机器学习实战基础(三十七):随机森林 (四)之 RandomForestRegressor 重要参数,属性与接口
RandomForestRegressor
class sklearn.ensemble.RandomForestRegressor (n_estimators=’warn’, criterion=’mse’, max_depth=None,
min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=’auto’,
max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, bootstrap=True, oob_score=False,
n_jobs=None, random_state=None, verbose=0, warm_start=False)
所有的参数,属性与接口,全部和随机森林分类器一致。仅有的不同就是回归树与分类树的不同,不纯度的指标,
参数Criterion不一致。
1 重要参数,属性与接口
criterion
回归树衡量分枝质量的指标,支持的标准有三种:
1)输入"mse"使用均方误差mean squared error(MSE),父节点和叶子节点之间的均方误差的差额将被用来作为特征选择的标准,这种方法通过使用叶子节点的均值来最小化L2损失
2)输入“friedman_mse”使用费尔德曼均方误差,这种指标使用弗里德曼针对潜在分枝中的问题改进后的均方误差
3)输入"mae"使用绝对平均误差MAE(mean absolute error),这种指标使用叶节点的中值来最小化L1损失
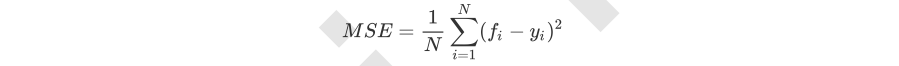
其中N是样本数量,i是每一个数据样本,fi是模型回归出的数值,yi是样本点i实际的数值标签。所以MSE的本质,其实是样本真实数据与回归结果的差异。
在回归树中,MSE不只是我们的分枝质量衡量指标,也是我们最常用的衡量回归树回归质量的指标,当我们在使用交叉验证,或者其他方式获取回归树的结果时,我们往往选择均方误差作为我们的评估(在分类树中这个指标是score代表的预测准确率)。在回归中,我们追求的是,MSE越小越好。
然而,回归树的接口score返回的是R平方,并不是MSE。R平方被定义如下:
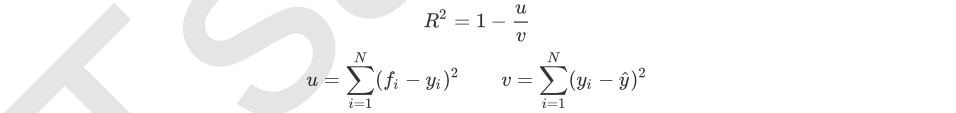
其中u是残差平方和(MSE * N),v是总平方和,N是样本数量,i是每一个数据样本,fi是模型回归出的数值,yi是样本点i实际的数值标签。y帽是真实数值标签的平均数。R平方可以为正为负(如果模型的残差平方和远远大于模型的总平方和,模型非常糟糕,R平方就会为负),而均方误差永远为正。
值得一提的是,虽然均方误差永远为正,但是sklearn当中使用均方误差作为评判标准时,却是计算”负均方误差“(neg_mean_squared_error)。这是因为sklearn在计算模型评估指标的时候,会考虑指标本身的性质,均方误差本身是一种误差,所以被sklearn划分为模型的一种损失(loss),因此在sklearn当中,都以负数表示。真正的均方误差MSE的数值,其实就是neg_mean_squared_error去掉负号的数字。
重要属性和接口
最重要的属性和接口,都与随机森林的分类器相一致,还是apply, fit, predict和score最为核心。值得一提的是,随机森林回归并没有predict_proba这个接口,因为对于回归来说,并不存在一个样本要被分到某个类别的概率问题,因此没有predict_proba这个接口。
随机森林回归用法
和决策树完全一致,除了多了参数n_estimators。
from sklearn.datasets import load_boston
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestRegressor boston = load_boston()
regressor = RandomForestRegressor(n_estimators=100,random_state=0)
cross_val_score(regressor, boston.data, boston.target, cv=10
,scoring = "neg_mean_squared_error") sorted(sklearn.metrics.SCORERS.keys())
返回十次交叉验证的结果,注意在这里,如果不填写scoring = "neg_mean_squared_error",交叉验证默认的模型
衡量指标是R平方,因此交叉验证的结果可能有正也可能有负。而如果写上scoring,则衡量标准是负MSE,交叉验
证的结果只可能为负。
机器学习实战基础(三十七):随机森林 (四)之 RandomForestRegressor 重要参数,属性与接口的更多相关文章
- 机器学习实战基础(十七):sklearn中的数据预处理和特征工程(十)特征选择 之 Embedded嵌入法
Embedded嵌入法 嵌入法是一种让算法自己决定使用哪些特征的方法,即特征选择和算法训练同时进行.在使用嵌入法时,我们先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据权值系数从大 ...
- 机器学习实战基础(三十六):随机森林 (三)之 RandomForestClassifier 之 重要属性和接口
重要属性和接口 至此,我们已经讲完了所有随机森林中的重要参数,为大家复习了一下决策树的参数,并通过n_estimators,random_state,boostrap和oob_score这四个参数帮助 ...
