[转帖]mysql8 ALGORITHM=INSTANT 亿级数据秒速增加字段
一、概述
在线DDL之快速增加列(秒级别的),并不会造成业务抖动。该功能自 MySQL 8.0.12 版本引入,是由腾讯游戏DBA团队贡献,此功能只适
用于 InnoDB 表。实际上MySQL 5.7就已支持 Online DDL,虽说大部分 DDL 不影响对表DML操作,但是依然会消耗非常多的时间,且占用
额外的磁盘空间,并会造成主从延迟,或者影响表的查询速度。有了这个ALGORITHM=INSTANT 就可应对瞬息万变的需求了。
MySQL在大型表上的 DDL 会带来耗时较久、负载较高、额外空间占用、MDL、主从同步延时等情况。需要特别引起重视,而MySQL的DDL有很
多种方法。
MySQL本身自带三种方法,分别是:copy、inplace、instant。copy算法为最古老的算法,在MySQL5.5及以下为默认算法。
从MySQL5.6开始,引入了inplace算法并且默认使用。inplace算法还包含两种类型:rebuild-table 和 not-rebuild-table。
MySQL使用inplace算法时,会自动判断,能使用not-rebuild-table的情况下会尽量使用,不能的时候才会使用rebuild-table。
当DDL涉及到主键和全文索引相关的操作时,无法使用 not-rebuild-table,必须使用 rebuild-table。其他情况下都会使用 not-rebuild-table。
从MySQL8.0.12开始,引入了instant算法并且默认使用。目前instant算法只支持增加列等少量DDL类型的操作,其他类型仍然会默认使用inplace。
有一些第三方工具也可以实现DDL操作,最常见的是percona的pt-online-schema-change工具(简称为 pt-osc),和github的gh-ost工具,
均支持 MySQL 5.5 以上的版本。
》》各类工具的对比
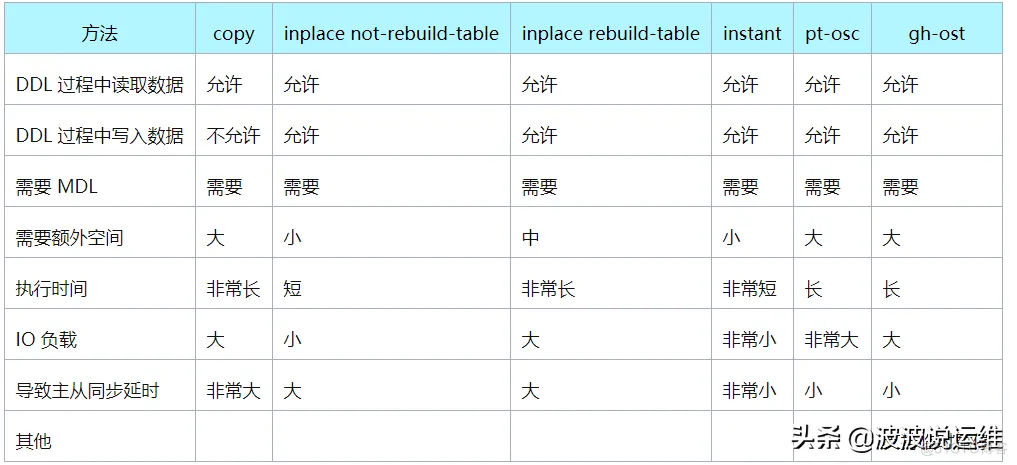
二、MySQL DDL 的原理简析
1、copy 算法
较简单的实现方法,MySQL 会建立一个新的临时表,把源表的所有数据写入到临时表,在此期间无法对源表进行数据写入。MySQL在完成临时表的写入之后,用临时表替换掉源表。这个算法主要被早期(<=5.5)版本所使用。
2、inplace 算法
从 5.6 开始,常用的 DDL 都默认使用这个算法。inplace 算法包含两类:inplace-no-rebuild 和 inplace-rebuild,两者的主要差异在于是否需要重建源表。
inplace 算法的操作阶段主要分为三个:Prepare阶段: - 创建新的临时 frm 文件(与 InnoDB 无关)。 - 持有 EXCLUSIVE-MDL 锁,禁止读写。 - 根据 alter 类型,确定执行方式(copy,online-rebuild,online-not-rebuild)。 更新数据字典的内存对象。 - 分配 row_log 对象记录数据变更的增量(仅 rebuild 类型需要)。 - 生成新的临时ibd文件 new_table(仅rebuild类型需要)。
Execute 阶段:降级EXCLUSIVE-MDL锁,允许读写。扫描old_table聚集索引(主键)中的每一条记录 rec。遍历new_table的聚集索引和二级索引,逐一处理。根据 rec 构造对应的索引项。将构造索引项插入 sort_buffer 块排序。将 sort_buffer 块更新到 new_table 的索引上。记录 online-ddl 执行过程中产生的增量(仅 rebuild 类型需要)。重放 row_log 中的操作到 new_table 的索引上(not-rebuild 数据是在原表上更新)。重放 row_log 中的DML操作到 new_table 的数据行上。
Commit阶段:当前 Block 为 row_log 最后一个时,禁止读写,升级到 EXCLUSIVE-MDL 锁。重做 row_log 中最后一部分增量。更新 innodb 的数据字典表。提交事务(刷事务的 redo 日志)。修改统计信息。rename 临时 ibd 文件,frm文件。变更完成,释放 EXCLUSIVE-MDL 锁。
3、instant 算法
