kafka学习之三_信创CPU下单节点kafka性能测试验证
kafka学习之三_信创CPU下单节点kafka性能测试验证
背景
前面学习了 3controller+5broker 的集群部署模式.
晚上想着能够验证一下国产机器的性能. 但是国产机器上面的设备有限.
所以想着进行单节点的安装与测试. 并且记录一下简单结果
希望对以后的工作有指导意义
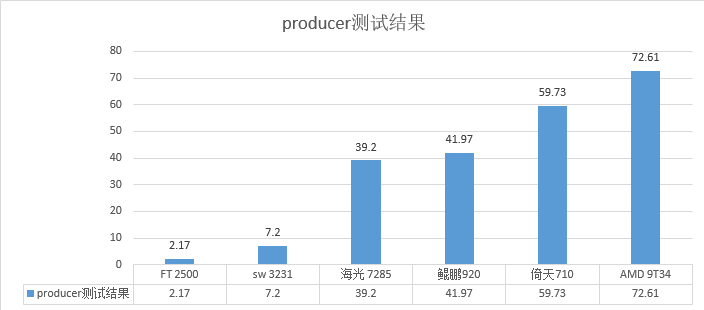
发现producer的性能比较与之前的 测试结果比较接近.
但是consumer的测试结果看不出太多头绪来.
自己对kafka的学习还不够深入, 准备下一期就进行consumer的调优验证.
测试结果验证
| CPU类型 | producer测试结果 | consumer测试结果 |
|---|---|---|
| sw 3231 | 7.20 MB/sec | 2.62 MB/sec |
| FT 2500 | 2.17 MB/sec | 测试失败 |
| 海光 7285 | 39.20 MB/sec | 5.77 MB/sec |
| 鲲鹏920 | 41.97 MB/sec | 5.6037 MB/sec |
| 倚天710 | 59.73 MB/sec | 6.19 MB/sec |
| AMD 9T34 | 72.61 MB/sec | 6.68 MB/sec |
测试结果
广告一下自己的公众号

以申威为例进行安装说明
因为kafka 其实是基于java进行编写的消息队列.
所以不需要有繁杂的编译等过程.
只要jdk支持, 理论上就可以进行运行.
比较麻烦的就是稳定性和性能的表现.
所以这里进行一下安装与验证.
安装过程-1
上传文件到/root目录下面并且解压缩
cd /root && tar -zxvf kafka_2.13-3.5.0.tgz
然后编辑对应的文件:
cat > /root/kafka_2.13-3.5.0/config/kafka_server_jaas.conf <<EOF
KafkaServer {
org.apache.kafka.common.security.plain.PlainLoginModule required
username="admin"
password="Testxxxxxx"
user_admin="Testxxxxxx"
user_comsumer="Testxxxxxx"
user_producer="Testxxxxxx";
};
EOF
# 增加一个客户端配置文件 客户端才可以连接服务器端
cat > /root/kafka_2.13-3.5.0/config/sasl.conf <<EOF
sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="admin" password="Testxxxxxx";
security.protocol=SASL_PLAINTEXT
sasl.mechanism=PLAIN
EOF
安装过程-2
vim /root/kafka_2.13-3.5.0/config/kraft/server.properties
主要修改的点:
因为是单节点所以比较简单了:
process.roles=broker,controller
node.id=100
controller.quorum.voters=100@127.0.0.1:9094
listeners=SASL_PLAINTEXT://127.0.0.1:9093,CONTROLLER://127.0.0.1:9094
sasl.enabled.mechanisms=PLAIN
sasl.mechanism.inter.broker.protocol=PLAIN
security.inter.broker.protocol=SASL_PLAINTEXT
allow.evervone.if.no.acl.found=true
advertised.listeners=SASL_PLAINTEXT://127.0.0.1:9093
# 最简单的方法可以删除配置文件的前面 50行, 直接放进去这些内容
vim->:1,50d->paste->edit_ips
其他ip地址可以如此替换:
sed -i 's/127.0.0.1/10.110.136.41/g' /root/kafka_2.13-3.5.0/config/kraft/server.properties
安装过程-3
修改启动脚本:
vim /root/kafka_2.13-3.5.0/bin/kafka-server-start.sh
在任意一个java opt 处增加:
-Djava.security.auth.login.config=/root/kafka_2.13-3.5.0/config/kafka_server_jaas.conf
安装过程-4
# 初始化
/root/kafka_2.13-3.5.0/bin/kafka-storage.sh random-uuid
cd /root/kafka_2.13-3.5.0
bin/kafka-storage.sh format -t 7ONT3dn3RWWNCZyIwLrEqg -c config/kraft/server.properties
# 启动服务
cd /root/kafka_2.13-3.5.0 && bin/kafka-server-start.sh -daemon config/kraft/server.properties
# 创建topic
bin/kafka-topics.sh --create --command-config config/sasl.conf --replication-factor 1 --partitions 3 --topic zhaobsh01 --bootstrap-server 127.0.0.1:9093
# 测试producer
bin/kafka-producer-perf-test.sh --num-records 100000 --record-size 1024 --throughput -1 --producer.config config/sasl.conf --topic zhaobsh01 --print-metrics --producer-props bootstrap.servers=127.0.0.1:9093
# 测试consumer
bin/kafka-consumer-perf-test.sh --fetch-size 10000 --messages 1000000 --topic zhaobsh01 --consumer.config config/sasl.conf --print-metrics --bootstrap-server 127.0.0.1:9093
# 查看日志
tail -f /root/kafka_2.13-3.5.0/logs/kafkaServer.out
申威的测试结果
producer:
100000 records sent, 7370.283019 records/sec (7.20 MB/sec), 2755.49 ms avg latency, 3794.00 ms max latency, 3189 ms 50th, 3688 ms 95th, 3758 ms 99th, 3785 ms 99.9th.
