mxnet笔记
参考链接:
https://mxnet.apache.org/api/faq/distributed_training
https://mxnet.apache.org/api/faq/gradient_compression
https://blog.csdn.net/grgary/article/details/50477738
Github:https://github.com/apache/incubator-mxnet
1、按照参考链接(https://www.jianshu.com/p/45ffeec98401),执行Step1 - Step4;
git clone时如果遇到RPC failed,可以执行git config --global http.postBuffer 524288000
$ cd incubator-mxnet
$ make -j $(nproc) USE_OPENCV=1 USE_BLAS=openblas
在我的电脑上,回报MKLDNN的错误,修改编译命令为make -j $(nproc) USE_OPENCV=1 USE_BLAS=openblas USE_MKLDNN=0 USE_DIST_KVSTORE=1时编译成功。
如果成功的话,即可执行后续操作;反之则根据报错信息查看是否已安装了相关依赖;
2、按照参考链接(https://www.cnblogs.com/huxianhe0/p/10118588.html),执行1.5-1.6,即可安装Python支持并运行MNIST手写体识别实例。
安装Python支持:
$ cd python
$ python setup.py install
运行MNIST手写体识别实例:
$ cd mxnet/example/image-classification
$ python train_mnist.py
每次修改完源码,
make -j $(nproc) USE_OPENCV= USE_BLAS=openblas USE_MKLDNN= USE_DIST_KVSTORE=
cd python && python setup.py install && cd ../
2个server、1个scheduler、2个worker:
export COMMAND='python example/gluon/image_classification.py --dataset cifar10 --model vgg11 --epochs 1 --kvstore dist_sync'
DMLC_ROLE=server DMLC_PS_ROOT_URI=127.0.0.1 DMLC_PS_ROOT_PORT= DMLC_NUM_SERVER= DMLC_NUM_WORKER= $COMMAND &
DMLC_ROLE=server DMLC_PS_ROOT_URI=127.0.0.1 DMLC_PS_ROOT_PORT= DMLC_NUM_SERVER= DMLC_NUM_WORKER= $COMMAND &
DMLC_ROLE=scheduler DMLC_PS_ROOT_URI=127.0.0.1 DMLC_PS_ROOT_PORT= DMLC_NUM_SERVER= DMLC_NUM_WORKER= $COMMAND &
DMLC_ROLE=worker DMLC_PS_ROOT_URI=127.0.0.1 DMLC_PS_ROOT_PORT= DMLC_NUM_SERVER= DMLC_NUM_WORKER= $COMMAND &
DMLC_ROLE=worker DMLC_PS_ROOT_URI=127.0.0.1 DMLC_PS_ROOT_PORT= DMLC_NUM_SERVER= DMLC_NUM_WORKER= $COMMAND
1个server、1个scheduler、1个worker(后续分析采用此设置):
export COMMAND='python example/gluon/image_classification.py --dataset cifar10 --model vgg11 --epochs 1 --kvstore dist_sync'
DMLC_ROLE=server DMLC_PS_ROOT_URI=127.0.0.1 DMLC_PS_ROOT_PORT= DMLC_NUM_SERVER= DMLC_NUM_WORKER= $COMMAND &
DMLC_ROLE=scheduler DMLC_PS_ROOT_URI=127.0.0.1 DMLC_PS_ROOT_PORT= DMLC_NUM_SERVER= DMLC_NUM_WORKER= $COMMAND &
DMLC_ROLE=worker DMLC_PS_ROOT_URI=127.0.0.1 DMLC_PS_ROOT_PORT= DMLC_NUM_SERVER= DMLC_NUM_WORKER= $COMMAND
若要查看节点间交互的流量大小,要在worker上添加PS_VERBOSE=2,具体命令如下:
export COMMAND='python example/gluon/image_classification.py --dataset cifar10 --model vgg11 --epochs 1 --kvstore dist_sync'
DMLC_ROLE=server DMLC_PS_ROOT_URI=127.0.0.1 DMLC_PS_ROOT_PORT= DMLC_NUM_SERVER= DMLC_NUM_WORKER= $COMMAND &
DMLC_ROLE=scheduler DMLC_PS_ROOT_URI=127.0.0.1 DMLC_PS_ROOT_PORT= DMLC_NUM_SERVER= DMLC_NUM_WORKER= $COMMAND &
DMLC_ROLE=worker PS_VERBOSE= DMLC_PS_ROOT_URI=127.0.0.1 DMLC_PS_ROOT_PORT= DMLC_NUM_SERVER= DMLC_NUM_WORKER= $COMMAND
默认情况下不使用梯度压缩,若要使用梯度压缩,需要对代码进行修改:

