python对离散数据进行编码
机器学习中会遇到一些离散型数据,无法带入模型进行训练,所以要对其进行编码,常用的编码方式有两种:
1、特征不具备大小意义的直接独热编码(one-hot encoding)
2、特征有大小意义的采用映射编码(map encoding)
两种编码在sklearn.preprocessing包里有实现方法
映射编码就是用一个字典指定不同离散型数据对应哪些数字
import pandas as pd
df = pd.DataFrame([
['green', 'M', 10.1, 'label1'],
['red', 'L', 13.5, 'label2'],
['blue', 'XL', 15.3, 'label2']])
# color、label不具备大小含义,size具有大小意义
df.columns = ['color', 'size', 'length', 'label']
size_mapping = {
'XL': 3,
'L': 2,
'M': 1}
df['size'] = df['size'].map(size_mapping)
one-hot编码有两种形式:
1.one-hot编码,又称独热编码、一位有效编码。其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。举个例子,假设我们有四个样本(行),每个样本有三个特征(列),如图:
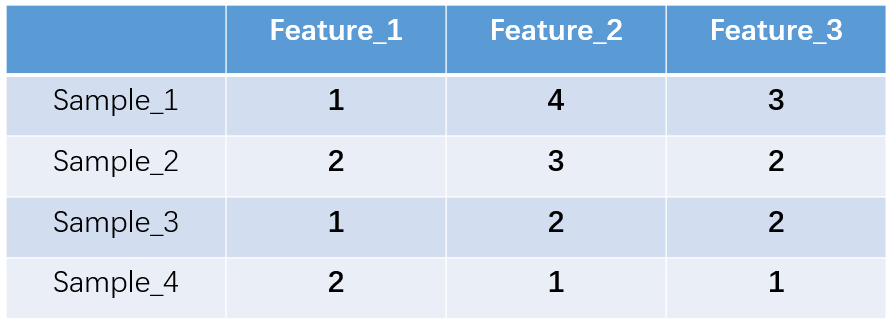
上图中我们已经对每个特征进行了普通的数字编码:我们的feature_1有两种可能的取值,比如是男/女,这里男用1表示,女用2表示。那么one-hot编码是怎么搞的呢?我们再拿feature_2来说明:
这里feature_2 有4种取值(状态),我们就用4个状态位来表示这个特征,one-hot编码就是保证每个样本中的单个特征只有1位处于状态1,其他的都是0。

对于2种状态、三种状态、甚至更多状态都是这样表示,所以我们可以得到这些样本特征的新表示:
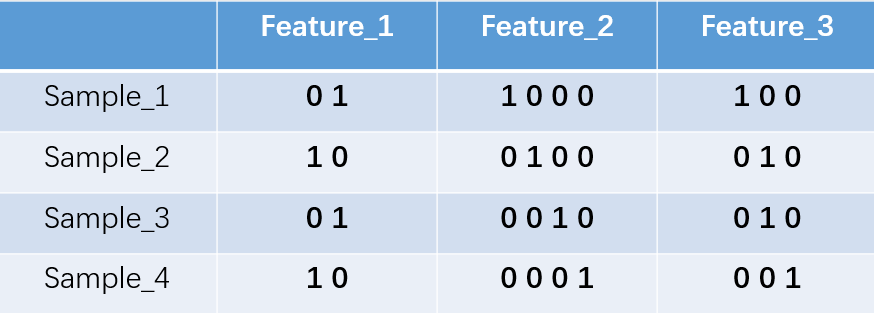
one-hot编码将每个状态位都看成一个特征。对于前两个样本我们可以得到它的特征向量分别为

one-hot在提取文本特征上的应用
one hot在特征提取上属于词袋模型(bag of words)。关于如何使用one-hot抽取文本特征向量我们通过以下例子来说明。假设我们的语料库中有三段话:
