GaussDB for DWS:内存自适应控制技术总结
1.技术背景
在SQL语句复杂、处理数据量大的AP场景下,单个查询对内存的需求越来越大,多个语句的并发很容易将系统的内存吃满,造成内存不足的问题。为了应对这种问题,GaussDB for DWS引入了内存自适应控制的技术,在上述场景下能够对运行的作业进行内存级的管控,避免高并发场景下内存不足产生的各种问题。
2. GaussDB的静态内存管理机制及缺陷
GaussDB的执行引擎继承自PG,对于优化器生成的执行计划树,总体采取执行算子+流水线的处理方式,如下图所示。
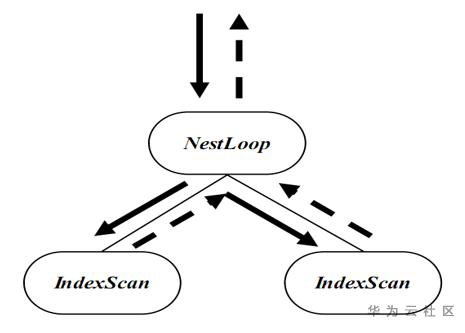
对于NestLoop算子节点,需要首先从左树的IndexScan算子节点获取元组,然后到右子树的IndexScan算子节点进行连接,匹配元组后进行输出。流水线的执行方式使得对于NestLoop, IndexScan类的一般算子,同时只有一定数量的元组处于内存中,对于行引擎每个算子仅占用一条元组的空间,对于列引擎占用一个batch(最多1000条元组)的空间,占用的空间较小,基本可以忽略不计。
但是,GaussDB中也有一些需要将所有数据收集后进行处理的算子,在执行时需要使用较多的内存,通常我们称这类算子为物化算子。GaussDB中主要存在如下不同种类的物化算子:
(1)HashJoin:Hash连接操作符,主要思想是计算左右两表连接列的hash值,通过hash值比较减少元组比较的次数,需要将一个表建立hash表,另一个表进行hash值比较操作,建立hash表需要在内存中进行。
(2)HashAgg:Hash聚集操作符,主要思想同HashJoin类似,通过hash值比较减少元组去重比较的次数,需要将不同值的元组保存的内存中。
(3)Sort:排序操作符,需要获取所有元组后进行排序操作,待排序元组均存在于内存中。
(4)Materialize:物化操作符,通常在需要重复扫描时使用,通过将结果存储在内存中,保证重复扫描时的效率。
同时,GaussDB也提供下盘的机制,当上述操作符需要使用的内存太大时,可以将部分或全部的数据下盘处理,提高内存的使用效率,但相应的查询性能也会受到影响。PG使用 work_mem参数来控制算子可使用内存的阈值,当使用内存超过阈值时,就需要做下盘处理。GaussDB的静态内存管理机制也延续了PG的处理机制,使用work_mem来控制单算子的内存使用上限。
GaussDB的静态内存管理存在较大弊端,需要调优人员能够根据数据量、语句复杂程度和系统的内存大小设置合理的work_mem,既避免work_mem设置太大导致系统资源不够用,还要考虑到数据规模,保证大部分算子不下盘。通常情况下,这个是很难做到的,有以下几点原因:
(1)通常情况下,复杂语句的执行计划中包含多个复杂算子,每个算子的内存使用上限是work_mem,我们没有办法计算一个语句要使用多少内存,因此也就不容易设置一个最优的work_mem参数,保证尽可能不下盘,同时内存又够用。并发场景更无法设置了。
(2)work_mem只是每个算子内存使用的上限,并不是预分配;如果数据量没有那么大的话,实际内存使用是达不到work_mem的。因此也会影响work_mem的设置。
(3)每个语句的场景不一样,有的语句包含多个物化算子,而另外的语句只有一个物化算子,而这个算子对内存的需求会比较大,因此无法全局统一地进行设置。
3. GaussDB的内存自适应技术介绍
针对静态内存管理机制的弊端,我们设计了内存自适应控制技术,目的有两个:
