NLP文本多标签分类---HierarchicalAttentionNetwork
最近一直在做多标签分类任务,学习了一种层次注意力模型,基本结构如下:

简单说,就是两层attention机制,一层基于词,一层基于句。
首先是词层面:
输入采用word2vec形成基本语料向量后,采用双向GRU抽特征:
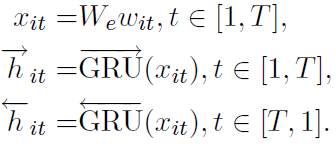
一句话中的词对于当前分类的重要性不同,采用attention机制实现如下:
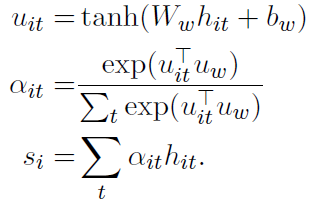
tensorflow代码实现如下:
···
def attention_word_level(self, hidden_state):
"""
input1:self.hidden_state: hidden_state:list,len:sentence_length,element:[batch_size*num_sentences,hidden_size*2]
input2:sentence level context vector:[batch_size*num_sentences,hidden_size*2]
:return:representation.shape:[batch_size*num_sentences,hidden_size*2]
"""
hidden_state_ = tf.stack(hidden_state, axis=1) # shape:[batch_size*num_sentences,sequence_length,hidden_size*2]
# 0) one layer of feed forward network
hidden_state_2 = tf.reshape(hidden_state_, shape=[-1,
self.hidden_size * 2]) # shape:[batch_size*num_sentences*sequence_length,hidden_size*2]
# hidden_state_:[batch_size*num_sentences*sequence_length,hidden_size*2];W_w_attention_sentence:[,hidden_size*2,,hidden_size*2]
hidden_representation = tf.nn.tanh(tf.matmul(hidden_state_2,
self.W_w_attention_word) + self.W_b_attention_word) # shape:[batch_size*num_sentences*sequence_length,hidden_size*2]
hidden_representation = tf.reshape(hidden_representation, shape=[-1, self.sequence_length,
self.hidden_size * 2]) # shape:[batch_size*num_sentences,sequence_length,hidden_size*2]
# attention process:1.get logits for each word in the sentence. 2.get possibility distribution for each word in the sentence. 3.get weighted sum for the sentence as sentence representation.
# 1) get logits for each word in the sentence.
hidden_state_context_similiarity = tf.multiply(hidden_representation,
self.context_vecotor_word) # shape:[batch_size*num_sentences,sequence_length,hidden_size*2]
attention_logits = tf.reduce_sum(hidden_state_context_similiarity,
axis=2) # shape:[batch_size*num_sentences,sequence_length]
# subtract max for numerical stability (softmax is shift invariant). tf.reduce_max:Computes the maximum of elements across dimensions of a tensor.
attention_logits_max = tf.reduce_max(attention_logits, axis=1,
keep_dims=True) # shape:[batch_size*num_sentences,1]
# 2) get possibility distribution for each word in the sentence.
p_attention = tf.nn.softmax(
attention_logits - attention_logits_max) # shape:[batch_size*num_sentences,sequence_length]
# 3) get weighted hidden state by attention vector
p_attention_expanded = tf.expand_dims(p_attention, axis=2) # shape:[batch_size*num_sentences,sequence_length,1]
# below sentence_representation'shape:[batch_size*num_sentences,sequence_length,hidden_size*2]<----p_attention_expanded:[batch_size*num_sentences,sequence_length,1];hidden_state_:[batch_size*num_sentences,sequence_length,hidden_size*2]
sentence_representation = tf.multiply(p_attention_expanded,
hidden_state_) # shape:[batch_size*num_sentences,sequence_length,hidden_size*2]
sentence_representation = tf.reduce_sum(sentence_representation,
axis=1) # shape:[batch_size*num_sentences,hidden_size*2]
return sentence_representation # shape:[batch_size*num_sentences,hidden_size*2]
···
句子层面和词层面基本相同
双向GRU输入,softmax计算attention
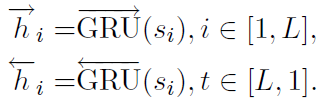
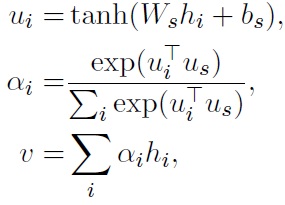
最后基于句子层面的输出,计算分类
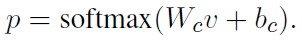
指数损失
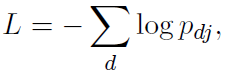
github源代码:https://github.com/zhaowei555/multi_label_classify/tree/master/han
NLP文本多标签分类---HierarchicalAttentionNetwork的更多相关文章
- fastText、TextCNN、TextRNN……这里有一套NLP文本分类深度学习方法库供你选择
https://mp.weixin.qq.com/s/_xILvfEMx3URcB-5C8vfTw 这个库的目的是探索用深度学习进行NLP文本分类的方法. 它具有文本分类的各种基准模型,还支持多标签分 ...