- 机器学习实战基础(三十五):随机森林 (二)之 RandomForestClassifier 之重要参数
RandomForestClassifier class sklearn.ensemble.RandomForestClassifier (n_estimators=’10’, criterion=’g ...
- python机器学习实战(三)
python机器学习实战(三) 版权声明:本文为博主原创文章,转载请指明转载地址 www.cnblogs.com/fydeblog/p/7277205.html 前言 这篇notebook是关于机器 ...
- R语言︱机器学习模型评估方案(以随机森林算法为例)
笔者寄语:本文中大多内容来自<数据挖掘之道>,本文为读书笔记.在刚刚接触机器学习的时候,觉得在监督学习之后,做一个混淆矩阵就已经足够,但是完整的机器学习解决方案并不会如此草率.需要完整的评 ...
- 机器学习实战基础(三十八):随机森林 (五)RandomForestRegressor 之 用随机森林回归填补缺失值
简介 我们从现实中收集的数据,几乎不可能是完美无缺的,往往都会有一些缺失值.面对缺失值,很多人选择的方式是直接将含有缺失值的样本删除,这是一种有效的方法,但是有时候填补缺失值会比直接丢弃样本效果更好, ...
- 机器学习实战基础(二十二):sklearn中的降维算法PCA和SVD(三) PCA与SVD 之 重要参数n_components
重要参数n_components n_components是我们降维后需要的维度,即降维后需要保留的特征数量,降维流程中第二步里需要确认的k值,一般输入[0, min(X.shape)]范围中的整数. ...
- 机器学习实战基础(十四):sklearn中的数据预处理和特征工程(七)特征选择 之 Filter过滤法(一) 方差过滤
Filter过滤法 过滤方法通常用作预处理步骤,特征选择完全独立于任何机器学习算法.它是根据各种统计检验中的分数以及相关性的各项指标来选择特征 1 方差过滤 1.1 VarianceThreshold ...
- 机器学习实战基础(二十七):sklearn中的降维算法PCA和SVD(八)PCA对手写数字数据集的降维
PCA对手写数字数据集的降维 1. 导入需要的模块和库 from sklearn.decomposition import PCA from sklearn.ensemble import Rando ...
随机推荐
- CSS基础之简单介绍
网页诞生初期,没有描述样式的语言,创建了很多用于描述样式的标签.但这些标签破坏了html作为一门结构语言的表现. 于是,W3C在1995年开始起草CSS,提出将结构和样式分离的解决方案. 元素 元素是 ...
- 从零开始的Spring Boot(5、Spring Boot整合Thymeleaf)
Spring Boot整合Thymeleaf 写在前面 从零开始的Spring Boot(4.Spring Boot整合JSP和Freemarker) https://www.cnblogs.com/ ...
- spring Cloud网关之Spring Cloud Gateway
Spring Cloud Gateway是什么?(官网地址:https://cloud.spring.io/spring-cloud-gateway/reference/html/) Spring C ...
- Spring Cloud 系列之 Dubbo RPC 通信
Dubbo 介绍 官网:http://dubbo.apache.org/zh-cn/ Github:https://github.com/apache/dubbo 2018 年 2 月 15 日,阿里 ...
- 为什么Web开发人员在2020年不用最新的CSS功能
转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具.解决方案和服务,赋能开发者. 原文出处:https://dzone.com/articles/why-masses-are-not-usi ...
- cc26a_demo-CppPrimer_动态绑定_多态-代码示范
//多态性 //从派生类到基类的转换 //引用或者指针既可以指向基类对象,也可以指向派生类对象 //只有通过引用或者指针调用虚函数才会发生动态绑定. //为什么定义虚的函数?可 ...
- C# 泛型的基本知识,以及什么是泛型?
1.1 泛型概述 1.1.1 泛型广泛用于容器(collections) 1.1.2 命名空间System.Collections.Generic 1.2 泛型的优点. 以前类型的泛化(general ...
- Java 多线程基础(九)join() 方法
Java 多线程基础(九)join 方法 一.join() 方法介绍 join() 定义 Thread 类中的,作用是:把指定的线程加入到当前线程,可以将两个交替执行的线程合并为顺序执行的线程.如:线 ...
- Github删除分支下所有提交记录
[本文版权归微信公众号"代码艺术"(ID:onblog)所有,若是转载请务必保留本段原创声明,违者必究.若是文章有不足之处,欢迎关注微信公众号私信与我进行交流!] 有时候,我们提交 ...
- weui上传多图片,前端压缩,base64编码
记录一下在做一个报修功能的心路历程,需求功能很简单,一个表单提交,表单包含简单的文字字段以及图片 因为使用的是weui框架,前面的话去找weui的表单和图片上传组件,说实话,weui的组件写的还不错, ...