NLP复习之N元文法
N元文法的统计
二元概率方程:
\]
三元概率估计方程:
\]
例题1
给出以下一个小型语料库,在最大似然一元模型和二元模型之间使用加一平滑法进行平滑, 请计算P(Sam|am)。注意要将tokens 和与其他单词一样看待。
<s> I am Sam </s>
<s> Sam I am </s>
<s> I am Sam </s>
<s> I do not like green eggs and Sam </s>
解
\(P(Sam|am) = \frac{C(am;Sam)}{C(am)} = \frac{2}{3}\)
\(P_{Laplace}(Sam|am) = \frac{C(am;Sam)+1}{C(am)+|V|} = \frac{2+1}{3+11} = \frac{3}{14}\)
注意:V是不同单词的种类!!是词汇表的大小
例题2
在1的条件下,请使用线性插值法,其中假设 λ1 = 1/2, λ2 =1/2,请计算P(Sam|am)。注意要将tokens 和与其他单词一样看待。
解
\(P(Sam) = \frac{C(Sam)}{S} =\frac{4}{25}\)
注意:S是单词出现的总次数!!
\(P(am) = \frac{3}{25}\)
统计\(bigram\)数量,\(P(Sam|am) = \frac{2}{3}\)
根据线性插值法,
P(Sam|am) &= \lambda_2 \times P(Sam|am) + \lambda_1 \times P(Sam)\\
&= 0.5 \times \frac{2}{3} + 0.5 \times \frac{3}{25} \\
&= \frac{31}{75}
\end{aligned}
\]
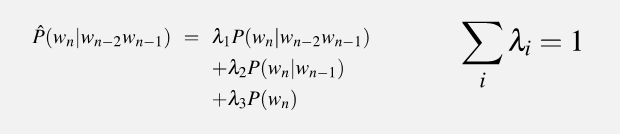
例题3
给定一个包含 100 个数字的训练集,其中包含 91 个0和 1-9 其他数字中的每个数字。 有以下的测试集:0 0 0 0 0 3 0 0 0 0。计算该问题的一元困惑度 unigram perplexity。
困惑度
\]
困惑度越小,概率越大。
解
\(P(0) = 91 / 100 = 0.91;\)
\(P(1;9) = 1 / 100 = 0.01;\)
\(PP(W) = (P(0)p(0)p(0)p(0)p(0)p(3)p(0)p(0)p(0)p(0))^{-0.1} = 1.725\)
NLP复习之N元文法的更多相关文章
- 【转】统计模型-n元文法
在谈N-Gram模型之前,我们先来看一下Mrkove假设: 1.一个词的出现仅仅依赖于它前面出现的有限的一个或者几个词: 2.一个词出现的概率条件地依赖于前N-1个词的词类. 定义 N-Gram是大词 ...
- 算法复习——高斯消元(ssoi)
题目: 题目描述 Tom 是个品学兼优的好学生,但由于智商问题,算术学得不是很好,尤其是在解方程这个方面.虽然他解决 2x=2 这样的方程游刃有余,但是对于下面这样的方程组就束手无策了.x+y=3x- ...
- DeepNLP的核心关键/NLP词的表示方法类型/NLP语言模型 /词的分布式表示/word embedding/word2vec
DeepNLP的核心关键/NLP语言模型 /word embedding/word2vec Indexing: 〇.序 一.DeepNLP的核心关键:语言表示(Representation) 二.NL ...
- NLP十大里程碑
NLP十大里程碑 2.1 里程碑一:1985复杂特征集 复杂特征集(complex feature set)又叫做多重属性(multiple features)描写.语言学里,这种描写方法最早出现在语 ...
- NLP之语言模型
参考: https://mp.weixin.qq.com/s/NvwB9H71JUivFyL_Or_ENA http://yangminz.coding.me/blog/post/MinkolovRN ...
