技术文档 | OpenSCA技术原理之composer依赖解析
OpenSCA知识小课堂开课了!
今天主要介绍基于composer包管理器的组件成分解析原理。
composer介绍
composer是PHP的依赖管理工具。
开发者受到Node.js的npm及Ruby的bundler启发,composer设计上与两者有诸多相似。
composer的依赖管理文件是composer.json。开发者可以在composer.json中指定每个依赖项的版本范围或使用composer require/update/remove ${name}命令管理依赖项。
如果一个项目中存在composer.json文件,便可以执行composer install命令自动安装当前项目所需的依赖项并生成composer.lock文件
composer.json完整文件结构如下:
{
"name": "cakephp/app",
"type": "project",
"license": "MIT",
"require": {
"php": ">=7.2",
"cakephp/cakephp": "^4.3",
"cakephp/migrations": "^3.2",
"cakephp/plugin-installer": "^1.3",
"mobiledetect/mobiledetectlib": "^2.8"
},
"require-dev": {
"cakephp/bake": "^2.6",
"cakephp/cakephp-codesniffer": "^4.5",
"cakephp/debug_kit": "^4.5",
"josegonzalez/dotenv": "^3.2",
"phpunit/phpunit": "~8.5.0 || ^9.3"
},
}其中name为项目名称;type为包的类型,有library、project、metapackage和composer-plugin四种类型,默认情况下为library;license为项目声明的许可证,可以是一个字符串或是一个字符串数组。
require-dev为开发环境或测试使用的依赖,require为生产环境使用的依赖,依赖写法为"name":"version",版本可以指定准确版本或一个范围。
解析算法
composer.lock
composer.lock文件为自动生成的文件,可以准确定位到PHP项目使用的依赖及版本,所以优先解析composer.lock文件。
composer.lock文件结构如下:
{
"packages": [
{
"name": "a",
"version": "1.1.0",
"require": {
"c": "1.1.*"
}
},
{
"name": "b",
"version": "1.2.2",
"require": {
"c": "^1.0.2"
}
},
{
"name": "c",
"version": "1.1.2"
}
],
"packages-dev": []
}其中packages和packages-dev字段包含项目使用的所有直接和间接依赖,而且记录了组件间的依赖关系,packages为生产环境的依赖,packages-dev为开发环境的依赖。
示例:
{
"name": "a",
"version": "1.1.0",
"require": {
"c": "1.1.*"
}
}代表项目依赖1.1.0版本的组件a,且该组件依赖版本约束为1.1.*的组件c。
同理可知项目依赖1.2.2版本的组件b,且该组件依赖版本约束为^1.0.2的组件c。
且组件a和组件b都没有被其他依赖所依赖,所以可知这两个组件是项目的直接依赖。
注:
1.1.*代表版本号需要>=1.1.0且<1.2.0
^1.0.2代表版本号需要>=1.0.2且<2.0.0
由此可以构建出当前项目的依赖结构:
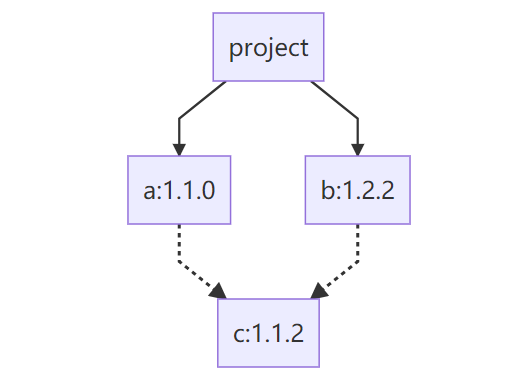