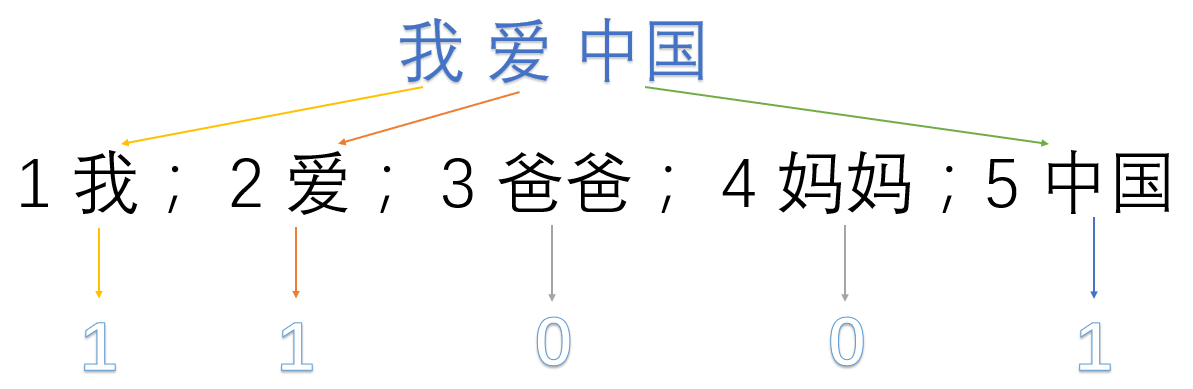
我爱中国
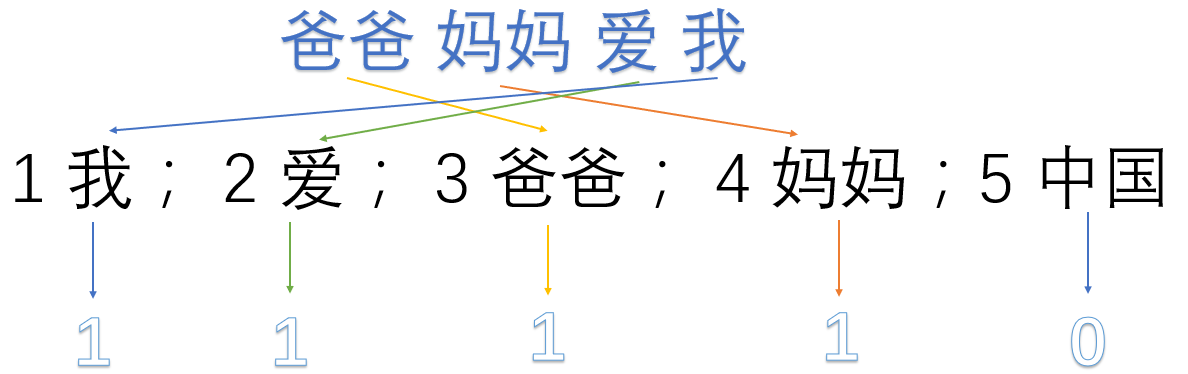
爸爸妈妈爱我
爸爸妈妈爱中国
我们首先对预料库分离并获取其中所有的词,然后对每个此进行编号:
1 我; 2 爱; 3 爸爸; 4 妈妈;5 中国
然后使用one hot对每段话提取特征向量:
 ;
; ;
;
因此我们得到了最终的特征向量为
我爱中国 -> 1,1,0,0,1
爸爸妈妈爱我 -> 1,1,1,1,0
爸爸妈妈爱中国 -> 0,1,1,1,1
优缺点分析
优点:一是解决了分类器不好处理离散数据的问题,二是在一定程度上也起到了扩充特征的作用(上面样本特征数从3扩展到了9)
缺点:在文本特征表示上有些缺点就非常突出了。首先,它是一个词袋模型,不考虑词与词之间的顺序(文本中词的顺序信息也是很重要的);其次,它假设词与词相互独立(在大多数情况下,词与词是相互影响的);最后,它得到的特征是离散稀疏的。
one-hot的基本思想:将离散型特征的每一种取值都看成一种状态,若你的这一特征中有N个不相同的取值,那么我们就可以将该特征抽象成N种不同的状态,one-hot编码保证了每一个取值只会使得一种状态处于“激活态”,也就是说这N种状态中只有一个状态位值为1,其他状态位都是0。举个例子,假设我们以学历为例,我们想要研究的类别为小学、中学、大学、硕士、博士五种类别,我们使用one-hot对其编码就会得到:

2.dummy encoding,哑变量编码直观的解释就是任意的将一个状态位去除。还是拿上面的例子来说,我们用4个状态位就足够反应上述5个类别的信息,也就是我们仅仅使用前四个状态位 [0,0,0,0] 就可以表达博士了。只是因为对于一个我们研究的样本,他已不是小学生、也不是中学生、也不是大学生、又不是研究生,那么我们就可以默认他是博士,是不是。(额,当然他现实生活也可能上幼儿园,但是我们统计的样本中他并不是,^-^)。所以,我们用哑变量编码可以将上述5类表示成:

dummy encoding在pandas中有get_dummies()方法可以实现
python对离散数据进行编码的更多相关文章
- 利用 pandas 进行数据的预处理——离散数据哑编码、连续数据标准化
数据的标准化 数据标准化就是将不同取值范围的数据,在保留各自数据相对大小顺序不变的情况下,整体映射到一个固定的区间中.根据具体的实现方法不同,有的时候会映射到 [ 0 ,1 ],有时映射到 0 附近的 ...