(1)去除静态内存管理对work_mem的依赖。可以由SQL引擎优化器模块自动估算每个算子所需的内存。
(2)避免大并发场景下内存不足现象的发生。资源管理模块根据SQL引擎优化器对于每个查询内存的估算值,对每个查询进行调度,如果超过系统可用内存,则进行排队。
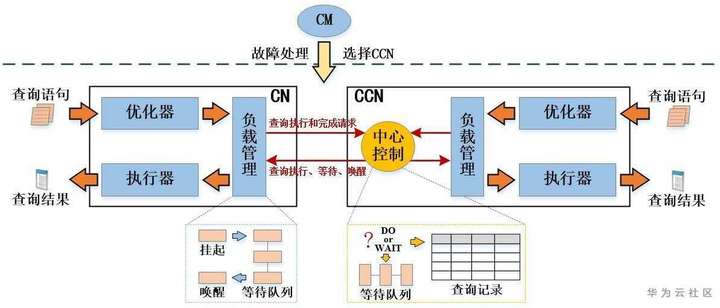
如上图所示,动态资源管理与内存自适应技术的组件图如上图所示。我们从多个CN中选择一个CN,命名为CCN(Central CN),进行语句队列的管理。对于每个查询SQL,CN在生成完执行计划后,为每个物化算子分配合适的内存,同时计算整个语句内存使用量,并将语句及对应的内存使用量发给CCN。CCN维护系统可用的内存值,对于新来的语句,如果语句内存使用量小于可用内存值,则允许其下发到DN执行,否则挂起,等到有语句结束释放内存后再次将其唤醒,是否可以下发。
为了达到上述目的,SQL引擎实现了内存自适应控制技术,步骤如下:
(1)对于每个SQL,生成计划前首先从资源管理模块获取系统当前的最大可用内存(Query Max Mem)和当前可用内存(System Available Mem)。最大可用内存通常为每个DN的最大可用内存去除系统预分配内存,例如:数据缓存等,表示语句可用的最大内存,如果语句使用内存超过该值,必须下盘。当前可用内存用于表示当前系统的繁忙程度,如果当前可用内存比较小,倾向于选择耗费内存少的计划。
(2)依据当前可用内存生成计划,同时根据SQL引擎优化器计划生成过程中的cost估算值估算每个物化算子的内存使用量,以及流水线场景下整个查询使用的内存总量估算值。如果该值大于当前可用内存,则尝试将整个查询的内存使用量调到当前可用内存以下,此时会造成部分算子下盘。
(3)将语句及估算的语句内存发送到CCN,如果当前可用内存小于语句估算内存,则估算语句的内存进一步减少是否对查询性能造成较大的影响,如果根据cost评估影响不大,则进一步减少算子的内存使用,使语句内存使用满足当前可用内存,将语句下发执行,否则则进入排队状态。
(4)由于每个算子的内存使用量是基于cost评估获得,可能存在一定的误差。因此,在SQL语句执行时,支持内存的动态调整,包括:执行算子内存的自动扩展和提前下盘。当算子达到估算的内存值上限,但系统还有宽裕的内存时,会进行算子内存的扩展,继续保持不下盘的状态。当系统已用内存达到80%或更高时,如果算子已有最小内存保证,则会触发提前下盘逻辑,保证不会由于内存不足而报错。
4.GaussDB内存自适应的使用和参数控制
通过开启use_workload_manager和enable_dynamic_workload两个参数开启GaussDB for DWS的内存自适应控制机制。
使用内存自适应机制时,打印SQL语句的explain performance执行计划运行信息时,会包含以下额外的信息辅助定位问题:
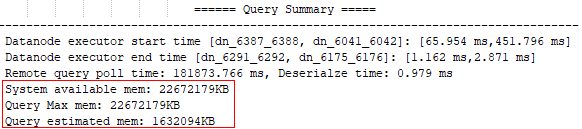
(1)在最下方的Query Summary一栏中,会显示出System available mem、Query max mem和Query estimated mem,分别表示:系统当前可用内存、语句可用最大内存(系统可用最大内存),语句估算内存使用量,均为单DN的衡量值。下图表示当前语句的语句最大可用内存和系统当前可用内存均为22G,语句估算内存使用为1.6G。
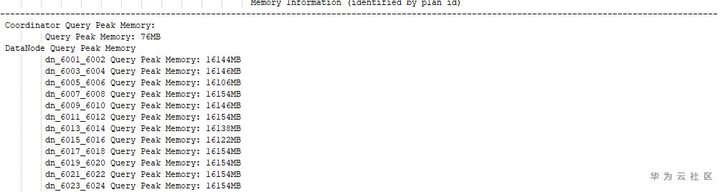
(2)在Memory Information一栏,会显示CN和每个DN的内存使用峰值,如下图所示,语句实际内存使用,单DN使用16GB,CN使用76MB。