MySQL 8.0.12 才提出的新算法,目前只支持添加列等少量操作,利用 8.0 新的表结构设计,可以直接修改表的 metadata 数据,省掉了 rebuild 的过程,极大的缩短了 DDL 语句的执行时间。
4、pt-online-schema-change
借鉴了 copy 算法的思路,由外部工具来完成临时表的建立,数据同步,用临时表替换源表这三个步骤。其中数据同步是利用 MySQL 的触发器来实现的,会少量影响到线上业务的 QPS 及 SQL 响应时间。
三、mysql 8.0特性instant add column
1、instant add column原理
mysql数据库针对亿级别的大表加字段是痛苦的,需要对表进行重建,MySQL 5.7 支持 Online DDL,大部分 DDL 不影响对表的读取和写入,但是依然会消耗非常多的时间,且占用额外的磁盘空间,并会造成主从延迟。所以大表 DDL 仍是一件令 DBA 头痛的事。而mysql8.0使用instant ADD COLUMN特性,只需很短的时间,字段就加好了,享受MongoDB那样的非结构化存储的灵活方便,无形中减少了开发的工作量。
快速加列采用的是 instant 算法,使得添加列时不再需要 rebuild 整个表,只需要在表的 metadata 中记录新增列的基本信息即可。在 alter 语句后增加 ALGORITHM=INSTANT 即代表使用 instant 算法, 如果未明确指定,则支持 instant 算法的操作会默认使用。如果 ALGORITHM=INSTANT 指定但不支持,则操作立即失败并显示错误。
下表概述了对列操作的在线 DDL 支持。星号表示附加信息、异常或依赖项。
|
Operation |
Instant |
In Place |
Rebuilds Table |
Permits Concurrent DML |
Only Modifies Metadata |
|
Adding a column |
Yes* |
Yes |
No* |
Yes* |
Yes |
|
Dropping a column |
Yes* |
Yes |
Yes |
Yes |
Yes |
|
Renaming a column |
Yes* |
Yes |
No |
Yes* |
Yes |
|
Reordering columns |
No |
Yes |
Yes |
Yes |
No |
|
Setting a column default value |
Yes |
Yes |
No |
Yes |
Yes |
|
Changing the column data type |
No |
No |
Yes |
No |
No |
|
Extending |
No |
Yes |
No |
Yes |
Yes |
|
Dropping the column default value |
Yes |
Yes |
No |
Yes |
Yes |
|
Changing the auto-increment value |
No |
Yes |
No |
Yes |
No* |
|
Making a column |
No |
Yes |
Yes* |
Yes |
No |
|
Making a column |
No |
Yes* |
Yes* |
Yes |
No |
|
Modifying the definition of an |
Yes |
Yes |
No |
Yes |
Yes |
三、语法和使用说明
1、添加列
ALTER TABLE tbl_name ADD COLUMN column_name column_definition, ALGORITHM=INSTANT;
INSTANT是MySQL8.0.12和INPLACE之后的默认算法。
当 INSTANT算法用于添加列时,以下限制适用:
1、添加列不能与ALTER TABLE不支持的其他操作在同一语句中组合ALGORITHM=INSTANT。
2、在MySQL 8.0.29之前,一列只能作为表的最后一列添加。不支持将列添加到其他列中的任何其他位置。从MySQL 8.0.29开始,可以将即时
添加的列添加到表中的任何位置。
3、不能将列添加到使用ROW_FORMAT=COMPRESSED的表、具有FULLTEXT索引的表、驻留在数据字典表空间中的表或临时表。临时表仅支持
ALGORITHM=COPY.
