昇腾CANN DVPP硬件加速训练数据预处理,友好解决Host CPU预处理瓶
本文分享自华为云社区《昇腾CANN 7.0 黑科技:DVPP硬件加速训练数据预处理,友好解决Host CPU预处理瓶颈》,作者: 昇腾CANN 。
在NPU/GPU上进行模型训练计算,为了充分使用计算资源,一般采用批量数据处理方式,因此一般情况下为提升整体吞吐率,batch值会设置的比较大,常见的batch数为256/512,这样一来,对数据预处理处理速度要求就会比较高。对于AI框架来说,常见的应对方式是采用多个CPU进程并发处理,比如PyTorch框架的torchvision就支持多进程并发,使用多个CPU进程来进行数据预处理,以满足与NPU/GPU的计算流水并行处理。
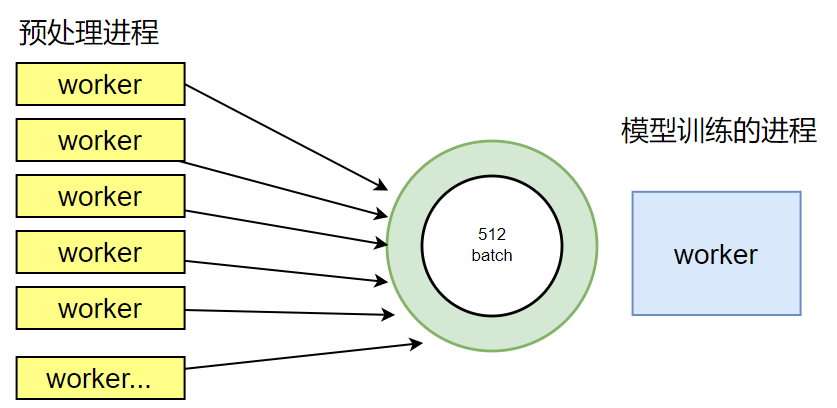
然而,随着NPU算力和性能的倍速提升,host CPU数据预处理过程逐渐成为性能瓶颈。模型端到端训练时间会因为数据预处理的瓶颈而拉长,这种情况下,如何解决性能瓶颈,提升端到端模型执行性能呢?
# Data loading code
traindir = os.path.join(args.data, 'train')
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
train_dataset = datasets.ImageFolder(
traindir,
transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize,
]))
import torchvision_npu # 导入torchvision_npu包
# Data loading code
traindir = os.path.join(args.data, 'train')
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
torchvision_npu.set_image_backend('npu') # 设置图像处理后端为npu
train_dataset = datasets.ImageFolder(
traindir,
transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize,
]))
if img.device.type == 'npu': _assert_image_npu(img) return F_npu.resize(img, size=size, interpolation=interpolation.value)
return torch.ops.torchvision.npu_resize(img, size=sizes, mode=mode)

下面来看下替换之后的性能如何。以ImageNet中最常见的分辨率375*500的jpeg图片为例,CPU上执行预处理操作需要6.801ms:

使用DVPP不但能加速数据预处理,还能异步执行host下发任务和device任务,整个流程只需要2.25ms,单张图片处理节省了60%+的时间。
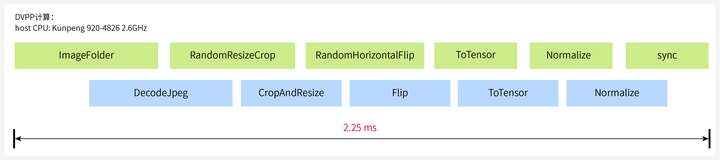
在ResNet50训练过程中,512batch数据处理只需要1.152 s,预处理多进程处理场景下性能优势更加明显。
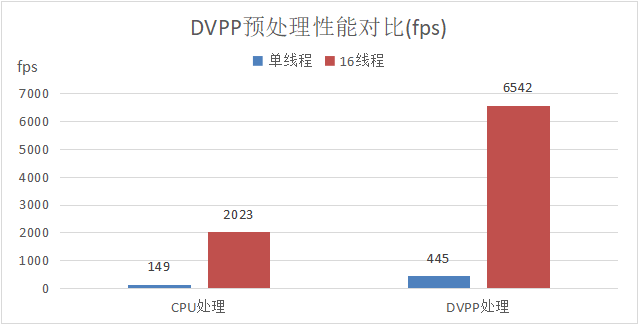
基于Atlas 800T A2 训练服务器,ResNet50使用DVPP加速数据预处理,单P只需要6个预处理进程即可把NPU的算力跑满;而使用CPU预处理,则需要12个预处理进程才能达到相应的效果,大大减少了对host CPU的性能依赖。
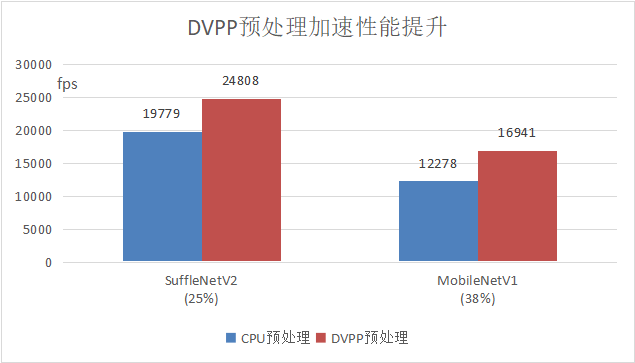
典型网络场景,基于Atlas 800T A2 训练服务器,在CPU预处理成为性能瓶颈的情况下,使用DVPP预处理加速即可获得整网训练速度显著提升,其中ShuffleNetV2整网性能提升25%,MobileNetV1提升38%。
昇腾CANN内置的预处理算子是比较丰富的,后续在继续丰富torchvision预处理算子库的同时,也会进一步提升预处理算子的下发和执行流程,让流水处理的更好,减少数据处理的时间,持续提升昇腾CANN的产品竞争力,满足更广泛的业务场景诉求。
昇腾CANN DVPP硬件加速训练数据预处理,友好解决Host CPU预处理瓶的更多相关文章
- 『TensorFlow』SSD源码学习_其五:TFR数据读取&数据预处理
Fork版本项目地址:SSD 一.TFR数据读取 创建slim.dataset.Dataset对象 在train_ssd_network.py获取数据操作如下,首先需要slim.dataset.Dat ...