(3)在Memory Information一栏下方每个算子对应的位置,会显示每个算子单DN的内存峰值,同时会显示每个DN上内存使用的自动扩展和提前下盘情况,例如下图,可以看出第15号HashJoin算子,每个SMP线程的内存使用均为3.8GB,估算内存是860MB,经历了五次内存自动扩展,在第五次扩展后,系统内存告急,算子未用到第五次扩展后的峰值即提前下盘。

(4)在explain performance最顶层的表格中,汇总了每个算子的估算内存和实际使用内存的情况,见下图的E-memory和Peak Memory两列所示。与上面信息对应,第15号算子单SMP线程的peak memory,最大值为3766MB,最小值为3753MB,估算内存值(单DN4个SMP线程)为860MB。

可以看出,上面例子由于cost估算不准导致内存估算值较小,实际场景也会出现内存估算值较大的场景,会导致CCN预留内存较多,阻塞其它作业的执行。因此,可以使用参数query_mem来控制语句最大可用内存上限(单DN),相当于代替了Query max mem。此参数默认为0,表示未开启。当此值大于32MB(最小语句内存分配值)时,表示开启,此时使用work_mem控制系统当前可用内存进行估算,相当于代替了System available mem进行估算。此时,CCN会使用query_mem值进行语句内存估算值的预留和排队,提高并发场景下的内存使用效率。
5.总结
内存自适应控制技术是GaussDB for DWS的资源管理结合SQL引擎所做的一次尝试,当然还存在一些不足,比如:cost估算对内存的评估影响较大,部分场景存在失真需要进行参数控制;系统中内存使用情况比较复杂,还存在部分内存不在管控范围内需要增强。欢迎各位在实用过程中,将遇到的各种问题及时反馈,也帮助我们更好的改进!
GaussDB for DWS:内存自适应控制技术总结的更多相关文章
- 华为云GaussDB(DWS)内存知识点,你知道吗?
前言 在日常数据库的使用中,难免会遇到一些内存问题.此次博文主要向大家分享一些华为云数仓GaussDB(DWS)内存的基本框架以及基本视图的使用,以便遇到内存问题后可以有一个基本的判断. 注意,本篇博 ...
- 内核不中断前提下,Gaussdb(DWS)内存报错排查方法
摘要:本文主要讲解如何在内核保证操作不能中断采取的特殊处理,理论上用户执行的sql使用的内存(dynamic_used_memory) 是不会大范围的超过max_dynamic_memory的内存的 ...
- GaussDB(DWS)应用实践丨负载管理与作业排队处理方法
摘要:本文用来总结一些GaussDB(DWS)在实际应用过程中,可能出现的各种作业排队的情况,以及出现排队时,我们应该怎么去判断是否正常,调整一些参数,让资源分配与负载管理更符合当前的业务:或者在作业 ...
- 细说GaussDB(DWS)复杂多样的资源负载管理手段
摘要:对于如此多的管控功能,管控起来实际的效果到底如何,本篇文章就基于当前最新版本,进行效果实测,并进行一定的分析说明. 本文分享自华为云社区<GaussDB(DWS) 资源负载管理:并发管控以 ...
- 从数据仓库双集群系统模式探讨,看GaussDB(DWS)的容灾设计
摘要:本文主要是探讨OLAP关系型数据库框架的数据仓库平台如何设计双集群系统,即增强系统高可用的保障水准,然后讨论一下GaussDB(DWS)的容灾应该如何设计. 当前社会.企业运行当中,大数据分析. ...
