ceph踩坑日记之rgw_dynamic_resharding
1、背景说明
参考说明:
https://access.redhat.com/documentation/en-us/red_hat_ceph_storage/2/html/object_gateway_guide_for_ubuntu/administration_cli#configuring-bucket-index-sharding
https://ceph.com/community/new-luminous-rgw-dynamic-bucket-sharding/
1.1、问题描述
性能测试中出现性能暴跌(间歇性性能波动),出现一段时间无法写入情况(时延一百多秒)
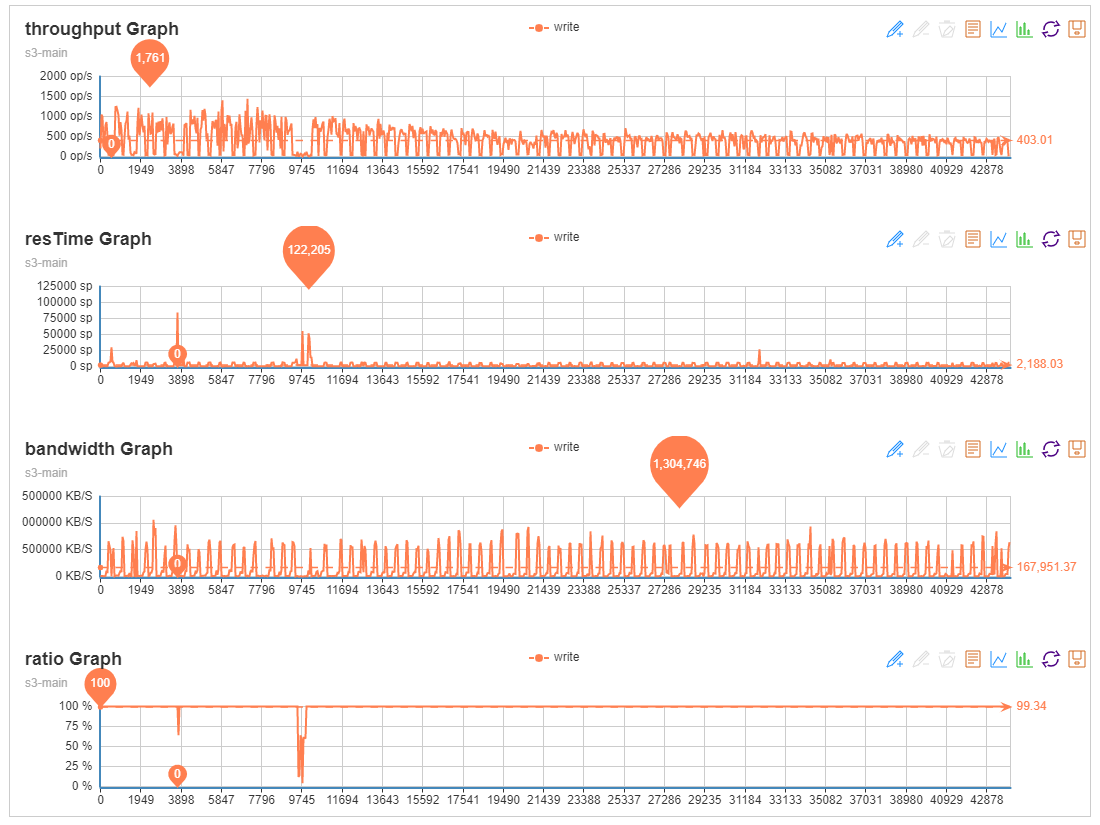
1.2、问题排查
查看rgw日志,发现单桶对象数写入太多,触发自动分片resharding操作
[root@node113 ~]# cat /var/log/ceph/ceph-client.rgw.node113.7480.log | grep reshard
2020-09-16 04:51:50.239505 7fe71d0a7700 0 RGWReshardLock::lock failed to acquire lock on reshard.0000000009 ret=-16
2020-09-16 06:11:56.304955 7fe71d0a7700 0 RGWReshardLock::lock failed to acquire lock on reshard.0000000013 ret=-16
2020-09-16 06:41:58.919390 7fe71d0a7700 0 RGWReshardLock::lock failed to acquire lock on reshard.0000000004 ret=-16
2020-09-16 08:02:00.619906 7fe71d0a7700 0 RGWReshardLock::lock failed to acquire lock on reshard.0000000002 ret=-16
2020-09-16 08:22:01.038502 7fe71d0a7700 0 RGWReshardLock::lock failed to acquire lock on reshard.0000000012 ret=-16
2020-09-16 08:31:58.229956 7fe71d0a7700 0 RGWReshardLock::lock failed to acquire lock on reshard.0000000000 ret=-16
2020-09-16 08:52:06.020018 7fe71d0a7700 0 RGWReshardLock::lock failed to acquire lock on reshard.0000000006 ret=-16
2020-09-16 09:22:12.882771 7fe71d0a7700 0 RGWReshardLock::lock failed to acquire lock on reshard.0000000000 ret=-16查看rgw相关配置,集群每个分片最大存放10w个对象,当前设置每个桶分片数为8,当写入对象数超过80w时,则会触发自动分片操作reshard
[root@node111 ~]# ceph --show-config | grep rgw_dynamic_resharding
rgw_dynamic_resharding = true
[root@node111 ~]# ceph --show-config | grep rgw_max_objs_per_shard
rgw_max_objs_per_shard = 100000
[root@node111 ~]# ceph --show-config | grep rgw_override_bucket_index_max_shards
rgw_override_bucket_index_max_shards = 8
[root@node111 ~]# radosgw-admin bucket limit check
"user_id": "lifecycle01",
"buckets": [
{
"bucket": "cosbench-test-pool11",
"tenant": "",
"num_objects": 31389791,
"num_shards": 370,
"objects_per_shard": 84837,
"fill_status": "OK"
},
{
"bucket": "cycle-1",
"tenant": "",