- 【NLP】中文分词:原理及分词算法
一.中文分词 词是最小的能够独立活动的有意义的语言成分,英文单词之间是以空格作为自然分界符的,而汉语是以字为基本的书写单位,词语之间没有明显的区分标记,因此,中文词语分析是中文信息处理的基础与关键. ...
- 实战HMM-Viterbi角色标注地名识别
http://www.hankcs.com/nlp/ner/place-names-to-identify-actual-hmm-viterbi-role-labeling.html 命名实体识别(N ...
- word2vec原理浅析
1.word2vec简介 word2vec,即词向量,就是一个词用一个向量来表示.是2013年Google提出的.word2vec工具主要包含两个模型:跳字模型(skip-gram)和连续词袋模型( ...
- 论文笔记(1):Deep Learning.
论文笔记1:Deep Learning 2015年,深度学习三位大牛(Yann LeCun,Yoshua Bengio & Geoffrey Hinton),合作在Nature ...
- Nature重磅:Hinton、LeCun、Bengio三巨头权威科普深度学习
http://wallstreetcn.com/node/248376 借助深度学习,多处理层组成的计算模型可通过多层抽象来学习数据表征( representations).这些方法显著推动了语音识别 ...
随机推荐
- springboot项目自动关闭进程重启脚本
话不多说,先上脚本 kill -15 $(netstat -nlp | grep :9095 | awk '{print $7}' | awk -F"/" '{ print $1 ...
- java线程的interrup、tUninterruptibles.sleepUninterruptibly和sleep、wait
参考: (1)https://blog.csdn.net/qq_36031640/article/details/116696685 (2)https://blog.csdn.net/liuxiao7 ...
- GIS中的ROI文件可否由.xml格式转为.roi格式?
本文介绍在ENVI软件中,将用户自行绘制的.xml格式的感兴趣区(ROI)文件转换为.roi格式的方法. 对于ENVI软件,其在早期版本中,默认将用户所绘制的感兴趣区文件保存为.roi格式:而 ...
- 一文给你讲清楚BeanFactory 和 FactoryBean 的关联与区别
本文分享自华为云社区 <BeanFactory 和 FactoryBean 的关联与区别>,作者:战斧. 一.概括性的回答 两者其实都是Spring提供的接口,如下 public inte ...
- 2023-09-23:用go语言,假设每一次获得随机数的时候,这个数字大于100的概率是P。 尝试N次,其中大于100的次数在A次~B次之间的概率是多少? 0 < P < 1, P是double类型,
2023-09-23:用go语言,假设每一次获得随机数的时候,这个数字大于100的概率是P. 尝试N次,其中大于100的次数在A次~B次之间的概率是多少? 0 < P < 1, P是dou ...
- qq群匿名聊怎么用
qq群匿名聊怎么用 1 2 3 4 5 分步阅读 匿名的意思就是不认识.群匿名聊当然是把群里的马甲一下变成不认识的人,再在一起聊天.是不是觉得有点吃饱了没事干,但是当下该功能还是比较实用的,群匿名聊可 ...
- 黄金眼PAAS化数据服务DIFF测试工具的建设实践
一.背景介绍 黄金眼PAAS化数据服务是一系列实现相同指标服务协议的数据服务,各个服务间按照所生产指标的主题作划分,比如交易实时服务提供实时交易指标的查询,财务离线服务提供离线财务指标的查询.黄金眼P ...
- Util应用框架Web Api开发快速入门
本文是使用Util应用框架开发 Web Api 项目快速入门教程. 前面已经详细介绍了环境搭建,如果你还未准备好,请参考前文. 开发流程概述 创建代码生成专用数据库. Util应用框架需要专门用来生成 ...
- Jenkins软件平台安装部署
1.Jenkins软件平台概念剖解: 基于主流的Hudson/Jenkins平台工具实现全自动网站部署.网站测试.网站回滚会大大的减轻网站部署的成本,Jenkins的前身为Hudson,Hudson主 ...
- go语言写http踩得坑
1.在运行http时,报错:panic: listen tcp: address xxxx: missing port in address, 初始 代码如下 func HelloWordHander ...