1. 安装虚拟机,Hadoop和Hive
由于想自学下Hive,所以前段时间在个人电脑上安装了虚拟机,并安装上Hadoop和Hive。接下我就分享下我如何安装Hive的。步骤如下:
- 安装虚拟机
- 安装Hadoop
- 安装Java
- 安装Hive
我这里是在window10系统上安装的用Linux的同学可以直接跳过‘安装虚拟机’这一步,直接参考后续的安装步骤。
一、安装虚拟机
首先,下载VMware并在虚拟机里加入Ubuntu 16.04的镜像文件:
VMware下载链接:https://download3.vmware.com/software/wkst/file/VMware-workstation-full-12.1.0-3272444.exe
Ubuntu 16.04 iso镜像文件安装地址:http://releases.ubuntu.com/xenial/
虚拟机安装及加入操作系统镜像文件的具体步骤可参考:https://blog.csdn.net/qq1326702940/article/details/82322079
接下来,我们需要安装VMware Tools以帮我们进行虚拟机和本地环境之间的沟通(简单来说:你可以拖拽本地文件到虚拟机上,也能复制本地的文本粘贴到虚拟机上)。可以到VMware菜单栏‘虚拟机’选项下‘安装VMware Tools’。
# 由于VMware Tools在光盘里,要复制到进来才能进行安装
cd /media/VMware Tools
tar xvzf VMwareTools-9.6.0-1294478.tar.gz -C /root
cd /root/vmware-tools-distrib
./vmware-install.pl # 开启VMware Tools
cd --
/usr/bin/vmware-user
二、安装Java
Java1.8.0安装地址: https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html
若安装查询java -version时报错 "-bash: /usr/local/java/jdk1.8.0_261/bin/java: cannot execute binary file: 可执行文件格式错误",则是java与Linux系统不匹配,重新下载正确版本的java(32位:x86, 64位:x64)即可。
sudo mkdir /usr/local/java/
sudo cp 桌面/jdk-8u261-linux-i586.tar.gz /usr/local/java/
cd /usr/local/java/
sudo tar -xvzf jdk-8u261-linux-i586.tar.gz
sudo echo "export JAVA_HOME=/usr/local/java/jdk1.8.0_261">/etc/profile.d/java.sh
sudo echo "export PATH=$PATH:$JAVA_HOME/bin">>/etc/profile.d/java.sh
. /etc/profile
echo $JAVA_HOME
# 查看java版本
java -version
三、安装Hadoop
# 下载并解压Hadoop 2.7.7
cd --
wget http://www.us.apache.org/dist/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
tar -xzf hadoop-2.7.7.tar.gz
# 将Hadoop加入环境变量
# 若下面两条命令没有权限,可以sudo gedit 进sh脚本($HOME/.bashrc)里手动加入路径
echo "export HADOOP_HOME=/home/alvinai/hadoop-2.7.7" >> $HOME/.bashrc
echo "export PATH=$PATH:$HADOOP_HOME/bin" >> $HOME/.bashrc
. $HOME/.bashrc # 测试Hadoop
# 查看目录
hadoop dfs -ls
让我们来运行下Hadoop提供的wordcount样例看看:
# 先自定义准备个文本样例数据
mkdir wc-in
echo "bla bla" > wc-in/a.txt
echo "bla wa wa" > wc-in/b.txt # 运行jar文件。用户可以把他们的Map Reduce代码捆绑到jar文件中
hadoop jar /home/alvinai/hadoop-2.7.7/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount wc-in wc-out # 查看wordcount的输出结果
ls wc-out/*
cat wc-out/*
# 也可以等价用dfs命令查看
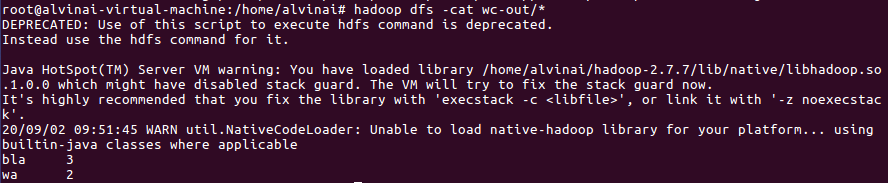
hadoop dfs -cat wc-out/*
wordcount输出结果如下:
四、安装Hive
# 下载并解压Hive 0.9.0
wget http://archive.apache.org/dist/hive/hive-0.9.0/hive-0.9.0.tar.gz
tar -xzf hive-0.9.0.tar.gz
mkdir -p /hive/warehouse
chmod a+rwx /hive/warehouse # 加入环境变量
# 若下面两条命令没有权限,可以sudo gedit 进sh脚本($HOME/.bashrc)里手动加入路径
sudo echo "export HIVE_HOME=/home/alvinai/hive-0.9.0" >> $HOME/.bashrc
sudo echo "export PATH=$PATH:$HIVE_HOME/bin" >> $HOME/.bashrc
现在可以开始使用了Hive了:
以上内容部分摘自于《Hive编程指南》
1. 安装虚拟机,Hadoop和Hive的更多相关文章
- hadoop 安装之 hadoop、hive环境配置
总结了一下hadoop的大致安装过程,按照master . slave的hadoop主从类别,以及root和hadoop集群用户两种角色,以职责图的方式展现,更加清晰一些
- 从VMware虚拟机安装到hadoop集群环境配置详细说明(第一期)
http://blog.csdn.net/whaoxysh/article/details/17755555 虚拟机安装 我安装的虚拟机版本是VMware Workstation 8.04,自己电脑上 ...