"num_objects": 999,
"num_shards": 8,
"objects_per_shard": 124,
"fill_status": "OK"
},参数说明
- rgw_dynamic_resharding
[L版官方引入新的参数](https://ceph.com/community/new-luminous-rgw-dynamic-bucket-sharding/,该参数默认开启,当单个bucketfill_status达到OVER 100.000000%时(objects_per_shard > rgw_max_objs_per_shard),动态进行resharding(裂变新的分片,重新均衡数据)这个参数有个致命的缺陷,resharding过程中bucket无法进行读写,因为元数据对象正在重新分散索引,需要保证一致性,同时,数据量越大时间会越来越长
- rgw_override_bucket_index_max_shards
单个bucket创建分片数,默认参数值为0,最大参数值为7877(即单bucket最大写入对象数为7877x100000)
分片数参数计算方式为number of objects expected in a bucket / 100,000,若预估单桶对象数为300w,则分片数设置为30(300w/10w)
示例集群分片数为8,即创建bucket时默认创建8个分片,当每个分片对象数超过10w时,继续resharding创建新的分片,同时重新均衡索引到所有的分片内 - rgw_max_objs_per_shard
单个分片最大存放对象数,默认参数值为10w - rgw_reshard_thread_interval
自动分片线程扫描的间隔,默认为十分钟
1.3、分片说明
- 索引对象
RGW为每个bucket维护一份索引,里边存放了bucket中全部对象的元数据。RGW本身没有足够有效遍历对象的能力,bucket索引影响到对象写入、修改、遍历功能(不影响读)。
bucket索引还有其他用处,比如为版本控制的对象维护日志、bucket配额元数据和跨区同步的日志。
默认情况下,每个bucket只有一个索引对象,索引对象过大会导致以下问题,所以每个bucket所能存储的对象数量有限
--会造成可靠性问题,极端情况下,可能会因为缓慢的数据恢复,导致osd进程挂掉
--会造成性能问题,所有对同一bucket的写操作,都会对一个索引对象进行修改和序列化操作
- bucket分片
Hammer版本以后,新增bucket分片功能用以解决单桶存储大量数据的问题,bucket的索引数据可以分布到多个RADOS对象上,bucket存储对象数量随着索引数据的分片数量增加而增加。
但这只对新增的bucket有效,需要提前根据bucket最终存放数据量规划分片数。当存储桶写入对象超过分片所能承载的最大数时,写入性能暴跌,此时需要手动修改分片数量,以此去承载更多的对象写入。
- 动态bucket分片
Luminous版本以后,新增动态 bucket分片功能,随着存储对象的增加,RADOSGW 进程会自动发现需要进行分片的 bucket,并安排进行自动分片。
2、解决措施
主要分为以下两种情况
2.1、确定单bucket最终写入对象数
关闭动态分片功能(避免调整过程中出现性能暴跌问题),根据最终单bucket写入对象数设置分片数
示例最终单bucket写入对象数为300w,设置分片数为30
追加参数配置在/etc/ceph/ceph.conf配置文件[global]字段内
[root@node45 ~]# cat /etc/ceph/ceph.conf
[global]
rgw_dynamic_resharding = false
rgw_max_objs_per_shard = 30
重启RGW服务进程
[root@node45 ~]# systemctl restart ceph-radosgw.target2.2、不确定单bucket最终写入对象数
不关闭动态分片功能,大概设置一个分片数
追加参数配置在/etc/ceph/ceph.conf配置文件[global]字段内
[root@node45 ~]# cat /etc/ceph/ceph.conf
[global]
rgw_max_objs_per_shard = 8
重启RGW服务进程
[root@node45 ~]# systemctl restart ceph-radosgw.targetceph踩坑日记之rgw_dynamic_resharding的更多相关文章
- AI相关 TensorFlow -卷积神经网络 踩坑日记之一
上次写完粗浅的BP算法 介绍 本来应该继续把 卷积神经网络算法写一下的 但是最近一直在踩 TensorFlow的坑.所以就先跳过算法介绍直接来应用场景,原谅我吧. TensorFlow 介绍 TF是g ...
