1. 安装虚拟机,Hadoop和Hive
由于想自学下Hive,所以前段时间在个人电脑上安装了虚拟机,并安装上Hadoop和Hive。接下我就分享下我如何安装Hive的。步骤如下:
- 安装虚拟机
- 安装Hadoop
- 安装Java
- 安装Hive
我这里是在window10系统上安装的用Linux的同学可以直接跳过‘安装虚拟机’这一步,直接参考后续的安装步骤。
一、安装虚拟机
首先,下载VMware并在虚拟机里加入Ubuntu 16.04的镜像文件:
VMware下载链接:https://download3.vmware.com/software/wkst/file/VMware-workstation-full-12.1.0-3272444.exe
Ubuntu 16.04 iso镜像文件安装地址:http://releases.ubuntu.com/xenial/
虚拟机安装及加入操作系统镜像文件的具体步骤可参考:https://blog.csdn.net/qq1326702940/article/details/82322079
接下来,我们需要安装VMware Tools以帮我们进行虚拟机和本地环境之间的沟通(简单来说:你可以拖拽本地文件到虚拟机上,也能复制本地的文本粘贴到虚拟机上)。可以到VMware菜单栏‘虚拟机’选项下‘安装VMware Tools’。
# 由于VMware Tools在光盘里,要复制到进来才能进行安装
cd /media/VMware Tools
tar xvzf VMwareTools-9.6.0-1294478.tar.gz -C /root
cd /root/vmware-tools-distrib
./vmware-install.pl # 开启VMware Tools
cd --
/usr/bin/vmware-user
二、安装Java
Java1.8.0安装地址: https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html
若安装查询java -version时报错 "-bash: /usr/local/java/jdk1.8.0_261/bin/java: cannot execute binary file: 可执行文件格式错误",则是java与Linux系统不匹配,重新下载正确版本的java(32位:x86, 64位:x64)即可。
sudo mkdir /usr/local/java/
sudo cp 桌面/jdk-8u261-linux-i586.tar.gz /usr/local/java/
cd /usr/local/java/
sudo tar -xvzf jdk-8u261-linux-i586.tar.gz
sudo echo "export JAVA_HOME=/usr/local/java/jdk1.8.0_261">/etc/profile.d/java.sh
sudo echo "export PATH=$PATH:$JAVA_HOME/bin">>/etc/profile.d/java.sh
. /etc/profile
echo $JAVA_HOME
# 查看java版本
java -version
三、安装Hadoop
# 下载并解压Hadoop 2.7.7
cd --
wget http://www.us.apache.org/dist/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
tar -xzf hadoop-2.7.7.tar.gz
# 将Hadoop加入环境变量
# 若下面两条命令没有权限,可以sudo gedit 进sh脚本($HOME/.bashrc)里手动加入路径
echo "export HADOOP_HOME=/home/alvinai/hadoop-2.7.7" >> $HOME/.bashrc
echo "export PATH=$PATH:$HADOOP_HOME/bin" >> $HOME/.bashrc
. $HOME/.bashrc # 测试Hadoop
# 查看目录
hadoop dfs -ls
让我们来运行下Hadoop提供的wordcount样例看看:
# 先自定义准备个文本样例数据
mkdir wc-in
echo "bla bla" > wc-in/a.txt
echo "bla wa wa" > wc-in/b.txt # 运行jar文件。用户可以把他们的Map Reduce代码捆绑到jar文件中
hadoop jar /home/alvinai/hadoop-2.7.7/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount wc-in wc-out # 查看wordcount的输出结果
ls wc-out/*
cat wc-out/*
# 也可以等价用dfs命令查看
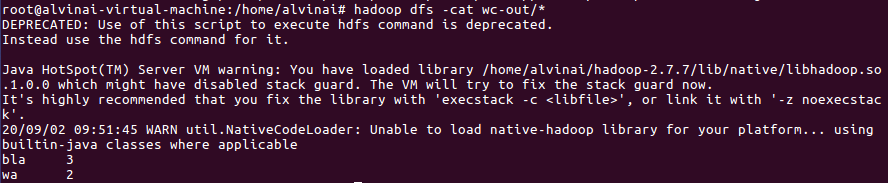
hadoop dfs -cat wc-out/*
wordcount输出结果如下:
四、安装Hive
# 下载并解压Hive 0.9.0
wget http://archive.apache.org/dist/hive/hive-0.9.0/hive-0.9.0.tar.gz
tar -xzf hive-0.9.0.tar.gz
mkdir -p /hive/warehouse
chmod a+rwx /hive/warehouse # 加入环境变量
# 若下面两条命令没有权限,可以sudo gedit 进sh脚本($HOME/.bashrc)里手动加入路径
sudo echo "export HIVE_HOME=/home/alvinai/hive-0.9.0" >> $HOME/.bashrc
sudo echo "export PATH=$PATH:$HIVE_HOME/bin" >> $HOME/.bashrc
现在可以开始使用了Hive了:
以上内容部分摘自于《Hive编程指南》
1. 安装虚拟机,Hadoop和Hive的更多相关文章
- hadoop 安装之 hadoop、hive环境配置
总结了一下hadoop的大致安装过程,按照master . slave的hadoop主从类别,以及root和hadoop集群用户两种角色,以职责图的方式展现,更加清晰一些
- 从VMware虚拟机安装到hadoop集群环境配置详细说明(第一期)
http://blog.csdn.net/whaoxysh/article/details/17755555 虚拟机安装 我安装的虚拟机版本是VMware Workstation 8.04,自己电脑上 ...
