探索开源工作流引擎Azkaban在MRS中的实践
摘要:本文主要介绍如何在华为云上从0-1搭建azkaban并指导用户如何提交作业至MRS。
本文分享自华为云社区《开源工作流引擎Azkaban在MRS中的实践》,作者:啊喔YeYe。
环境输入
实践版本:Apache azkaban 4.0.0 (以单机版举例,集群版本配置过程类似),MRS 3.1.0 普通集群。
Azkaban 插件地址
Azkaban 官网
Azkaban 源码地址
安装azkaban-solo-server
Azkaban不提供二进制包,需要用户下载源码编译打包,获取到“azkaban-solo-server.zip”和“azkaban-db.zip”。
1、环境准备。
- 在华为云购买Linux弹性云服务器ECS,用于安装运行MRS集群客户端和Azkaban,并绑定弹性公网IP。
- 在弹性云服务器ECS上安装运行MRS集群客户端,例如安装目录为“/opt/client”。
- 准备数据表,参考MySQL教程。
- 安装MySQL并授予本机访问权限。注意:Azkaban 4.0.0版本默认适配MySQL 5.1.28版本。
- 创建Azkaban数据库,解压“azkaban-db.zip”获取“create-all-sql-*.sql”,并初始化。
2、上传安装包并解压
- 上传“azkaban-solo-server.zip”至“/opt/azkaban”目录
- 执行以下命令解压并删除安装包
unzip azkaban-solo-server.zip
rm -f unzip azkaban-solo-server.zip
3、修改配置文件“azkaban-solo-server/conf/azkaban.properties”
配置端口根据实际情况修改,“jetty.port”和“mysql.port”端口号可使用默认值
jetty.port=8081
database.type=mysql
mysql.port=3306
mysql.host=x.x.x.x
mysql.database=azkaban
mysql.user=xxx
mysql.password=xxx
4、启动azkaban-solo-server
source /opt/client/bigdata_env
cd /opt/azkaban/azkaban-solo-server
sh bin/start-solo.sh
5、访问Azkaban WEB UI
在浏览器输入“http://ECS弹性IP:port”网址,进入Azkaban WebUI登录界面,输入用户信息登录Azkaban服务。

说明:
默认端口(port):8081;
用户名/密码:azkaban/azkaban;
用户账号配置文件: /opt/azkaban/azkaban-solo-server/conf/azkaban-users.xml
azkaban-hdfs-viewer plugin配置指导
连接HDFS需要用户下载源码编译获取“az-hdfs-viewer.zip”,并已完成安装azkaban-solo-server。
1、环境准备
- 配置Azkaban用户,添加supergroup用户组授予访问HDFS权限
- 在HDFS的配置文件“core-stie.xml”中增加Azkaban代理用户
a. 登录Manager页面,选择“集群 > 服务 > HDFS > 配置 > 全部配置 > HDFS(服务) > 自定义”
b. 在参数文件“core-site.xml”中添加如下配置项:
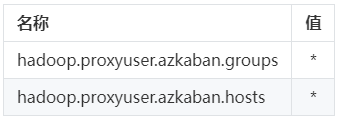
c. 配置完成后,单击左上角“保存”
d. 选择“概览 > 更多 > 重启服务”输入密码后重启HDFS服务
2、上传安装包并解压
- 上传“az-hdfs-viewer.zip”至“/opt/azkaban/azkaban-solo-server/plugins/viewer”目录
- 执行以下命令解压并删除安装包
unzip az-hdfs-viewer.zip
rm -f az-hdfs-viewer.zip
- 重命名解压后的文件名为"hdfs"
mv az-hdfs-viewer hdfs
3、修改并保存配置文件
- 修改"azkaban-solo-server/plugins/viewer/hdfs/conf/plugin.properties"文件中的代理用户为步骤1中配置的Azkaban代理用户。修改"execute-as-user"的存放目录为Azkaban安装目录,如"opt/azkaban/azkaban-solo-server"。
viewer.name=HDFS
viewer.path=hdfs
viewer.order=1
viewer.hidden=false
viewer.external.classpaths=extlib/*
viewer.servlet.class=azkaban.viewer.hdfs.HdfsBrowserServlet
hadoop.security.manager.class=azkaban.security.HadoopSecurityManager_H_2_0
azkaban.should.proxy=false
proxy.user=azkaban // mrs集群中配置的azkaban代理用户名
allow.group.proxy=true
file.max.lines=1000
#Specifying the error message we want user to get when they don't have permissionsviewer.access_denied_message=The folder you are trying to access is protected.