- python --- 06 小数据池 编码
一.小数据池, id() 进行缓存 1.小数据池针对的是: int, str, bool 2.在py文件中几乎所有的字符串都会缓存. 在cmd命令窗口中几乎都不会缓存 不同的解释器有不同 ...
- Python实现——决策树实例(离散数据/香农熵)
决策树的实现太...繁琐了. 如果只是接受他的原理的话还好说,但是要想用代码去实现比较糟心,目前运用了<机器学习实战>的代码手打了一遍,决定在这里一点点摸索一下该工程. 实例的代码在使用上 ...
- Python分析离散心率信号(下)
Python分析离散心率信号(下) 如何使用动态阈值,信号过滤和离群值检测来改善峰值检测. 一些理论和背景 到目前为止,一直在研究如何分析心率信号并从中提取最广泛使用的时域和频域度量.但是,使用的信号 ...
- 使用Python解析JSON数据的基本方法
这篇文章主要介绍了使用Python解析JSON数据的基本方法,是Python入门学习中的基础知识,需要的朋友可以参考下: ----------------------------------- ...
- 详解Google-ProtoBuf中结构化数据的编码
本文的主要内容是google protobuf中序列化数据时用到的编码规则,但是,介绍具体的编码规则之前,我觉得有必要先简单介绍一下google protobuf.因此,本文首先会介绍一些google ...
- python标准库之字符编码详解
codesc官方地址:https://docs.python.org/2/library/codecs.html 相关帮助:http://www.cnblogs.com/huxi/archive/20 ...
- 用python处理文本数据 学到的一些东西
最近写了一个python脚本,用TagMe的api标注文本,并解析返回的json数据.在这个过程中遇到了很多问题,学到了一些新东西,总结一下. 1. csv文件处理 csv是一种格式化的文件,由行和列 ...
- Windows下Python读取GRIB数据
之前写了一篇<基于Python的GRIB数据可视化>的文章,好多博友在评论里问我Windows系统下如何读取GRIB数据,在这里我做一下说明. 一.在Windows下Python为什么无法 ...
随机推荐
- 微信小程序 下拉刷新
<scroll-view class='scroll-view-container' scroll-y="true" bindscrolltolower='scrollToL ...
- LeetCode 049 Anagrams
题目要求:Anagrams Given an array of strings, return all groups of strings that are anagrams. Note: All i ...
- 第8.12节 Python类中使用__dict__定义实例变量和方法
上节介绍了使用实例的__dict__查看实例的自定义属性,其实还可以直接使用__dict__定义实例变量和实例方法. 一. 使用__dict__定义实例变量 语法: 对象名. dict[属性名] = ...
- PyQt(Python+Qt)学习随笔:QTableWidget表格部件中行高和列宽的计算方式
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 QTableWidget表格部件中行高和列宽的计算在Qt提供的资料中内容介绍比较泛,细节说得不清楚, ...
- Java进阶学习之集合与泛型(1)
目录 1.集合 1.1.集合是什么 1.2.集合框架结构 1.2.1.Collection 1.2.2.Map 1.3.集合接口实现类 1.3.1.LinkedList 1.3.2.ArrayList ...
- 懒松鼠Flink-Boot(Flink+Spring):一款将Flink与Spring生态完美融合的脚手架工程
目录 你可能面临如下苦恼: 接口缓存 重试机制 Bean校验 等等...... 它为流计算开发工程师解决了 有了它你的代码就像这样子: 仓库地址:懒松鼠Flink-Boot 1. 组织结构 2. 技术 ...
- 【学习笔记】动态 dp 入门简易教程
序列 dp 引入:最大子段和 给定一个数列 \(a_1, a_2, \cdots, a_n\)(可能为负),求 \(\max\limits_{1\le l\le r\le n}\left\{\sum_ ...
- 题解-[HNOI2016]序列
题解-[HNOI2016]序列 [HNOI2016]序列 给定 \(n\) 和 \(m\) 以及序列 \(a\{n\}\).有 \(m\) 次询问,每次给定区间 \([l,r]\in[1,n]\),求 ...
- MySQL事务提交流程
有binlog的CR方式(重点核心!!): 有binlog情况下,commit动作开始时,会有一个Redo XID 的动作记录写到redo,然后写data到binlog,binlog写成功后,会将bi ...
- 四、Jmeter安装插件
Jmeter安装插件方法和使用 1-下载Jmeter管理jar包 下载地址:https://jmeter-plugins.org/install/Install/ 2-点击下载 plugins-man ...