MobileNet——一种模型轻量化方法
导言
新的CNN网络的提出,提高了模型的学习能力但同时也带来了学习效率的降低的问题(主要体现在模型的存储问题和模型进行预测的速度问题),这使得模型的轻量化逐渐得到重视。轻量化模型设计主要思想在于设计更高效的“网络计算方式”(尤其针对卷积方式),从而不损失网络性能的前提下,减少网络计算的参数。本文主要介绍其中的一种——MobileNet[1](顾名思义,是能够在移动端使用的网络模型)。
深度可分离卷积
MobileNet实现模型轻量化的核心是depth-wise separable convolution,可翻译为深度可分离卷积,最早由Sifre在2014年提出[2]。直观上,此方法将CNN中传统卷积方法中的卷积(filtering)和求和(combining)这两个部分,拆分开来,从而极大地减小了网络计算的权值参数数量,提高了计算速度。
具体来讲,假设输入为\(D_F \times D_F \times M\)的特征图F(feature map),其中\(M\)表示输入特征的个数;若步长(stride)为1,且使用padding的话,则可知输出为\(D_F \times D_F \times N\)的特征图,设为G,其中N表示输出特征的个数。
对于传统卷积方法,需要使用\(N\)个$D_K \times D_K \times M $的卷积核,如图(a)所示:
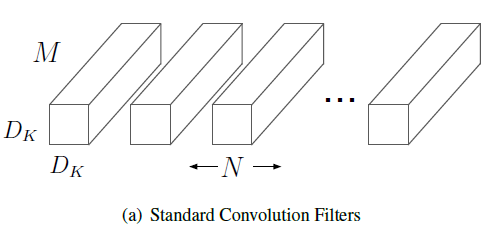
这一卷积过程的数学表达式为:
\]
可以看到计算每个\(G_n\)的时候, 都需要对所有的m进行计算并求和,而深度可分离卷积要做的,正是把(1)式中的m拿出来。
深度可分离卷积将传统的卷积和拆分成了卷积和求和两部分,其卷积核自然也由两部分构成,分别是:Depthwise Convolutional Filters和Pointwise Convolution Filter。
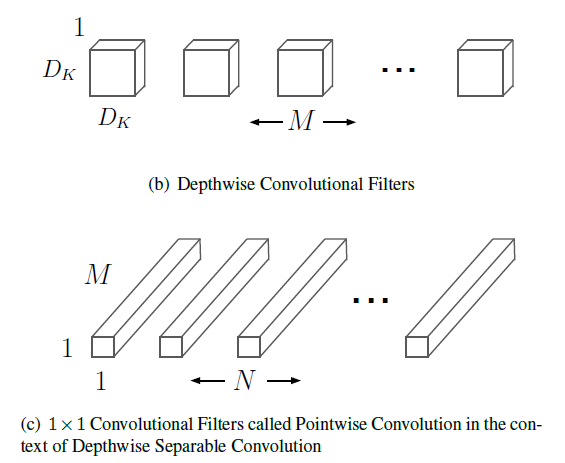
从图(b)(c)中,可以直观地看出,Depthwise Convolutional Filters包含了传统卷积核宽度(\(D_K\))和高度(\(D_k\))以及输入特征数(\(M\))这3个参数,Pointwise Convolution Filter包含了输出特征数(\(N\))这1个参数。原来的4个参数被拆分成3+1,对于计算有何影响呢?这时候,相应的计算式变成了:
\]
\]
(2)式中\(\hat{K}\)表示Depthwise Convolutional Filters卷积核,(3)式中\(\bar{K}\)表示Pointwise Convolution Filter卷积核。为了方便比较,我们把(2)代入(3),得到
\]
比较(1)和(4),可以看出,通过这样的设计,我们成功地拿出了m,把求和号拆成了两部分。为了量化对计算速度提升的效果,我们可以计算前者与后者计算量的比值为:
\]
可见,计算量的减少程度与\(D_K\)和\(N\)正相关,已知MobileNet中Depthwise Convolutional Filters卷积核为\(3\times3\),则随着N取遍大于1的正整数,该比值的变化范围为\((\frac{1}{9},\frac{11}{18}]\),对应的速度提升为\([1.64,9)\),且N越大,则速度提升越明显。
超参数
超参数的设计使得MobileNet能更好的适应不同用户对于速度和精度的需求。MobileNET主要有两个超参数:宽度乘子(Width Multiplier \(\alpha\))和分辨率乘子( Resolution Multiplier \(\rho\)),它们都与网络的卷积计算有着紧密的联系。宽度乘子\(\alpha\)作用于特征数量,对应到图(a)(b)(c)中为卷积核的数量,而分辨率乘子\(\rho\)作用于特征的尺寸,对应图中每个长方体的“横截面积”。更精确地,可以将考虑到超参数的卷积计算量表示如下:
\]
在实际应用中,\(\alpha\)的取值一般为1,0.75,0.5和0.25,而\(\rho\)由选择的分辨率决定,默认的分辨率选择为224,192,160和128。
总结
MobileNet的提出是为了在保证网络性能的前提下,提高计算的速度,推动CNN在移动设备上的应用。这一轻量化模型的核心是利用深度可分离卷积将传统卷积中的卷积与求和两个步骤拆开,对应Depthwise Convolutional Filters和Pointwise Convolution Filter这两个卷积核。模型还提供了宽度乘子和分辨率乘子以平衡不同应用场景下对速度和精度的需求。
MobileNet——一种模型轻量化方法的更多相关文章
- 新上线!3D单模型轻量化硬核升级,G级数据轻松拿捏!