4、在MySQL 8.0.29之前,添加列时不会评估行大小限制。但是,在插入和更新表中的行的DML操作期间会检查行大小限制。从8.0.29开始,
添加列时会检查行大小限制。如果超出限制,则会报告以下错误消息:
"ERROR 4092 (HY000): Column can't be added with ALGORITHM=INSTANT as after this max possible row size crosses max permissible row size.
Try ALGORITHM=INPLACE/COPY."
可以在同一 ALTER TABLE语句中添加多个列。例如:
ALTER TABLE t1 ADD COLUMN c2 INT, ADD COLUMN c3 INT, ALGORITHM=INSTANT;
ALTER TABLE ... ALGORITHM=INSTANT在每次添加一或多列、删除一或多列或在同一操作中添加和删除一或多列的操作之后,都会创建一个新
的行版本 。该INFORMATION_SCHEMA.INNODB_TABLES.TOTAL_ROW_VERSIONS列跟踪表的行版本数。每次立即添加或删除列时,该值都会增加
。初始值为 0。
mysql> SELECT NAME, TOTAL_ROW_VERSIONS FROM INFORMATION_SCHEMA.INNODB_TABLES
WHERE NAME LIKE 'test/t1';
当通过表重建ALTER TABLE 或OPTIMIZE TABLE 操作重建具有即时添加或删除列的表时,该TOTAL_ROW_VERSIONS值重置为 0。允许的最大
行版本数为 64,因为每个行版本都需要额外的空间用于表元数据。当达到行版本限制时,ADD COLUMN or DROP COLUMN
using ALGORITHM=INSTANT被拒绝,并显示一条错误消息,建议使用 COPY or INPLACE 算法重建表。
'ERROR 4080 (HY000): Maximum row versions reached for table test/t1. No more columns can be added or dropped instantly. Please use COPY/INPLACE.'
2、删除一列
ALTER TABLE tbl_name DROP COLUMN column_name, ALGORITHM=INSTANT;
当 INSTANT算法用于删除列时,以下限制适用:
1、删除列不能与ALTER TABLE不支持的其他操作在同一语句中组合ALGORITHM=INSTANT。
2、不能从使用 ROW_FORMAT=COMPRESSED的表、具有 FULLTEXT索引的表、驻留在数据字典表空间中的表或临时表中删除列。临时表仅支持
ALGORITHM=COPY.
ALTER TABLE同一语句中可以删除多个列;例如:
ALTER TABLE t1 DROP COLUMN c4, DROP COLUMN c5, ALGORITHM=INSTANT;
每次使用 添加或删除列时ALGORITHM=INSTANT,都会创建一个新的行版本。该INFORMATION_SCHEMA.INNODB_TABLES.TOTAL_ROW_VERSIONS
列跟踪表的行版本数。每次立即添加或删除列时,该值都会增加。初始值为 0。
3、重命名列
ALTER TABLE tbl CHANGE old_col_name new_col_name data_type, ALGORITHM=INSTANT, LOCK=NONE;
MySQL8.0.28中添加了ALGORITHM=INSTANT对重命名列的支持。早期的MySQL服务器版本仅支持ALGORITHM=INPLACE or ALGORITHM=COPY命名列。
要允许并发 DML,请保持相同的数据类型并仅更改列名。
当您保持相同的数据类型和[NOT] NULL属性时,只需更改列名,就可以始终在线执行操作。
仅允许重命名从另一个表引用的列ALGORITHM=INPLACE。如果您使用ALGORITHM=INSTANTor ALGORITHM=COPY或其他操作使用这些算法的条件
,则 ALTER TABLE语句将失败。
ALGORITHM=INSTANT支持重命名虚拟列;ALGORITHM=INPLACE不支持。
ALGORITHM=INSTANT和ALGORITHM=INPLACE不支持在同一语句中添加或删除虚拟列时重命名列。在这种情况下仅ALGORITHM=COPY支持。
