇简单介绍了kylin streaming的功能,介绍了构建和查询在系统内部的逻辑流程。然后讨论了下kylin streaming在内部的一些实现细节。最后从在配置上说明有哪些点可以进行优化(比较简陋)。
总的来说,kylin streaming继承了kylin的优点,那就是查询快,能容纳大量数据。但缺点也明显,那就是灵活性欠佳,可能改下schema就要重新构建model,cube什么的。
以上~~
参考文章:
Real-time Streaming Design in Apache Kylin
Deep dive into Kylin's Real-time OLAP
kylin streaming原理介绍与特点浅析的更多相关文章
- Spark入门实战系列--7.Spark Streaming(上)--实时流计算Spark Streaming原理介绍
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark Streaming简介 1.1 概述 Spark Streaming 是Spa ...
- 实时流计算Spark Streaming原理介绍
1.Spark Streaming简介 1.1 概述 Spark Streaming 是Spark核心API的一个扩展,可以实现高吞吐量的.具备容错机制的实时流数据的处理.支持从多种数据源获取数据,包 ...
- .Spark Streaming(上)--实时流计算Spark Streaming原理介
Spark入门实战系列--7.Spark Streaming(上)--实时流计算Spark Streaming原理介绍 http://www.cnblogs.com/shishanyuan/p/474 ...
- Kylin系列之二:原理介绍
Kylin系列之二:原理介绍 2018年4月15日 15:52 因何而生 Kylin和hive的区别 1. hive主要是离线分析平台,适用于已经有成熟的报表体系,每天只要定时运行即可. 2. Kyl ...
- 用python + hadoop streaming 编写分布式程序(一) -- 原理介绍,样例程序与本地调试
相关随笔: Hadoop-1.0.4集群搭建笔记 用python + hadoop streaming 编写分布式程序(二) -- 在集群上运行与监控 用python + hadoop streami ...
- typecho流程原理和插件机制浅析(第一弹)
typecho流程原理和插件机制浅析(第一弹) 兜兜 393 2014年03月28日 发布 推荐 5 推荐 收藏 24 收藏,3.5k 浏览 虽然新版本0.9在多次跳票后终于发布了,在漫长的等待里始终 ...
- jQuery内部原理和实现方式浅析
这篇文章主要介绍了jQuery内部原理和实现方式浅析,本文试图从整体来阐述一下jQuery的内部实现,需要的朋友可以参考下 这段时间在学习研究jQuery源码,受益于jQuery日益发展强大,研究jQ ...
- SafeSEH原理及绕过技术浅析
SafeSEH原理及绕过技术浅析 作者:magictong 时间:2012年3月16日星期五 摘要:主要介绍SafeSEH的基本原理和SafeSEH的绕过技术,重点在原理介绍. 关键词:SafeSEH ...
- [Flink原理介绍第四篇】:Flink的Checkpoint和Savepoint介绍
原文:https://blog.csdn.net/hxcaifly/article/details/84673292 https://blog.csdn.net/zero__007/article/d ...
随机推荐
- MFC线程(二):线程同步临界区CRITICAL SECTION
当多个线程同时使用相同的资源时,由于是并发执行,不能保证先后顺序.所以假如时一个公共变量被几个线程同时使用会造成该变量值的混乱. 下面来举个简单例子. 假如有一个字符数组变量 char g_charA ...
- 《JavaScript高级程序设计》(第二版)
这本书的作者是 Nicholas C.Zakas ,博客地址是 http://www.nczonline.net/ ,大家可以去多关注,雅虎的前端工程师,是YUI的代码贡献者,可想而知这本书得含金量, ...
- 循序渐进VUE+Element 前端应用开发(13)--- 前端API接口的封装处理
在前面随笔<循序渐进VUE+Element 前端应用开发(12)--- 整合ABP框架的前端登录处理>介绍了一个系统最初接触到的前端登录处理的实现,但往往对整个系统来说,一般会有很多业务对 ...
- Swoole 中 TCP、UDP 和长连接、短连接
TCP 服务 swoole 文档 - TCP 服务 tcp 服务端 <?php // 1. 创建 swoole 默认创建的是一个同步的阻塞tcp服务 $host = "0.0.0.0& ...
- 新建Maven项目出错
创建完项目后出现 弹出个窗口 出现如下信息 问题: Maven新建项目出现 Could not calculate build plan:plugin 错误解决办法 解决办法: 删除本地.m2仓库中 ...
- Caocao's Bridges HDU - 4738 求桥
题目描述 Caocao was defeated by Zhuge Liang and Zhou Yu in the battle of Chibi. But he wouldn't give up. ...
- 隐写术工具之binwalk
0x00Binwalk介绍 Binwalk是用于搜索给定二进制镜像文件以获取嵌入的文件和代码的工具. 具体来说,它被设计用于识别嵌入固件镜像内的文件和代码. Binwalk使用libmagic库,因此 ...
- C++求树子节点权重最大的和
#include <iostream> #include <vector> using namespace std; int n; const int MaxN = 1e5; ...
- Linux多任务编程之七:Linux守护进程及其基础实验(转)
来源:CSDN 作者:王文松 转自Linux公社 ------------------------------------------------------------------------- ...
- 用PyInstaller打包用PyQt5编写的python程序
0.背景 本弱初学PyQt5,写了一个GUI小程序,但在用PyInstaller打包时出现了不少问题,现将几个比较大的问题记录如下,希望以后能记住. 1. 资源打包 首先是资源打包的问题,我写的程序引 ...