- hadoop上hive的安装
1.前言 说明:安装hive前提是要先安装hadoop集群,并且hive只需要再hadoop的namenode节点集群里安装即可(需要再所有namenode上安装),可以不在datanode节点的机器 ...
- 虚拟机Ubuntu(18.04.2)下安装配置Hadoop(2.9.2)(伪分布式+Java8)
[本文结构] [1]安装Hadoop前的准备工作 [1.1] 创建新用户 [1.2] 更新APT [1.3] 安装SSH [1.4] 安装Java环境 [2]安装和配置hadoop [2.1] Had ...
- Windows10系统下Hadoop和Hive开发环境搭建填坑指南
前提 笔者目前需要搭建数据平台,发现了Windows系统下,Hadoop和Hive等组件的安装和运行存在大量的坑,而本着有坑必填的目标,笔者还是花了几个晚上的下班时候在多个互联网参考资料的帮助下完成了 ...
- 使用yum安装CDH Hadoop集群
使用yum安装CDH Hadoop集群 2013.04.06 Update: 2014.07.21 添加 lzo 的安装 2014.05.20 修改cdh4为cdh5进行安装. 2014.10.22 ...
- 《Programming Hive》读书笔记(一)Hadoop和hive环境搭建
<Programming Hive>读书笔记(一)Hadoop和Hive环境搭建 先把主要的技术和工具学好,才干更高效地思考和工作. Chapter 1.Int ...
- 安装atlas后执行hive命令报错
在集群中安装atlas,在安装atlas的节点上执行hive -e "show databases;" 正常,但是在集群中其他节点上执行hive -e "show dat ...
- Centos 7下VMware三台虚拟机Hadoop集群初体验
一.下载并安装Centos 7 传送门:https://www.centos.org/download/ 注:下载DVD ISO镜像 这里详解一下VMware安装中的两个过程 网卡配置 是Add ...
随机推荐
- 调试与优化:一次数据中心看板 T+1 改 T+0 优化过程
背景 团队目前在做一个用户数据看板(下面简称看板),基本覆盖用户的所有行为数据,并生成分析数据,用户行为数据来源于多个数据源(餐饮.生活日用.充值消费.交通出行.通讯物流.交通出行.医疗保健.住房物业 ...
- Windows下使用GitStack搭建Git服务器
Win10下使用GitStack搭建Git服务器 Git是目前世界上最先进的分布式版本控制系统(没有之一). 许多人习惯用复制整个项目目录的方式来保存不同的版本,或许还会改名加上备份时间以示区别. ...
- JavaWeb学习笔记(六)jsp
第六章.jsp 1.什么是jsp jsp:java server pages,java的服务器页面 作用:代替Servlet回传HTML页面的数据 因为Servlet程序回传HTML页面的数据很繁琐, ...
- 解放开发者!3款工具实现快速K8S开发
本文转自Rancher Labs 关注我们,即可第一时间获取K8S教程哦 简 介 时至今日,Kubernetes正在变得越来越重要,不仅仅是运维需要Kubernetes,在开发的世界里Kubernet ...
- 分布式文件存储数据库 MongoDB
MongoDB 简介 Mongo 并非芒果(Mango)的意思,而是源于 Humongous(巨大的:庞大的)一词. MongoDB 是一个基于分布式文件存储的 NoSQL 数据库.由 C++ 语言编 ...
- 如何解决 An error occured executing the Microsoft VC+runtime installer
安装 postgresql 时遇见了 这个问题 There has been an error.An error occured executing the Microsoft VC+ runtim ...
- pyqt5安装后 pyqt-tools却无法安装解决方法!
逛了逛国外论坛 这哥们跟我一样 我一晚上没睡 就为了这个 原来 我的py版本太高级了 我把py3.9卸载了 换上了老旧的3.76版本 成功了
- python接口自动化测试--数据分离读取Excal指定单元格数据
上一篇博客讲了怎么批量读取Excal单元格数据,现在咱们说一下怎么读取Excal指定单元格数据. 一.首先建一个Test_Main类 #!/usr/bin/python # -*- coding: U ...
- 统计学与R语言
书籍推荐 文末见下载链接. 主要有 :统计学习方法.R语言实战.统计学(贾俊平) 链接:百度网盘 提取码:提取码
- JQuery如何实现统计图表
EEP JQuery如何实现统计图表 讯光科技 前言 在ERP项目开发过程中,统计图表(chart)普遍应用于各种统计和报表中,其形象直观,内容清晰.EEP的JQuery网站项目使用了Easyui 插 ...