4、更改列数据类型
5、扩展VARCHAR列大小
ALTER TABLE tbl_name CHANGE COLUMN c1 c1 VARCHAR(255), ALGORITHM=INPLACE, LOCK=NONE;
列所需的长度字节数VARCHAR必须保持不变。对于VARCHAR大小为0到255字节的列,需要一个长度字节来对值进行编码。对于VARCHAR大小为
256 字节或更大的列,需要两个长度字节。因此,INPLACE ALTER TABLE仅支持将VARCHAR列大小从0字节增加到255字节,或从256字节增
加到更大的大小。INPLACE ALTER TABLE不支持增加VARCHAR列从小于256字节到大小等于或大于256字节。在这种情况下,所需的长度字节
数从1变为2,仅表拷贝 ( ALGORITHM=COPY) 支持。例如,尝试VARCHAR使用就地将单字节字符集的列大小从VARCHAR(255)更改为
VARCHAR(256) 会ALTER TABLE返回此错误:
ALTER TABLE tbl_name ALGORITHM=INPLACE, CHANGE COLUMN c1 c1 VARCHAR(256);
ERROR 0A000: ALGORITHM=INPLACE is not supported. Reason: Cannot change column type INPLACE. Try ALGORITHM=COPY.
不支持VARCHAR使用就地减小大小。ALTER TABLE减小VARCHAR大小需要使用ALGORITHM=COPY
6、设置列默认值
7、删除列默认值
8、更改自动增量值
9、创建NULL列
10、创建NOT NULL列
11、修改ENUM或 SET列 的定义
12、外键操作
|
Operation |
Instant |
In Place |
Rebuilds Table |
Permits Concurrent DML |
Only Modifies Metadata |
|
Adding a foreign key constraint |
No |
Yes* |
No |
Yes |
Yes |
|
Dropping a foreign key constraint |
No |
Yes |
No |
Yes |
Yes |
四、补充
更多信息可以查看mysql官方文档
https://dev.mysql.com/doc/refman/8.0/en/innodb-online-ddl-operations.html
[转帖]mysql8 ALGORITHM=INSTANT 亿级数据秒速增加字段的更多相关文章
- MySQL使用pt-online-change-schema工具在线修改1.6亿级数据表结构
摘 要:本文阐述了MySQL DDL 的问题现状.pt-online-schema-change的工作原理,并实际利用pt-online-schema-change工具在线修改生产环境下1.6亿级数 ...
- 通用技术 mysql 亿级数据优化
通用技术 mysql 亿级数据优化 一定要正确设计索引 一定要避免SQL语句全表扫描,所以SQL一定要走索引(如:一切的 > < != 等等之类的写法都会导致全表扫描) 一定要避免 lim ...
- 不停机不停服务,MYSQL可以这样修改亿级数据表结构
摘 要:本文阐述了MySQL DDL 的问题现状.pt-online-schema-change的工作原理,并实际利用pt-online-schema-change工具在线修改生产环境下1.6亿级数 ...
- 基于Mysql数据库亿级数据下的分库分表方案
移动互联网时代,海量的用户数据每天都在产生,基于用户使用数据的用户行为分析等这样的分析,都需要依靠数据都统计和分析,当数据量小时,问题没有暴露出来,数据库方面的优化显得不太重要,一旦数据量越来越大时, ...
- Mongodb亿级数据量的性能测试
进行了一下Mongodb亿级数据量的性能测试,分别测试如下几个项目: (所有插入都是单线程进行,所有读取都是多线程进行) 1) 普通插入性能 (插入的数据每条大约在1KB左右) 2) 批量插入性能 ...
- 巧用redis位图存储亿级数据与访问 - 简书
原文:巧用redis位图存储亿级数据与访问 - 简书 业务背景 现有一个业务需求,需要从一批很大的用户活跃数据(2亿+)中判断用户是否是活跃用户.由于此数据是基于用户的各种行为日志清洗才能得到,数据部 ...