Technical Implementation
Two Bit Quantization
Currently the supported type of quantization uses two bits for each gradient value. Any positive value greater than or equal to the threshold sets two bits as 11, any negative value whose absolute value is greater or equal to the threshold sets two bits as 10, and others are set to 00. This enables us to store 16 quantized gradients as one float. The error in quantization, which is original_value - quantized_value is stored in the form of a gradient residual.
Types of Kvstore
Supported types of kvstore are device and all distributed kvstores such as dist_sync, dist_async, and dist_sync_device. When kvstore is device, the communication between GPUs is compressed. Please note that this increases the memory usage of GPUs because of the additional residual stored. When using a distributed kvstore, worker-to-server communication is compressed. In this case, compression and decompression happen on the CPU, and gradient residuals will be stored on the CPU. Server-to-worker communication and device-to-device communication are not compressed to avoid multiple levels of compression.
Configuration Details
Threshold
A default threshold value of 0.5 is good for most use cases, but to get the most benefit from gradient compression for a particular scenario, it can be beneficial to experiment. If the threshold is set to a very large value, say 10.0, then the updates become too infrequent and the training will converge slower. Setting the threshold automatically is expected in a future release.
Quantization
This release supports 2-bit quantization for encoding of gradients to reduce the communication bandwidth during training. Future releases will support 1-bit quantization and other approaches for encoding of gradients based on experimental evidence of benefits and user demand.
Sparse Format
We believe that the density of data will need to be really low (i.e. around > 90% zeros) to reap benefits of the sparse format. However, this is an area of experimentation that will be explored in a future release.
一、GC模式下:
常规加密方法(数据类型为float32,4 Bytes):
1、worker(src/kvstore/kvstore_dist.h):
初始化上推:InitImpl() 22次 --- Push_() 22次 --- PushDefault() 22次;
上推:PushImpl() 22次 --- Push_() 22次 --- PushCompressed() 22次;
下拉:PullImpl() 22次;
上推:PushAsync() --- push_to_servers 异步上传,上传buff大小不定 --- ZPush();
下拉:PushAsync() --- pull_from_servers 异步下拉,下拉buff大小不定;
PS:
- Push_() 中 merged.ctx().dev_mask() == cpu::kDevMask;
- 加密操作加入到PushCompressed()中;
- priority从0逐步下降到-21,共22个不同的值;
- 当0 ≤ priority ≤ -20时,comm_buf (4N) --- gradient_compression->Quantize() --- small_buf(N)、res_buf(4N);
- 当priority = -21时,Data Shape=10被压缩到4,压缩比为2.5;
- PushAsync()被包含在PushDefault()与PushCompressed()中,但与其并行执行。
2、server(src/kvstore/kvstore_dist_server.h):
接受初始化上推:DataHandleEx() --- DataHandleDefault() & Initialization 次数与初始化上推次数相同;
接受上推:DataHandleEx() --- DataHandleCompressed() & Synced Push 次数与上推次数相同;
PS:
- DataHandleCompressed()的Synced Push部分加入解密操作,解密后再解压,然后聚合;
- DataHandleCompressed()每次都有decomp_buf.is_none()为True,stored.is_none()为False,merged.request.size() == 0;
- 第一轮的22次DataHandleCompressed()中merged.merged.is_none()为True,否则为False;
- gradient_compression_->Dequantize()前后merged.merged的数据大小未发生变化;
- push_to_servers中的small_buf数据在流量传输中被压缩了4倍,然后流量被DataHandleCompressed()中的recved接受;
- 我们发现,small_buf数据中有效数据主要就是流量传输的部分,占据数据的大约前1/4,余下的都是0;
- 假如设置的阈值是0.5,comm_buf是0.6,那small_buf就是11(代表正数且绝对值超过阈值),而剩下的res_buf是0.1,没有发出去的梯度需要被累积起来,然后在后面发出去。
接受下拉:DataHandleEx() --- DataHandleCompressed() --- DefaultStorageResponse() & Pull 次数与下拉次数相同;
下拉:DefaultStorageResponse()将buff作为服务器的响应,传输给pull_from_servers;
上推(梯度压缩参数设置如下:compression_params = {'type': '2bit', 'threshold': 1e-6}):push_to_servers将small_buf (N) 传输给DataHandleCompressed(),然后解压后累加到merged.merged (4N)。
测试一:
节点间交互的流量大小日志(Push):