execute.as.user=false
// execute-as-user存放目录
azkaban.native.lib=/opt/azkaban/azkaban-solo-server
若不存在该文件需手动创建并配置以上内容
4、拷贝HDFS插件所需包至"/opt/azkaban/azkaban-solo-server/extlib"目录
cp /opt/client/HDFS/hadoop/share/hadoop/hdfs/*.jar /opt/azkaban/azkaban-solo-server/extlib
cp /opt/client/HDFS/hadoop/share/hadoop/client/hadoop-client-api-3.1.1-mrs-2.0.jar /opt/azkaban/azkaban-solo-server/extlib
cp /opt/client/HDFS/hadoop/share/hadoop/common/*.jar /opt/azkaban/azkaban-solo-server/extlib
不同MRS版本所需Hadoop相关版本不同,通过find /opt/client查询目
5、检查目录结构
目录结构应当为:
- azkaban-solo-server
- bin
- conf
- extlib (hadoop相关插件第三方包)
- lib
- logs
- plugins
- jobtypes(job插件目录)
- commonprivate.properties
- hive
- plugin.properties
- private.properties
- hadoopJava
- plugin.properties
- private.properties
- viewer
- hdfs
- conf
- plugin.properties
- lib (az-hdfs-viewer.zip解压后的lib)
- temp
- web
6、重启Azkaban-solo-server服务
cd /opt/azkaban/azkaban-solo-server
sh bin/shutdown-solo.sh
sh bin/start-solo.sh
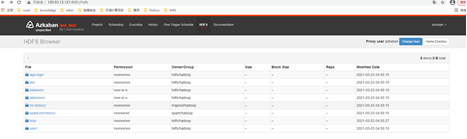
7、访问HDFS Browser
- 在浏览器输入“http://ECS弹性IP:8081”网址,进入Azkaban WebUI登录界面,输入用户信息登录Azkaban服务
- 单击"HDFS"
plugins-jobtypes hadoop-job 部署运行
安装azkaban-solo-server完成后,再部署验证hadoop-job
1、环境准备
- 获取"azkaban-plugins-3.0.0.zip"压缩包
- 编译获取azkaban提供的hadoopjava-wordcount实例程序包“az-hadoop-jobtype-plugin.jar”
2、上传插件配置文件
- 解压"azkaban-plugins-3.0.0.zip" 获取"azkaban-plugins-3.0.0\plugins\jobtype\jobtypes"下"hadoopJava"文件夹
- 将“hadoopJava”文件夹上传至“/plugin”目录。目录不存在则需新建
3、修改配置文件"azkaban-solo-server/plugins/jobtypes/commonprivate.properties"
# set execute-as-user
execute.as.user=false hadoop.security.manager.class=azkaban.security.HadoopSecurityManager_H_2_0
azkaban.should.proxy=false
obtain.binary.token=false
proxy.user=azkaban // MRS集群中配置的Azkaban代理用户名
allow.group.proxy=true
// execute-as-user存放目录
azkaban.native.lib=/opt/azkaban/azkaban-solo-server # hadoop
hadoop.home=/opt/client/HDFS/hadoop //opt/client为MRS集群客户端安装目录
hive.home=/opt/client/Hive/Beeline
spark.home=/opt/client/Spark/spark
hadoop.classpath=${hadoop.home}/etc/hadoop,${hadoop.home}/share/hadoop/common/*,${hadoop.home}/share/hadoop/common/lib/*,${hadoop.home}/share/hadoop/hdfs/*,${hadoop.home}/share/hadoop/hdfs/lib/*,${hadoop.home}/share/hadoop/yarn/*,${hadoop.home}/share/hadoop/yarn/lib/*,${hadoop.home}/share/hadoop/mapreduce/*,${hadoop.home}/share/hadoop/mapreduce/lib/*