- NEO4J亿级数据导入导出以及数据更新
1.添加配置 apoc.export.file.enabled=true apoc.import.file.enabled=true dbms.directories.import=import db ...
- NEO4J亿级数据全文索引构建优化
NEO4J亿级数据全文索引构建优化 一.数据量规模(亿级) 二.构建索引的方式 三.构建索引发生的异常 四.全文索引代码优化 1.Java.lang.OutOfMemoryError 2.访问数据库时 ...
- Mybatis 使用分页查询亿级数据 性能问题 DB使用ORACLE
一般用到了mybatis框架分页就不用自己写了 直接用RowBounds对象就可以实现,但这个性能确实很低 今天我用到10w级得数据分页查询,到后面几页就迭代了很慢 用于记录 1.10万级数据如下 [ ...
- 挑战海量数据:基于Apache DolphinScheduler对千亿级数据应用实践
点亮 ️ Star · 照亮开源之路 GitHub:https://github.com/apache/dolphinscheduler 精彩回顾 近期,初灵科技的大数据开发工程师钟霈合在社区活动的线 ...
随机推荐
- 解密Prompt系列22. LLM Agent之RAG的反思:放弃了压缩还是智能么?
已经唠了三章的RAG,是时候回头反思一下,当前的RAG是解决幻觉的终点么?我给不出直接的答案,不过感觉当前把RAG当作传统搜索框架在大模型时代下的改良,这个思路的天花板高度有限~ 反思来源于对RAG下 ...
- Prometheus 与 VictoriaMetrics对比
公众号「架构成长指南」,专注于生产实践.云原生.分布式系统.大数据技术分享 时序数据库有很多,比如Prometheus.M3DB.TimescaleDB.OpenTSDB.InfluxDB等等.Pro ...
- electron入门之配置镜像加速(四)
electron入门到入土,配置阿里镜像加速.为了防止后面我们打包龟速,需要给electron配置阿里镜像加速 在下面的文件内添加阿里镜像加速,你的文件位置不一定是这个 C:\Program File ...
- 5分钟就能实现的API监控,有什么理由不做呢?基调听云
API深度影响着你的应用 今天的数字应用世界其实是一个以API为中心的世界,我们只是没有意识到这些API的重要性.比如在电子商务交易.社交媒体等对交互高度依赖的领域,可以说API决定了应用的质量一点也 ...
- 一篇文章彻底搞懂TiDB集群各种容量计算方式
背景 TiDB 集群的监控面板里面有两个非常重要.且非常常用的指标,相信用了 TiDB 的都见过: Storage capacity:集群的总容量 Current storage size:集群当前已 ...
- JavaImprove--Lesson04--LocalDateTime,ZoneId,Instant,DateTimeFormatter
一.LocalDateTime LocalDateTime是JDK8的新时间特性,它解决了Date类和Calender类的很多不足,如使用不方便,线程不安全,以及获取时间戳只能拿到毫秒而不能拿到纳秒等 ...
- 大道如青天,协程来通信,Go lang1.18入门精炼教程,由白丁入鸿儒,Go lang通道channel的使用EP14
众所周知,Go lang的作用域相对严格,数据之间的通信往往要依靠参数的传递,但如果想在多个协程任务中间做数据通信,就需要通道(channel)的参与,我们可以把数据封装成一个对象,然后把这个对象的指 ...
- MySQL进阶篇:详解存储引擎InnoDB
本篇基础环境是使用navicat 12和Mysql8.0 MySQL进阶篇:第一章_一.二_存储引擎特点_InnoDB 1.1 存储引擎特点 1.1.1 InnoDB 1). 介绍 InnoDB是一种 ...
- 干货分享丨从MPG 线程模型,探讨Go语言的并发程序
摘要:Go 语言的并发特性是其一大亮点,今天我们来带着大家一起看看如何使用 Go 更好地开发并发程序. 我们都知道计算机的核心为 CPU,它是计算机的运算和控制核心,承载了所有的计算任务.最近半个世纪 ...
- “互联网+”大赛之智慧校园 赛题攻略:你的智慧校园,WeLink帮你来建
摘要:本赛题的核心就是借助华为云WeLink的中台服务能力/开发工具等,结合学校的具体的高价值场景,开发出WeLink小程序,方便师生的学习与生活. 本文分享自华为云社区<"互联网+& ...