consumer:
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec, rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec
2023-06-20 21:56:02:493, 2023-06-20 21:56:39:755, 97.6563, 2.6208, 100000, 2683.6992, 5599, 31663, 3.0842, 3158.2604
飞腾的测试结果-hdd
producer:
100000 records sent, 1828.922582 records/sec (1.79 MB/sec), 6999.20 ms avg latency, 51476.00 ms max latency, 875 ms 50th, 21032 ms 95th, 21133 ms 99th, 21167 ms 99.9th.
consumer:
飞腾的测试结果-ssd
producer:
100000 records sent, 2219.706555 records/sec (2.17 MB/sec), 7073.51 ms avg latency, 41100.00 ms max latency, 1089 ms 50th, 20816 ms 95th, 20855 ms 99th, 20873 ms 99.9th.
海光的测试结果
producer:
100000 records sent, 40144.520273 records/sec (39.20 MB/sec), 486.67 ms avg latency, 681.00 ms max latency, 456 ms 50th, 657 ms 95th, 674 ms 99th, 678 ms 99.9th.
consumer:
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec, rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec
2023-06-20 22:28:04:364, 2023-06-20 22:28:21:274, 97.6563, 5.7751, 100000, 5913.6606, 3809, 13101, 7.4541, 7633.0051
鲲鹏的测试结果
producer:
100000 records sent, 42973.785991 records/sec (41.97 MB/sec), 463.69 ms avg latency, 621.00 ms max latency, 472 ms 50th, 593 ms 95th, 612 ms 99th, 619 ms 99.9th.
consumer:
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec, rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec
2023-06-20 22:33:58:168, 2023-06-20 22:34:15:595, 97.6563, 5.6037, 100000, 5738.2223, 3799, 13628, 7.1659, 7337.8339
倚天的测试结果
producer:
100000 records sent, 61162.079511 records/sec (59.73 MB/sec), 335.18 ms avg latency, 498.00 ms max latency, 326 ms 50th, 476 ms 95th, 494 ms 99th, 497 ms 99.9th.
consumer:
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec, rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec
2023-06-20 22:37:49:668, 2023-06-20 22:38:05:426, 97.6563, 6.1972, 100000, 6345.9830, 3597, 12161, 8.0303, 8223.008
AMD9T34的测试结果
producer:
100000 records sent, 74349.442379 records/sec (72.61 MB/sec), 253.07 ms avg latency, 364.00 ms max latency, 259 ms 50th, 344 ms 95th, 359 ms 99th, 363 ms 99.9th.
consumer:
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec, rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec
2023-06-20 22:44:14:446, 2023-06-20 22:44:29:058, 97.6563, 6.6833, 100000, 6843.6901, 3504, 11108, 8.7915, 9002.5207
kafka学习之三_信创CPU下单节点kafka性能测试验证的更多相关文章
- 【kafka学习之三】kafka集群运维
kafka集群维护一.kafka集群启停#启动kafka/home/cluster/kafka211/bin/kafka-server-start.sh -daemon /home/cluster/k ...
- kafka学习笔记(一)消息队列和kafka入门
概述 学习和使用kafka不知不觉已经将近5年了,觉得应该总结整理一下之前的知识更好,所以决定写一系列kafka学习笔记,在总结的基础上希望自己的知识更上一层楼.写的不对的地方请大家不吝指正,感激万分 ...