服务端接受Push的日志:

测试二:
客户端Push的日志:

服务端接受Push的日志:

结论:客户端Push --- 节点通信 --- 服务端接受Push;服务端的buff数据大小一般是客户端的4倍,且一般是通信流量的16倍(2-bit压缩)。
测试三:
节点间交互的流量大小日志(Pull):
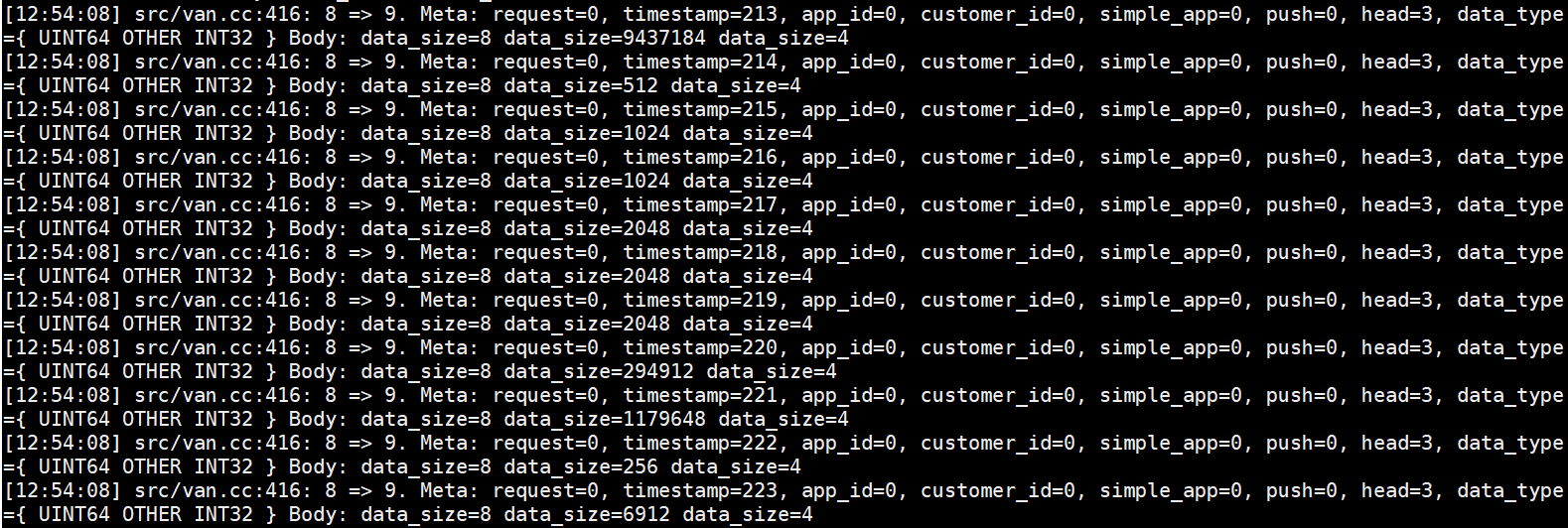
服务端接受Pull的日志:
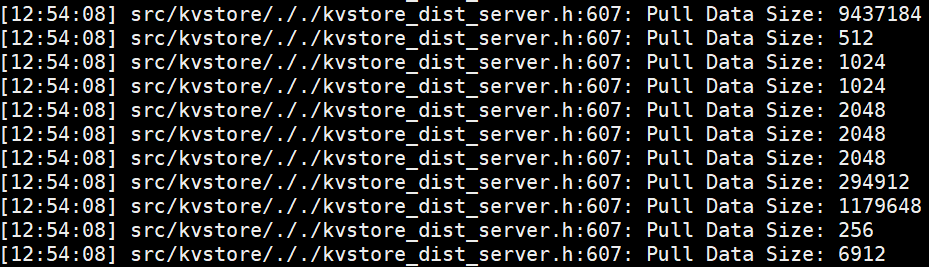
测试四:
客户端Pull的日志:
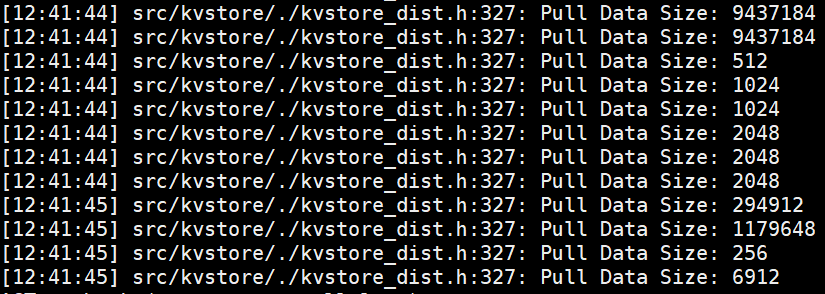
服务端接受Pull的日志:
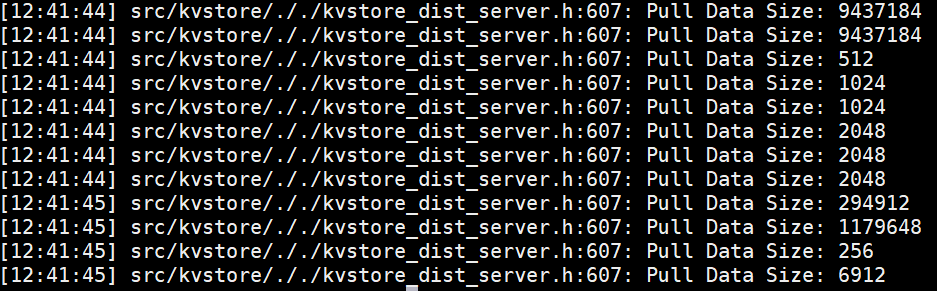
结论:客户端Pull --- 节点通信 --- 服务端接受Pull,客户端与服务端的buff数据大小与通信流量相等。
二、默认模式下:
常规加密方法(数据类型为float32,4 Bytes):
1、worker(src/kvstore/kvstore_dist.h):
初始化上推:InitImpl() 22次 --- Push_() 22次 --- PushDefault() 22次;
上推:PushImpl() 22次 --- Push_() 22次 --- PushDefault() 22次;
下拉:PullImpl() 22次;
上推:PushAsync() --- push_to_servers 异步上传,上传buff大小不定 --- ZPush();
下拉:PushAsync() --- pull_from_servers 异步下拉,下拉buff大小不定;
PS:
- Push_() 中 merged.ctx().dev_mask() == cpu::kDevMask;
- 加密操作加入到PushDefault()中;
- priority从0逐步下降到-21,共22个不同的值;
- PushAsync()被包含在PushDefault()与PushCompressed()中,但与其并行执行。
2、server(src/kvstore/kvstore_dist_server.h):
接受初始化上推:DataHandleEx() --- DataHandleDefault() & Initialization 次数与初始化上推次数相同;
接受上推:DataHandleEx() --- DataHandleDefault() & Synced Push 次数与上推次数相同;
PS:DataHandleDefault()的Synced Push部分加入解密操作,解密后再聚合;
接受下拉:DataHandleEx() --- DataHandleDefault() --- DefaultStorageResponse() & Pull 次数与下拉次数相同;
下拉:DefaultStorageResponse()将buff作为服务器的响应,传输给pull_from_servers;
上推:push_to_servers将传输给DataHandleDefault()。
测试一:
节点间交互的流量大小日志(Push):