- NLP文本分类方法汇总
模型: FastText TextCNN TextRNN RCNN 分层注意网络(Hierarchical Attention Network) 具有注意的seq2seq模型(seq2seq with ...
- NLP文本分类
引言 其实最近挺纠结的,有一点点焦虑,因为自己一直都期望往自然语言处理的方向发展,梦想成为一名NLP算法工程师,也正是我喜欢的事,而不是为了生存而工作.我觉得这也是我这辈子为数不多的剩下的可以自己去追 ...
- 浅谈NLP 文本分类/情感分析 任务中的文本预处理工作
目录 浅谈NLP 文本分类/情感分析 任务中的文本预处理工作 前言 NLP相关的文本预处理 浅谈NLP 文本分类/情感分析 任务中的文本预处理工作 前言 之所以心血来潮想写这篇博客,是因为最近在关注N ...
- LM-MLC 一种基于完型填空的多标签分类算法
LM-MLC 一种基于完型填空的多标签分类算法 1 前言 本文主要介绍本人在全球人工智能技术创新大赛[赛道一]设计的一种基于完型填空(模板)的多标签分类算法:LM-MLC,该算法拟合能力很强能感知标签 ...
- CSS.02 -- 样式表 及标签分类(块、行、行内块元素)、CSS三大特性、背景属性
样式表书写位置 内嵌式写法 <head> <style type="text/css"> 样式表写法 </style> </head&g ...
- html(常用标签,标签分类),页面模板, CSS(css的三种引入方式),三种引入方式优先级
HTML 标记语言为非编程语言负责完成页面的结构 组成: 标签:被<>包裹的由字母开头,可以结合合法字符( -|数字 ),能被浏览器解析的特殊符号,标签有头有尾 指令:被<>包 ...
- 从零开始学 Web 之 CSS(二)文本、标签、特性
大家好,这里是「 Daotin的梦呓 」从零开始学 Web 系列教程.此文首发于「 Daotin的梦呓 」公众号,欢迎大家订阅关注.在这里我会从 Web 前端零基础开始,一步步学习 Web 相关的知识 ...
- Python-HTML 最强标签分类
编程: 使用(展示)数据 存储数据 处理数据 前端 1. 前端是做什么的? 2. 我们为什么要学前端? 3. 前端都有哪些内容? 1. HTML 2. CSS 3. JavaScript 4.jQue ...
随机推荐
- thinkphp上传图片,生成缩略图
Image.php <?php /** * 实现图片上传,图片缩小, 增加水印 * 需要定义以下常量 * define('ERR_INVALID_IMAGE', 1); * define('ER ...
- Java知识系统回顾整理01基础05控制流程02 switch
一.switch switch 语句相当于 if else的另一种表达方式 switch可以使用byte,short,int,char,String,enum 注: 每个表达式结束,都应该有一个bre ...
- python数据结构之二叉树的建立实例
先建立二叉树节点,有一个data数据域,left,right 两个指针域 # coding:utf-8 class TreeNode(object): def __init__(self,left=N ...
- 洛谷P1450 [HAOI2008]硬币购物 背包+容斥
无限背包+容斥? 观察数据范围,可重背包无法通过,假设没有数量限制,利用用无限背包 进行预处理,因为实际硬币数有限,考虑减掉多加的部分 如何减?利用容斥原理,减掉不符合第一枚硬币数的,第二枚,依次类推 ...
- python实现自动生成小学四则运算题目(软工第二次项目作业)
前言 软件工程 传送带 作业要求 传送带 作业目标 结对编程:代码实现.性能分析.异常处理说明.记录PSP表格 代码见: github 个人信息:朱育清 3118005437 信安二班 我的partn ...
- [java进阶]关于多线程的知识点
线程和进程的区别? 进程: 是程序得一次之星过程,是系统运行程序的基本单位,因此进程是动态的.系统运行一个程序就是从一个进程的创建开始,到进程的结束的过程. 在java中当我们的main函数运行时就是 ...
- 面经手册 · 第13篇《除了JDK、CGLIB,还有3种类代理方式?面试又卡住!》
作者:小傅哥 博客:https://bugstack.cn 沉淀.分享.成长,让自己和他人都能有所收获! 一.前言 编程学习,先铺宽度还是挖深度? 其实技术宽度与技术深度是相辅相成的,你能了解多少技术 ...
- lumen-ioc容器测试 (3)
lumen-ioc容器测试 (1) lumen-ioc容器测试 (2) lumen-ioc容器测试 (3) lumen-ioc容器测试 (4) lumen-ioc容器测试 (5) lumen-ioc容 ...
- Tomcat6.0 支持 https
环境信息 Linux系统 + Tomcat (程序页面可以运行前提下) 条件:安装了JDK 查看指定版本信息 1 进入$JAVA_HOME/bin目录 (一般是这个目录 /usr/java ...
- Vue3 来了,Vue3 开源商城项目重构计划正式启动!
我打算用 Vue3 写一个商城项目,目前已经开始着手开发,测试完成后正式开源到 GitHub,让大家也可以用现成的 Vue3 大型商城项目源码来练练手. Vue 3.0 来了,我们该做些什么? Vue ...