"3D模型体量过大.面数过多.传输展示困难",用户面对这样的3D数据,一定不由得皱起眉头.更便捷.快速处理三维数据,是每个3D用户对高效工作的向往. 在老子云最新上线的单模型轻量化 ...
- 基于WebGL/Threejs技术的BIM模型轻量化之图元合并
伴随着互联网的发展,从桌面端走向Web端.移动端必然的趋势.互联网技术的兴起极大地改变了我们的娱乐.生活和生产方式.尤其是HTML5/WebGL技术的发展更是在各个行业内引起颠覆性的变化.随着WebG ...
- 倾斜摄影3D模型|手工建模|BIM模型 轻量化处理
一.什么是大场景? 顾名思义,大场景就是能够从一个鸟瞰的角度看到一个大型场景的全貌,比如一个园区.一座城市.一个国家甚至是整个地球.但过去都以图片记录下大场景,如今我们可以通过建造3D模型来还原大场景 ...
- Xbim.GLTF源码解析(四):轻量化处理
原创作者:flowell,转载请标明出处:https://www.cnblogs.com/flowell/p/10839433.html 在IFC标准中,由IfcRepresentationMap支持 ...
- 轻量化模型之MobileNet系列
自 2012 年 AlexNet 以来,卷积神经网络在图像分类.目标检测.语义分割等领域获得广泛应用.随着性能要求越来越高,AlexNet 已经无法满足大家的需求,于是乎各路大牛纷纷提出性能更优越的 ...
- 轻量化模型:MobileNet v2
MobileNet v2 论文链接:https://arxiv.org/abs/1801.04381 MobileNet v2是对MobileNet v1的改进,也是一个轻量化模型. 关于Mobile ...
- CNN结构演变总结(二)轻量化模型
CNN结构演变总结(一)经典模型 导言: 上一篇介绍了经典模型中的结构演变,介绍了设计原理,作用,效果等.在本文,将对轻量化模型进行总结分析. 轻量化模型主要围绕减少计算量,减少参数,降低实际运行时间 ...
- 卷积神经网络学习笔记——轻量化网络MobileNet系列(V1,V2,V3)
完整代码及其数据,请移步小编的GitHub地址 传送门:请点击我 如果点击有误:https://github.com/LeBron-Jian/DeepLearningNote 这里结合网络的资料和Mo ...
- 深度学习与CV教程(10) | 轻量化CNN架构 (SqueezeNet,ShuffleNet,MobileNet等)
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/37 本文地址:http://www.showmeai.tech/article-det ...
随机推荐
- IDM下载度盘文件
百度网盘是百度公司推出的一款个人云服务产品.百度网盘官方版操作简单,我们打开后就可以使用该软件来上传.下载文件等.不仅如此百度网盘软件还可以批量上传文件.支持断点传续等功能,重要的是上传的文件不会占用 ...
- 【奇淫巧技】sqlmap绕过过滤的tamper脚本分类汇总
sqlmap绕过过滤的tamper脚本分类汇总
- 对于dijkstra最短路算法的复习
好久没有看图论了,就从最短路算法开始了. dijkstra算法的本质是贪心.只适用于不含负权的图中.因为出现负权的话,贪心会出错. 一般来说,我们用堆(优先队列)来优化,将它O(n2)的复杂度优化为O ...
- Tensorflow学习笔记No.4.1
使用CNN卷积神经网络(1) 简单介绍CNN卷积神经网络的概念和原理. 已经了解的小伙伴可以跳转到Tensorflow学习笔记No.4.2学习如和用Tensorflow实现简单的卷积神经网络. 1.C ...
- appium 环境安装指引
1.安装Appium-Python-Client Pip install Appium-Python-Client 2.安装nodejs https://nodejs.org/ 安装成功验证:node ...
- Black-Lives-Matter-Resources
下载 Black-Lives-Matter-ResourcesBlack-Lives-Matter-Resources 关于最近在美国发生的事件的资源列表 链接 描述 由于(可选) 插入链接 在这里插 ...
- @FeignClient注解详解
Spring Cloud 是目前最火的微服务框架,Feign 作为基础组件之一,在 Spring Cloud 体系中发挥了重要的作用. 一.FeignClient注解 FeignClient注解被@T ...
- ansible-playbook-roles目录结构
1. ansible-角色-roles目录结构 角色是基于已知文件结构自动加载某些vars_files,任务和处理程序的方法.按角色对内容进行分组还可以轻松与其他用户共享角色. ...
- Go语言中Goroutine与线程的区别
1.什么是Goroutine? Goroutine是建立在线程之上的轻量级的抽象.它允许我们以非常低的代价在同一个地址空间中并行地执行多个函数或者方法.相比于线程,它的创建和销毁的代价要小很多,并且它 ...
- django环境安装与项目创建方式
1.安装django pip install django2.检查django版本 : python -m django --version 3.创建项目 django-admin startproj ...