- BA-siemens-apogee自适应控制
简介 APOGEE楼控系统的控制器中,包括了由 Cybosoft开发的基于无模型自适应控制技术的自适应控制. 自适应控制是一个复杂的闭环循环控制算 法.自适应控制能自动校正参数以补偿机械的系 统/负载 ...
- 阿里开源 Dragonwell JDK 重磅发布 GA 版本:生产环境可用
今年 3 月份,阿里巴巴重磅开源 OpenJDK 长期支持版本 Alibaba Dragonwell的消息,在很长一段时间内都是开发者的讨论焦点,该项目在 Github 上的 Star 数迅速突破 1 ...
- openEuler 20.03/21.03 - 华为欧拉开源版(CentOS 8 华为版开源版)下载
开始 openEuler 之旅吧 openEuler 通过社区合作,打造创新平台,构建支持多处理架构.统一和开放的操作系统,推动软硬件应用生态繁荣发展. 好玩的活动停不下来 openEuler 社区不 ...
- 一文详解GaussDB(DWS) 的并发管控和内存管控
摘要:DWS的负载管理分为两层,第一层为cn的全局并发控制,第二层为资源池级别的并发控制. 本文分享自华为云社区<GaussDB(DWS) 并发管控&内存管控>,作者: fight ...
- 详解GaussDB(DWS) explain分布式执行计划
摘要:本文主要介绍如何详细解读GaussDB(DWS)产生的分布式执行计划,从计划中发现性能调优点. 前言 执行计划(又称解释计划)是数据库执行SQL语句的具体步骤,例如通过索引还是全表扫描访问表中的 ...
随机推荐
- mol 文件格式简单解析(v2000)
前言 .mol 文件是常见的化学文件格式,主要包含分子的坐标.分子间的键等数据. 示例文件 下面是一个水分子的 .mol 文件 H2O APtclcactv05052315543D 0 0.00000 ...
- Little Victor and Set 题解
Little Victor and Set 题目大意 在 \([l,r]\) 中选不超过 \(k\) 个相异的数使得异或和最小,输出方案. 思路分析 分类讨论: 当 \(k=1\) 时: 显然选 \( ...
- js数据结构--数组
<!DOCTYPE html> <html> <head> <title></title> </head> <body&g ...
- 【NOI 2023 春测】 游寄
3.2 发出发通知单:9:40 3.3 旷操,把背包扔到 \(\texttt{JF}\) 底下,和 Kaguya 一起去吃早饭. 在桥下面被老班抓到了() 我用椅子给 apj 搭了一张床. Apj 给 ...
- [C++]STL - 队列(Queue) 栈(Stack) 链表(list)
STL - 队列(Queue) 栈(Stack) 链表(list) Queue 队列 结构特征 这是一种线性储存结构 其数据有先进先出的特点 这种特点被称为FIFO(First In First Ou ...
- gitlab : You won`t be able to pull or push project code via SSH until you add an SSH key to your profile(导致的问题:合并不了代码)
gitlab : You won`t be able to pull or push project code via SSH until you add an SSH key to your pro ...
- 从BST到LSM的进阶之路
前言 相信大家之前都了解过很多种数据结构,我之前总是两两的,也就是从局部上去进行比较,没有从整体上进行这些树的发展脉络进行梳理,因此经常看完没多久就忘了.看来确实是需要从本源出发,不仅要知其然还要知其 ...
- Kubernetes 漫游:kube-scheduler
概述 什么是 kube-scheduler ? Kubernetes 集群的核心组件之一,它负责为新创建的 Pods 分配节点.它根据多种因素进行决策,包括: 资源需求和限制:考虑每个 Pod 请求的 ...
- ETL-txt数据转换为Excel数据
前言: 将txt文件中的数据抽取出来,然后装载到Excel中. 具体操作步骤: 数据准备 id,name,age,gender,province,city,region,phone,birth ...
- 目标检测工具安装使用--labelImg
如果想要在深度学习中训练我们自己的模型,就得对图片进行标注.labelImg是一个超级方便的目标检测图片标注工具,打开图片后,只需用鼠标框出图片中的目标,并选择该目标的类别,便可以自动生成voc格式的 ...