实线代表直接依赖,虚线代表间接依赖
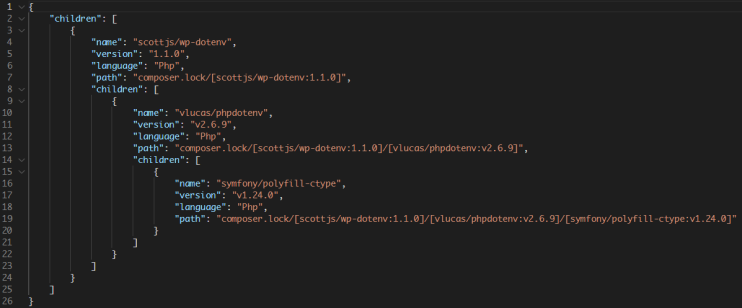
图:composer.lock检测结果示例
composer.json
composer.json为开发者管理的依赖管理文件,在未找到composer.lock文件时将解析该文件。
composer.json仅包含直接依赖,在项目构建时会从composer仓库下载需要的间接依赖并构建为composer.lock文件,因此可以模拟composer构建流程来获取项目引用的组件依赖。
composer.json文件结构如下:
{
"name": "foo",
"type": "project",
"license": "MIT",
"require": {
"a": "^1.1.0",
"b": "^1.2.0",
},
"require-dev": {},
}require为项目实际使用的直接依赖,require-dev为项目开发时使用的直接依赖。
例如:
"a": "^1.1.0"代表项目依赖版本约束为^1.1.0的组件a。
"b": "^1.2.0"代表项目依赖版本约束为^1.2.0的组件b。
分析到这里我们可以总结出如下图依赖关系:
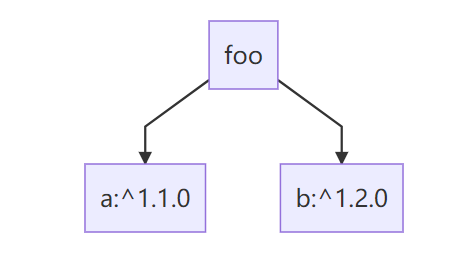
实线代表直接依赖
通过该依赖关系可以看出项目组件的直接依赖及组件的版本范围,但无法得知组件依赖的具体版本。
在没有composer.lock文件的情况下,为了进一步获取依赖的准确版本及间接依赖,需要从composer仓库下载对应组件的详细信息。
例如组件a的详细信息结构为:
{
"packages": {
"a": [
{
"version": "1.0.1",
"require": {
"c": "^1.0.0"
}
},
{
"version": "1.1.0",
"require": {
"c": "^1.1.0"
}
}
]
}
}其中packages字段为组件及各个版本信息的映射,require字段为组件的依赖信息。
对于本例来说,组件a的约束为^1.1.0,要求版本号>=1.1.0且<2.0.0,所以选择1.1.0版本。
因此组件依赖结构就变成了:
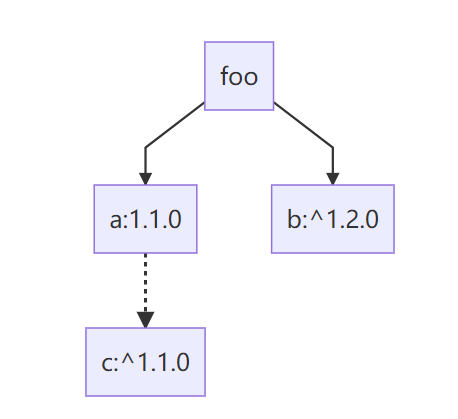
按照这种方式层级解析便可获取整个项目的依赖信息。
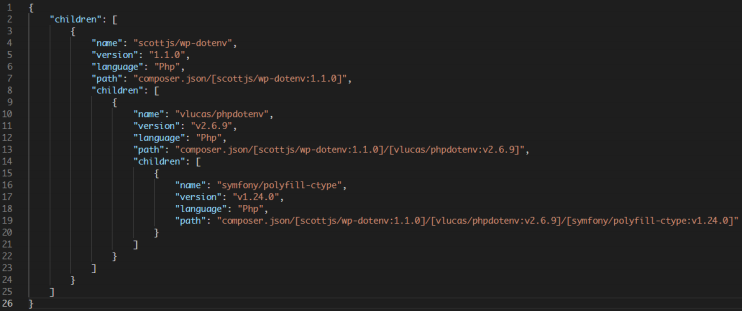
图:composer.json检测结果示例
感谢每一位开源社区成员对OpenSCA的支持和贡献。
OpenSCA的代码会在GitHub和Gitee持续迭代,欢迎Star和PR,成为我们的开源贡献者,也可提交问题或建议至Issues。我们会参考大家的建议不断完善OpenSCA开源项目,敬请期待更多功能的支持。
OpenSCA官网:
GitHub:
https://github.com/XmirrorSecurity/OpenSCA-cli/releases
Gitee:
技术文档 | OpenSCA技术原理之composer依赖解析的更多相关文章
- 技术文档--studio技术文档
1.Google推出的毫无疑问,这个是它的最大优势,Android Stuido是Google推出,专门为Android“量身订做”的,是Google大力支持的一款基于IntelliJ IDEA改造的 ...
- Atitit usrQBK1600 技术文档的规范标准化解决方案
Atitit usrQBK1600 技术文档的规范标准化解决方案 1.1. Keyword关键词..展关键词,横向拓展比较,纵向抽象细化拓展知识点1 1.2. 标题必须有高大上词汇,参考文章排行榜,1 ...
- Kafka 技术文档
Kafka 技术文档 目录 1 Kafka创建背景 2 Kafka简介 3 Kafka好处 3.1 解耦 3.2 冗余 3.3 扩展性 3.4 灵活性 & 峰值处理能力 3.5 可恢复性 ...