jobtype.global.classpath=${hadoop.home}/etc/hadoop,${hadoop.home}/share/hadoop/common/*,${hadoop.home}/share/hadoop/common/lib/*,${hadoop.home}/share/hadoop/hdfs/*,${hadoop.home}/share/hadoop/hdfs/lib/*,${hadoop.home}/share/hadoop/yarn/*,${hadoop.home}/share/hadoop/yarn/lib/*,${hadoop.home}/share/hadoop/mapreduce/*,${hadoop.home}/share/hadoop/mapreduce/lib/*
4、示例程序验证
- 准备测试数据"input.txt"文件,文件内容可参考如下格式进行自定义,存放路径如"/opt/input.txt"
Ross male 33 3674
Julie male 42 2019
Gloria female 45 3567
Carol female 36 2813
- 通过HDFS客户端将测试数据"input.txt"上传至"hdfs /tmp/azkaban_test"
a. 以客户端安装用户,登录安装客户端的节点
b. 执行以下命令,切换到客户端安装目录 cd /opt/client
c. 执行以下命令配置环境变量 source bigdata_env
d. 执行HDFS Shell命令上传文件 hdfs dfs -put /opt/input.txt /tmp/azkaban_test - 用户在本地编写并保存“wordcount.job”文件,内容如下
type=hadoopJava
job.extend=false
job.class=azkaban.jobtype.examples.java.WordCount
classpath=./lib/*,/opt/azkaban-solo-server-0.1.0-SNAPSHOT/lib/*
force.output.overwrite=true
input.path=/tmp/azkaban_test
output.path=/tmp/azkaban_test_out
- 在浏览器输入“http://ECS弹性IP:port”网址,进入Azkaban WebUI登录界面,输入用户信息登录Azkaban服务,提交job运行验证

Spark command job—参考客户端命令
spark任务有两种运行方式,一种是command方式,另一种是spark jobtype方式。
- Command方式:需要指定spark_home为/opt/client/Spark/spark/
在MRS集群客户端节点可以通过echo $SPARK_HOME获取实际Spark安装地址。
设置azkanban所在ECS全局环境变量,添加source {MRS客户端}后需要重启azkaban才可生效 - jobtype方式:参考plugins-jobtypes hadoop-job 部署运行。
探索开源工作流引擎Azkaban在MRS中的实践的更多相关文章
- Java三大主流开源工作流引擎技术分析
首先,这个评论是我从网上,书中,搜索和整理出来的,也许有技术点上的错误点,也许理解没那么深入.但是我是秉着学习的态度加以评论,学习,希望对大家有用,进入正题! 三大主流工作流引擎:Shark,oswo ...
- .net开源工作流引擎ccflow
关于济南驰骋信息技术有限公司的.net开源工作流引擎 驰骋工作流引擎,工作流程管理系统:简称ccflow,驰骋一体化解决方案简称ccport. ccflow是济南驰骋信息技术有限公司向社会提供的一款1 ...
- Slickflow.NET 开源工作流引擎高级开发(三) -- 并行分支容器与会签工作流模式的组合
前言: 流程引擎的核心功能是负责解析流程定义XML和流转,业务环节的不断积累,让人们不断总结和抽象出一些模式,这些模式统称为工作流模式(Workflow Pattern).本文的重点就是介绍一种常见 ...
- 开源工作流引擎 Workflow Core 的研究和使用教程
目录 开源工作流引擎 Workflow Core 的研究和使用教程 一,工作流对象和使用前说明 二,IStepBuilder 节点 三,工作流节点的逻辑和操作 容器操作 普通节点 事件 条件体和循环体 ...
- .net开源工作流引擎ccflow表单数据返回值Pop分组模式和表格模式对比
Pop分组模式和表格模式对比 关键词: 驰骋工作流引擎 表单引擎 ccflow .net开源工作流 jflow Java工作流引擎 驰骋工作流程快速开发平台 工作流程管理系统 工作流引擎 a ...
- Slickflow.NET 开源工作流引擎基础介绍(二) -- 引擎组件和业务模块的交互
集成流程引擎的必要性 业务过程的变化是在BPM系统中常见的现象,企业管理层需要不断优化组织架构,改造业务流程,不可避免地带来了业务流程的变化,企业信息系统就会随之面临重构的可能性.一种直接的方式是改造 ...