服务端接受Push的日志:

测试二:
客户端Push的日志:
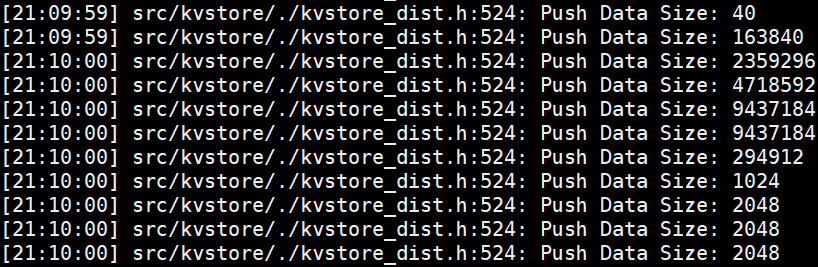
服务端接受Push的日志:

结论:客户端Push --- 节点通信 --- 服务端接受Push,客户端与服务端的buff数据大小与通信流量相等。
测试三:
节点间交互的流量大小日志(Pull):

服务端接受Pull的日志:

测试四:
客户端Pull的日志:

服务端接受Pull的日志:
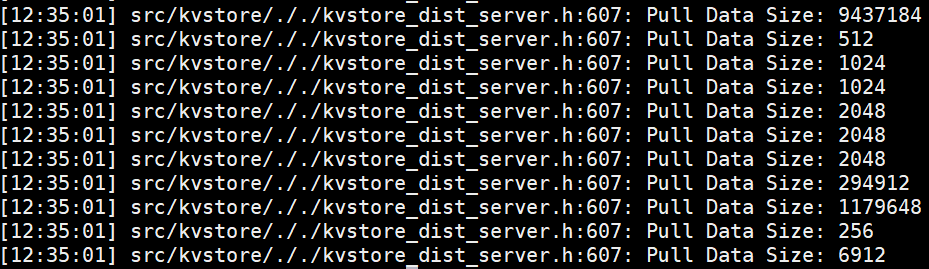
结论:客户端Pull --- 节点通信 --- 服务端接受Pull,客户端与服务端的buff数据大小与通信流量相等。
PushDefault():

float(32 bit):-nan;char(8 bit,(int)操作后的值):0 0 -64 -1;
char a -> b=(int)a b=a (-128 ≤ a ≤ 127);
因此-64的存储形式(补码)为11000000;-1的存储形式为11111111。
由于在X86计算机中,采用的是小端存储方式,即低地址存储低位数据,高地址存储高位数据。
因此,这个float数从高位到低位的值为11111111,11000000,00000000,00000000.
float中的NaN(not a number)的定义为:阶码的每个二进制位全为1,并且尾数不为0;
由于符号位为1,因此这个float数为-nan.

-128的存储形式为10000000;-64的存储形式为11000000。
前一个float的值为11000000,10000000,00000000,00000000,后一个float的值为11000000,11000000,00000000,00000000.
任何一个数都的科学计数法表示都为1.xxx * 2^n,尾数部分就可以表示为xxxx,可以将小数点前面的1省略,所以23bit的尾数部分,可以表示的精度却变成了 24bit。而对于指数部分,因为指数可正可负,8位的指数位能表示的指数范围为:-127-128,所以指数部分的存储采用移位存储,存储的数据为元数据+127。
-4 = -1 * 2^2 = -4,-6 = -(1.1)2 * 2^2 = -1.5 * 4 = -6.
PushCompressed():