- hadoop上hive的安装
1.前言 说明:安装hive前提是要先安装hadoop集群,并且hive只需要再hadoop的namenode节点集群里安装即可(需要再所有namenode上安装),可以不在datanode节点的机器 ...
- 虚拟机Ubuntu(18.04.2)下安装配置Hadoop(2.9.2)(伪分布式+Java8)
[本文结构] [1]安装Hadoop前的准备工作 [1.1] 创建新用户 [1.2] 更新APT [1.3] 安装SSH [1.4] 安装Java环境 [2]安装和配置hadoop [2.1] Had ...
- Windows10系统下Hadoop和Hive开发环境搭建填坑指南
前提 笔者目前需要搭建数据平台,发现了Windows系统下,Hadoop和Hive等组件的安装和运行存在大量的坑,而本着有坑必填的目标,笔者还是花了几个晚上的下班时候在多个互联网参考资料的帮助下完成了 ...
- 使用yum安装CDH Hadoop集群
使用yum安装CDH Hadoop集群 2013.04.06 Update: 2014.07.21 添加 lzo 的安装 2014.05.20 修改cdh4为cdh5进行安装. 2014.10.22 ...
- 《Programming Hive》读书笔记(一)Hadoop和hive环境搭建
<Programming Hive>读书笔记(一)Hadoop和Hive环境搭建 先把主要的技术和工具学好,才干更高效地思考和工作. Chapter 1.Int ...
- 安装atlas后执行hive命令报错
在集群中安装atlas,在安装atlas的节点上执行hive -e "show databases;" 正常,但是在集群中其他节点上执行hive -e "show dat ...
- Centos 7下VMware三台虚拟机Hadoop集群初体验
一.下载并安装Centos 7 传送门:https://www.centos.org/download/ 注:下载DVD ISO镜像 这里详解一下VMware安装中的两个过程 网卡配置 是Add ...
随机推荐
- shell-变量的数值运算-bc-typeset-中括号等方法介绍
1. bc命令的用法: bc是unix下的计算器,它也可以用在命令行下面: 例:给自变量i加1 i=2 i=`echo $i + 1|bc` --------效率低 因为bc支持科学计算 ...
- 多测师讲解自动化测试 _RF关键字001_(上)_高级讲师肖sir
讲解案例1: Open Browser http://www.baidu.com gc #打开浏览器 Maximize Browser Window #窗口最大化 sleep 2 #线程等待2秒 In ...
- 多测师讲解html _段落标签002_高级讲师肖sir
<html> <head> <meta charset="UTF-8"> <title>段落标签</title> < ...
- 多测师讲解python_003.2练习题
# 1.分别打印100以内的所有偶数和奇数并存入不同的列表当中# 2.请写一段Python代码实现删除一个list = [1, 3, 6, 9, 1, 8]# 里面的重复元素不能用set# 3.将字符 ...
- Presto在滴滴的探索与实践
桔妹导读:Presto在滴滴内部发展三年,已经成为滴滴内部Ad-Hoc和Hive SQL加速的首选引擎.目前服务6K+用户,每天读取2PB ~ 3PB HDFS数据,处理30万亿~35万亿条记录,为 ...
- ImageMagick:用identify检查图片是否完整?(jpg/gif/png图片是否损坏)
一,常用图片格式的结束标志是什么? 1,Jpg格式的文件在16进制中的表示是以 ff d9 两个字节结尾 2, gif格式的文件,结尾是 3b 3, png格式的文件,结尾是 00 00 00 ...
- flutter——android报错建议Suggestion: add 'tools:replace="android:label"'
问题: 安装了一个新包,android出现了报错,建议add 'tools:replace="android:label"'. 原因: 项目application的label属性冲 ...
- cgdb安装
cgdb官网:http://cgdb.github.io/ 一.cgdb安装 可使用wget命令下载,wget http://cgdb.me/files/cgdb-0.7.0.tar.gz 之后解压 ...
- mybatis 架构及基础模块
1. mybatis整体架构 基础支撑层详解 1.日志模块 mybatis日志模块没有实现类,需要接入第三方的组件,问题是第三方的组件有各自的log级别,为了能接入第三方组件,mybati日志模块定义 ...
- java面试题:多线程交替输出偶数和奇数
一个面试题:实现两个线程A,B交替输出偶数和奇数 问题:创建两个线程A和B,让他们交替打印0到100的所有整数,其中A线程打印偶数,B线程打印奇数 这个问题配合java的多线程,很多种实现方式 在具体 ...