- Kafka 学习之路(五)—— 深入理解Kafka副本机制
一.Kafka集群 Kafka使用Zookeeper来维护集群成员(brokers)的信息.每个broker都有一个唯一标识broker.id,用于标识自己在集群中的身份,可以在配置文件server. ...
- Kafka学习之(二)Centos下安装Kafka
环境:Centos6.4,官方下载地址:http://kafka.apache.org/downloads ,前提是还需要安装了Java环境,本博客http://www.cnblogs.com/wt ...
- Kafka学习笔记之K8S内filebeat传输到kafka报错带解决方案
0x00 概述 filebeat非常轻量级,正常情况下占用的资源几乎都能忽略不计,但是部署后发现资源占用很大,所以怀疑是filebeat本身出了问题. 第一时间查看filebeat日志(默认路径/va ...
- Kafka学习-简介
Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用.目前越来越多的开源分布式处理系统如Cloudera.Apache Storm.S ...
- Apache Kafka学习 (一)
前言:最近公司开始要研究大数据的消息记录,于是开始研究kafka. 市面上kafka的书很少,有的也版本比较落后,于是仗着自己英文还不错,上官网直接学习. ^_^ 1. 开始 - 基本概念 学习一样东 ...
- 【大数据】Kafka学习笔记
第1章 Kafka概述 1.1 消息队列 (1)点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除) 点对点模型通常是一个基于拉取或者轮询的消息传送模型,这种模型从队列中请求信息,而不是将消息 ...
- Kafka学习(一)kafka指南(about云翻译)
kafka 权威指南中文版 问题导读 1. 为什么数据管道是数据驱动企业的一个关键组成部分? 2. 发布/订阅消息的概念及其重要性是什么? 第一章 初识 kafka 企业是由数据驱动的.我们获取信息, ...
- Kafka学习文档
本教程假定您是一只小白,没有Kafka 或ZooKeeper 方面的经验. Kafka脚本在Unix和Windows平台有所不同,在Windows平台,请使用 bin\windows\ 而不是bin/ ...
随机推荐
- Hive 和 Spark 分区策略剖析
作者:vivo 互联网搜索团队- Deng Jie 随着技术的不断的发展,大数据领域对于海量数据的存储和处理的技术框架越来越多.在离线数据处理生态系统最具代表性的分布式处理引擎当属Hive和Spark ...
- 万字详解 | Java 流式编程
概述 Stream API 是 Java 中引入的一种新的数据处理方法.它提供了一种高效且易于使用的方法来处理数据集合.Stream API 支持函数式编程,可以让我们以简洁.优雅的方式进行数据操作, ...
- python入门教程之五数据结构
变量 Python 变量类型 变量存储在内存中的值,这就意味着在创建变量时会在内存中开辟一个空间. 基于变量的数据类型,解释器会分配指定内存,并决定什么数据可以被存储在内存中. 因此,变量可以指定不同 ...
- pandas之缺失值处理
在一些数据分析业务中,数据缺失是我们经常遇见的问题,缺失值会导致数据质量的下降,从而影响模型预测的准确性,这对于机器学习和数据挖掘影响尤为严重.因此妥善的处理缺失值能够使模型预测更为准确和有效. 为什 ...
- servlet 没有实例化可以直接调用非静态方法??
今天练习servlet时,居然发现没有实例化可以直接调用非静态方法.看了好长时间发现:省去了this关键字.记录一下. public class Servlet2 extends GenericSer ...
- 信息论之从熵、惊奇到交叉熵、KL散度和互信息
一.熵(PRML) 考虑将A地观测的一个随机变量x,编码后传输到B地. 这个随机变量有8种可能的状态,每个状态都是等可能的.为了把x的值传给接收者,需要传输⼀个3⽐特的消息.注意,这个变量的熵由下式给 ...
- 3. 面向对象编程(OOP):
面向对象编程的本质就是:以类的方式组织代码.以对象的组织(封装)数据 抽象:就是把不同的物品的共同点剥离出来,构成一个类.如每个人都有2条腿,我们可以把2条腿剥离出来 构成一个类 类与对象的关系 类: ...
- js函数-参数默认值
1. 在es6之前必须通过函数内部实现 就像以下的几种情况: function example(a,b){ var a = arguments[0] ? arguments[0] : 1;//设置参数 ...
- JavaScript封装大全
JavaScript封装大全-持续更新 Ajax封装 // 使用该封装需注意 // Ajax(method(默认GET), url(网址 必传), success(res){(成功时数据处理函数 必传 ...
- PCI-5565系列反射内存卡 反射内存交换机
主要性能:1路发射,一路接收光纤高速网络2.125GHz.最大256个节点.在板128MByte SDRAM.光纤通讯协议不占用CPU资源.动态包长,每个包4 到 64 个字节.33MHz PCI 3 ...