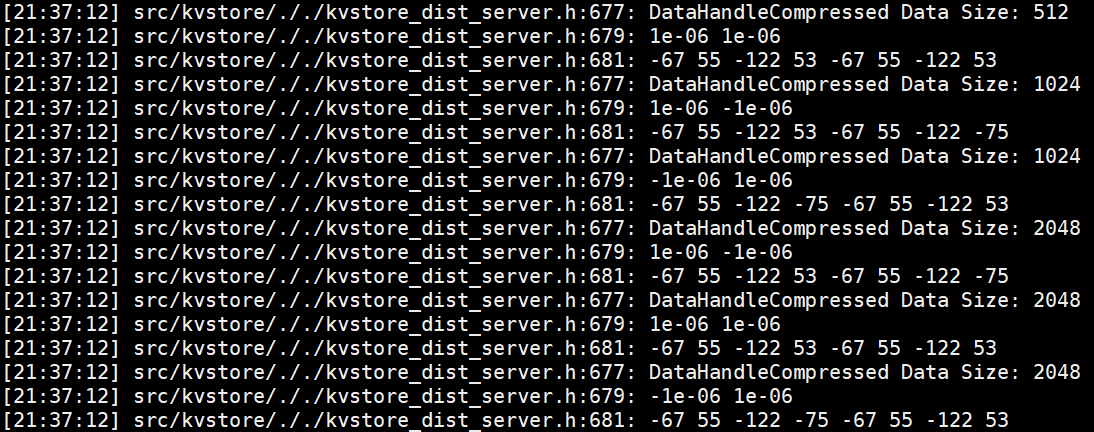
源码分析:
size_t size = small_buf.shape().Size() * mshadow::mshadow_sizeof(dtype);
CHECK_NOTNULL(ps_worker_)->ZPush(pskv.keys, vals, pskv.lens, cmd, [cb]() { cb(); });
我们查看数据得知,pskv.keys.size() = 2,vals.size() = size,pskv.lens.size() = 2;pskv.keys[0] = size,pskv.keys[1] = ps_key,pskv.lens[0] = 0,pskv.lens[1] = comm_buf.shape().Size() / 16 * 4,等价于size / 4;
pskv.keys[1]中存储的ps_key用于将push_pskv与pull_pskv对应起来,详情参见EncodeCompressedKey()函数;
pskv.lens[1]中的16为2-bit压缩比,4为num_bytes。
KVPairs
拥有keys, vals, lens等3个数组。lens和keys大小相等,表示每个key对应的val的个数。lens可为空,此时vals被平分。举例而言,若keys=[1,5],lens=[2,3],那么vals[0],vals[1]就对应的是keys[0],而vals[2],vals[3],vals[4]对应的就是keys[1]。而如果lens为空,则vals.size()必须是keys.size()(此处为2)的倍数,key[0]和key[1]各对应一半的vals。key的值仅用于不同key的区分,或者一些其他用途。
mxnet笔记的更多相关文章
- MXNet设计笔记之:深度学习的编程模式比较
市面上流行着各式各样的深度学习库,它们风格各异.那么这些函数库的风格在系统优化和用户体验方面又有哪些优势和缺陷呢?本文旨在于比较它们在编程模式方面的差异,讨论这些模式的基本优劣势,以及我们从中可以学到 ...
- mxnet源码阅读笔记之include
写在前面 mxnet代码的规范性比Caffe2要好,看起来核心代码量也小很多,但由于对dmlc其它库的依赖太强,代码的独立性并不好.依赖的第三方库包括: cub dlpack dmlc-core go ...
- Mxnet学习笔记(3)--自定义Op
https://blog.csdn.net/u011765306/article/details/54562282 前言 今天因为要用到tile操作(类似np.tile,将数据沿axises进行数据扩 ...
- mxnet深度学习实战学习笔记-9-目标检测
1.介绍 目标检测是指任意给定一张图像,判断图像中是否存在指定类别的目标,如果存在,则返回目标的位置和类别置信度 如下图检测人和自行车这两个目标,检测结果包括目标的位置.目标的类别和置信度 因为目标检 ...
- Windows安装mxnet
code { white-space: pre } div.sourceCode { } table.sourceCode,tr.sourceCode,td.lineNumbers,td.source ...
- tensorflow+入门笔记︱基本张量tensor理解与tensorflow运行结构
Gokula Krishnan Santhanam认为,大部分深度学习框架都包含以下五个核心组件: 张量(Tensor) 基于张量的各种操作 计算图(Computation Graph) 自动微分(A ...
- 机器学习笔记(4):多类逻辑回归-使用gluton