- Slickflow.NET 开源工作流引擎基础介绍(六)--模块化架构设计和实践
前言:在集成Slickflow.NET 引擎组件过程中,引擎组件需要将用户,角色等资源数据读取进来,供引擎内部调用:而企业客户都是有自己的组织架构模型,在引入模块化架构设计后,引擎组件的集成性更加友好 ...
- .net开源工作流引擎ccflow Pop返回值设置
关键词: 点击字段弹出返回值填充文本框或其他字段 表单自动填充 .net开源工作流 jflow工作流 ccflow 工作流引擎 应用场景 当我们的查询信息比较多我们希望有一个比较 ...
- Slickflow.NET 开源工作流引擎基础介绍(二) -- 引擎组件和业务系统的集成
集成流程引擎的必要性 业务过程的变化是在BPM系统中常见的现象,企业管理层需要不断优化组织架构,改造业务流程,不可避免地带来了业务流程的变化,企业信息系统就会随之面临重构的可能性.一种直接的方式是改造 ...
- java开源工作流引擎jflow的流程应用类型分类讲解
关键字: 驰骋工作流程快速开发平台 工作流程管理系统 工作流引擎 asp.net工作流引擎 java工作流引擎. 开发者表单 拖拽式表单 工作流系统CCBPM节点访问规则接收人规则 适配数据库: o ...
随机推荐
- 回文自动机(PAM) 详解
PAM 是一种高效存储字符串中所有回文子串的自动机,用于解决回文串相关问题. 虽然代码稍微长一点,但写起来比 manacher 容易很多,毕竟没有加了一堆字符再转回原串的若干上取整下取整问题. 前置知 ...
- P3214 [HNOI2011] 卡农 题解
感觉不是很麻烦,可能就组合排列转化绕一点... 抽象化题意 给定 \(n\) 个元素,从中选出 \(m\) 个集合,要求: 集合不为空,集合里不能有相同的元素 \(m\) 个集合都互不相同 所有元素被 ...
- 1. JVM内存区块
本篇文章主要讲解Java(JVM)在运行期间,其运行时数据区域的作用.职责与划分.包括堆内存.栈内存--虚拟机栈.本地方法栈.方法区.常量池.程序计数器等概念. 采集可以使用JavaMXBean(采集 ...
- JUC并发编程学习笔记(九)阻塞队列
阻塞队列 阻塞 队列 队列的特性:FIFO(fist inpupt fist output)先进先出 不得不阻塞的情况 什么情况下会使用阻塞队列:多线程并发处理.线程池 学会使用队列 添加.移除 四组 ...
- Weight Balanced Leafy Tree 学习笔记
前言: 在这里十分十分感谢 \(\text{lxl}\) 和王思齐发明和总结了 \(\text{WBLT}\). 因为网上关于 \(\text{WBLT}\) 的正确讲解(已除去那篇国家集训队论文,不 ...
- 普冉PY32系列(十二) 基于PY32F002A的6+1通道遥控小车III - 驱动篇
目录 普冉PY32系列(一) PY32F0系列32位Cortex M0+ MCU简介 普冉PY32系列(二) Ubuntu GCC Toolchain和VSCode开发环境 普冉PY32系列(三) P ...
- 教你如何使用PyTorch解决多分类问题
本文分享自华为云社区<使用PyTorch解决多分类问题:构建.训练和评估深度学习模型>,作者: 小馒头学Python. 引言 当处理多分类问题时,PyTorch是一种非常有用的深度学习框架 ...
- springboot集成mybatis-plus
集成mybatis-plus 1.添加pom.xml <!--mp逆向工程 --> <dependency> <groupId>org.projectlombok& ...
- 在WPF应用中使用GongSolutions.WPF.DragDrop实现列表集合控件的拖动处理
WPF应用中,控件本身也可以通过实现事件代码实现拖动的处理,不过如果我们使用GongSolutions.WPF.DragDrop来处理,事情会变得更加简单轻松,它支持很多控件的拖动处理,如ListBo ...
- AtCoder_abc330
AtCoder_abc330 比赛链接 A - Counting Passes A题链接 题目大意 给出\(N\)个数\(a_1,a_2,a_3\cdots,a_N\),和一个正整数\(L\).输出有 ...