- 人工智能(AI)库TensorFlow 踩坑日记之一
上次写完粗浅的BP算法 介绍 本来应该继续把 卷积神经网络算法写一下的 但是最近一直在踩 TensorFlow的坑.所以就先跳过算法介绍直接来应用场景,原谅我吧. TensorFlow 介绍 TF是g ...
- hexo博客谷歌百度收录踩坑日记
title: hexo博客谷歌百度收录踩坑日记 toc: false date: 2018-04-17 00:09:38 百度收录文件验证 无论怎么把渲染关掉或者render_skip都说我的格式错误 ...
- Hexo搭建静态博客踩坑日记(二)
前言 Hexo搭建静态博客踩坑日记(一), 我们说到利用Hexo快速搭建静态博客. 这节我们就来说一下主题的问题与主题的基本修改操作. 起步 chrome github hexo git node.j ...
- Hexo搭建静态博客踩坑日记(一)
前言 博客折腾一次就好, 找一个适合自己的博客平台, 专注于内容进行提升. 方式一: 自己买服务器, 域名, 写前端, 后端(前后分离最折腾, 不分离还好一点)... 方式二: 利用Hexo, Hug ...
- JavaScript 新手的踩坑日记
引语 在1995年5月,Eich 大神在10天内就写出了第一个脚本语言的版本,JavaScript 的第一个代号是 Mocha,Marc Andreesen 起的这个名字.由于商标问题以及很多产品已经 ...
- React Native Android配置部署踩坑日记
万事开头难 作为一只进入ECMAScript世界不久的菜鸟,已经被React Native的名气惊到了,开源一周数万星勾起了我浓烈的兴趣.新年新气象,来个HellWorld压压惊吧^_^(故意少打个' ...
- 人工智能(AI)库TensorFlow 踩坑日记之二
上次 踩坑日志之一 遗留的问题终于解决了,所以作者(也就是我)终于有脸出来写第二篇了. 首先还是贴上 卷积算法的示例代码地址 :https://github.com/tensorflow/models ...
- 微信小程序开发踩坑日记
2017.12.29 踩坑记录 引用图片名称不要使用中文,尽量使用中文命名,IDE中图片显示无异样,手机上图片可能出现不显示的情况. 2018.1.5 踩坑记录 微信小程序设置元素满屏,横向直接w ...
随机推荐
- Spring源码系列——容器的启动过程(一)
一. 前言 Spring家族特别庞大,对于开发人员而言,要想全面征服Spring家族,得花费不少的力气.俗话说,打蛇打七寸,那么Spring家族的"七寸"是什么呢?我心目中的答案一 ...
- Spring与Junit测试整合
一.引入spring测试包:text包 二.@RunWith:指定spring对junit提供的一个运行器 @ContextConfiguration: locations指定spring配置文件位 ...
- mysql-5-aggregation
#2.分组函数 /* 分组函数/聚合函数:传入一组值,经过统计处理,得到一个输出值 sum, avg, max, min, count */ USE myemployees; #简单使用 SELECT ...
- Web Storage API的介绍和使用
目录 简介 浏览器的本地存储技术 Web Storage相关接口 浏览器兼容性 隐身模式 使用Web Storage API 总结 简介 Web Storage为浏览器提供了方便的key value存 ...
- c++ 动态库的加载
转载:https://blog.csdn.net/ztq_12345/article/details/99677769 使用ide是vs, 使用Windows.h下的3个函数对动态库进行加载第一个:H ...
- 【题解】CF1290B Irreducible Anagrams
Link 题目大意:对于一个字符串,每次询问一个区间,看看这个区间是不是可以划分为若干区间,这些区间内数字经过排列后可以还原原来区间. \(\text{Solution:}\) 菜鸡笔者字符串构造该好 ...
- 可能是东半球第二好用的软件工具全部在这里(update in 2020.10.09)
1. 产品经理工具种草 浏览器:Google Chrome 网络浏览器 原型绘制软件:墨刀- 在线产品原型设计与协作平台(https://modao.cc/).摹客mockplus - 摹客,让设计和 ...
- golang拾遗:指针和接口
这是本系列的第一篇文章,golang拾遗主要是用来记录一些遗忘了的.平时从没注意过的golang相关知识.想做本系列的契机其实是因为疫情闲着在家无聊,网上冲浪的时候发现了zhuihu上的go语言爱好者 ...
- SpringCache整合Redis
之前一篇文章 SpringBoot整合Redis 已经介绍了在SpringBoot中使用redisTemplate手动 操作redis数据库的方法了.其实这个时候我们就已经可以拿redis来做项目了, ...
- 最新最最最简单的Snagit傻瓜式破解教程(带下载地址)
最新最最最简单的Snagit傻瓜式破解教程(带下载地址) 下载地址 直接滑至文章底部下载 软件介绍 一个非常著名的优秀屏幕.文本和视频捕获.编辑与转换软件.可以捕获Windows屏幕.DOS屏幕:RM ...