接上一篇机器学习笔记(3):多类逻辑回归继续,这次改用gluton来实现关键处理,原文见这里 ,代码如下: import matplotlib.pyplot as plt import mxnet a ...
- Mxnet学习资源
MxNet 学习笔记(1):MxNet中的NDArray http://mxnet.incubator.apache.org/api/python/symbol/symbol.html api文档 M ...
- 论文笔记:CNN经典结构2(WideResNet,FractalNet,DenseNet,ResNeXt,DPN,SENet)
前言 在论文笔记:CNN经典结构1中主要讲了2012-2015年的一些经典CNN结构.本文主要讲解2016-2017年的一些经典CNN结构. CIFAR和SVHN上,DenseNet-BC优于ResN ...
随机推荐
- Python的条件判断与循环
1.if语句 Python中条件选择语句的关键字为:if .elif .else这三个.其基本形式如下 if condition: blockelif condition: block...else: ...
- Csrf+Xss组合拳
本文首发于“合天智汇”公众号,作者: 影子 各位大师傅,第一次在合天发文章,请多多关照 今年年初的疫情确实有点突然,打乱了上半年的所有计划(本来是校内大佬带我拿奖的时刻,没了 ,学长毕业了,就剩下我这 ...
- centOS7.*安装nginx和简单使用
安装nginx 去官网下载对应的nginx包,推荐使用稳定版本. 上传下载好的包到服务器 安装依赖环境 安装gcc环境. yum install gcc-c++ 安装PCRE库,用于解析正则表达式. ...
- 汇编语言从键盘输入一个字符串(串长不大于80)以十进制输出字符串中非字母字符的个数(不是a to z或 A to Z)
(1)从键盘输入一个字符串(串长不大于80). (2)以十进制输出字符串中非字母字符的个数(不是a to z或 A to Z). (3)输出原字符串且令非字母字符闪烁显示. (4)找出字符串中ASCI ...
- PHP array_merge_recursive() 函数
实例 把两个数组合并为一个数组: <?php$a1=array("a"=>"red","b"=>"green&q ...
- PHP strspn() 函数
实例 返回在字符串 "Hello world!" 中包含字符 "kHlleo" 的数目: <?php高佣联盟 www.cgewang.comecho st ...
- C/C++编程笔记:C语言错误处理方法!如何更好地处理程序的错误?
C语言被忽视的一些小东西!C语言基础教程之错误处理. C 语言不提供对错误处理的直接支持,但是作为一种系统编程语言,它以返回值的形式允许您访问底层数据.在发生错误时,大多数的 C 或 UNIX 函数调 ...
- 4.17 斐波那契数列 K维斐波那契数列 矩阵乘法 构造
一道矩阵乘法的神题 早上的时候我开挂了 想了2h想出来了. 关于这道题我推了很多矩阵 最终推出两个核心矩阵 发现这两个矩阵放在一起做快速幂就行了. 当k==1时 显然的矩阵乘法 多开一个位置维护前缀和 ...
- mysql启动报错,The server quit without updating PID file
环境 MacOS 10.12.2 mysql Ver 14.14 Distrib 5.7.16, for osx10.11 (x86_64) using EditLine wrapper (该部分可跳 ...
- “随手记”开发记录day17
继续开发账单的图形展示这一部分,丰富“随手记”的显示方法,对我们的APP进行添砖加瓦.