- 使用Jupyter Notebook编写技术文档
1.jupyter Notebook的组成 这里它的组件及其工程构成,帮助大家更好的用好jupyter Notebook 组件 Jupyter Notebook结合了三个组件: 笔记本Web应用程序: ...
- 如何写好技术文档——来自Google十多年的文档经验
本文大部分内容翻译总结自<Software Engineering at Google> 第10章节 Documentation. 另外,该书电子版近日已经可以免费下载了 https:// ...
- RabbitMq 技术文档
RabbitMq 技术文档 目录 1 AMQP简介 2 AMQP的实现 3 RabbitMQ简介 3.1 概念说明 3.2 消息队列的使用过程 3.3 RabbitMQ的特性 4 RabbitMQ使用 ...
- [转]unity3d 脚本参考-技术文档
unity3d 脚本参考-技术文档 核心提示:一.脚本概览这是一个关于Unity内部脚本如何工作的简单概览.Unity内部的脚本,是通过附加自定义脚本对象到游戏物体组成的.在脚本对象内部不同志的函数被 ...
- Umbraco官方技术文档 中文翻译
Umbraco 官方技术文档中文翻译 http://blog.csdn.net/u014183619/article/details/51919973 http://www.cnblogs.com/m ...
- Indri中的动态文档索引技术
Indri中的动态文档索引技术 戴维 译 摘要: Indri 动态文档索引的实现技术,支持在更新索引的同时处理用户在线查询请求. 文本搜索引擎曾被设计为针对固定的文档集合进行查询,对不少应用来说,这种 ...
- [转]chrome技术文档列表
chrome窗口焦点管理系统 http://www.douban.com/note/32607279/ chrome之TabContents http://www.douban.com/note/32 ...
随机推荐
- 深度解析C#中LinkedList<T>的存储结构
本文承接前面的3篇有关C#的数据结构分析的文章,对于C#有关数据结构分析还有一篇就要暂时结束了,这个系列主要从Array.List.Dictionary.LinkedList. SortedSet等5 ...
- .NET Conf 2023 Chengdu - 成都站圆满结束!
今年的.NET Conf 2023,中国区首次有两个会场举办Local Event,成都会场已于上周六12月9日圆满结束. 本次成都会场共计100+余名.NET开发者报名参与,共计10+名志愿者参与筹 ...
- [ARC105E] Keep Graph Disconnected
题目链接 好题. 如果 \(1\) 和 \(n\) 一直联通,开始即结束. 如果 \(n\mod 4=1\),那么 \(\frac 12x(x+1)+\frac12(n-x)(n-x+1)\) 为偶数 ...
- MybatisPlus入门到进阶
1.创建一个SpringBoot项目 2.导入相关依赖 <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xs ...
- 记一次 .NET某工控 宇宙射线 导致程序崩溃分析
一:背景 1. 讲故事 为什么要提 宇宙射线, 太阳耀斑 导致的程序崩溃呢?主要是昨天在知乎上看了这篇文章:莫非我遇到了传说中的bug? ,由于 rip 中的0x41变成了0x61出现了bit位翻转导 ...
- 华企盾DSC客户端连接服务器正常,控制台找不到客户端
1.首先客户端查一下策略状态,看一下客户端在哪个组,是否在回收站,或者无策略组: 2.查看一下数据库的CLIENT_GROUP_TABLE_表中是否有查出来的组,CLIENT_GROUP_TABLE_ ...
- python tkinter 使用(六)
python tkinter 使用(六) 本文主要讲述tkinter中进度条的使用. 1:确定的进度条 progressbar = tkinter.ttk.Progressbar(root, mode ...
- 什么是革命性技术eBPF?为什么可观测性领域都得用它
公众号「架构成长指南」,专注于生产实践.云原生.分布式系统.大数据技术分享. 如果有一种技术可以监控和采集任何应用信息,支持任何语言,并且应用完全无感知,零侵入,想想是不是很激动,那么这个技术是什么呢 ...
- 微软真是活菩萨,面向初学者的机器学习、数据科学、AI、LLM课程统统免费
微软真是活菩萨,面向初学者的机器学习.数据科学.AI.LLM课程统统免费 大家好,我是老章 推荐几个质量上乘且完全免费的微软开源课程 面向初学者的机器学习课程 地址:https://microsoft ...
- MySQL运维实战(1.1)安装部署:使用RPM进行安装部署
作者:俊达 我们在生产环境部署mysql时,一般很少使用RedHat Package Manager(RedHat软件包管理工具).用rpm或或者其他包管理器安装mysql有其好处,例如安装简单,并且 ...