- CANN训练:模型推理时数据预处理方法及归一化参数计算
摘要:在做基于Ascend CL模型推理时,通常使用的有OpenCV.AIPP.DVPP这三种方式,或者是它们的混合方式,本文比较了这三种方式的特点,并以Resnet50的pytorch模型为例,结合 ...
- 图形性能(widgets的渲染性能太低,所以推出了QML,走硬件加速)和网络性能(对UPD性能有实测数据支持)
作者:JasonWong链接:http://www.zhihu.com/question/37444226/answer/72007923来源:知乎著作权归作者所有,转载请联系作者获得授权. ---- ...
- 开发实践丨昇腾CANN的推理应用开发体验
摘要:这是关于一次 Ascend 在线实验的记录,主要内容是通过网络模型加载.推理.结果输出的部署全流程展示,从而快速熟悉并掌握 ACL(Ascend Computing Language)基本开发流 ...
- 一键抠除路人甲,昇腾CANN带你识破神秘的“AI消除术”
摘要:都说人工智能改变了生活,你感觉到了么?AI的魔力就在你抠去路人甲的一瞬间来到了你身边.今天就跟大家聊聊--神秘的"AI消除术". 引语 旅途归来,重温美好却被秀丽河山前的路人 ...
- 英特尔® 至强® 平台集成 AI 加速构建数据中心智慧网络
英特尔 至强 平台集成 AI 加速构建数据中心智慧网络 SNA 通过 AI 方法来实时感知网络状态,基于网络数据分析来实现自动化部署和风险预测,从而让企业网络能更智能.更高效地为最终用户业务提供支撑. ...
- 昇腾CANN论文上榜CVPR,全景图像生成算法交互性再增强!
摘要:近日,CVPR 2022放榜,基于CANN的AI论文<Interactive Image Synthesis with Panoptic Layout Generation>强势上榜 ...
- ffmpeg实现dxva2硬件加速
这几天在做dxva2硬件加速,找不到什么资料,翻译了一下微软的两篇相关文档.这是第二篇,记录用ffmpeg实现dxva2. 第一篇翻译的Direct3D device manager,链接:http: ...
- Qt 框架的图形性能高(OpenGL上的系统效率高),网络性能低,开发效率高,Quick是可以走硬件加速——Qt中分为好几套图形系统,差不多代表了2D描画的发展史。最经典的软描画系统
-----图形性能部分-----Qt的widgets部分,运行时的图像渲染性能是一般的,因为大部分的界面内容都是Qt自绘,没有走硬件加速,也就是说很多图形内容都是CPU算出来的.但是widgets底层 ...
- 英特尔® 硬件加速执行管理器安装指南 — Microsoft Windows*
介绍 本文将指导您安装英特尔® 硬件加速执行管理器(英特尔® HAXM),这是一款可以使用英特尔® 虚拟化技术(VT)加快 Android* 开发速度的硬件辅助虚拟化引擎(管理程序). 前提条件 英特 ...
随机推荐
- 浅谈关于LCA
prologue 本身只会 tarjan 和 倍增法求LCA 的,但在发现有一种神奇的\(O(1)\) 查询 lca 的方法,时间优化很明显. main body 倍增法 先讨论倍增法,倍增法求 lc ...
- Util应用框架Web Api开发环境搭建
要使用Util应用框架开发项目,首先需要搭建合适的开发环境. 迈出第一步,对于很多.Net新人可能并不简单. 如果你对.Net环境并不熟悉,请尽量按照本文档进行操作. 操作系统 请安装 Windows ...
- 怎么用Python写一个浏览器集群框架
这是做什么用的 框架用途 在采集大量新闻网站时,不可避免的遇到动态加载的网站,这给配模版的人增加了很大难度.本来配静态网站只需要两个技能点:xpath和正则,如果是动态网站的还得抓包,遇到加密的还得j ...
- [Python急救站课程]天天向上的力量
我们要"好好学习,天天向上."那么天天向上的力量到底有多强呢? 1.一年365天,以第1天的能力值为基数,记为1.0,当好好学习时能力值相比前一天提高1‰,当没有学习时由于遗忘等原 ...
- Ubuntu 20.04 查看显示器信息
安装 ddcutil apt install ddcutil 输入命令 ddcutil detect --verbose 输出类似如下: Output level: Verbose Reporting ...
- 一文彻底看懂Python切片
1.什么是切片 切片是Python中一种用于操作序列类型(如列表.字符串和元组)的方法.它通过指定起始索引和结束索引来截取出序列的一部分,形成一个新的序列.切片是访问特定范围内的元素,就是一个Area ...
- 在EXCEL表格中快速自动求和
在Microsoft Excel中,可以通过多种方式快速自动求和.以下是一种简单但常用的方法: 使用SUM函数 选定求和区域: 在Excel表格中,首先需要选定要进行求和的区域.这可以是一个列.行或者 ...
- 上传代码到github和删除.git
在本地建立目录,将想上传的代码放到该文件夹中 git init ###初始化 git add . ###将本地项目工作区的所有文件添加到暂存区 git commit -m "excu&quo ...
- 高效的 Json 解析框架 kotlinx.serialization
一.引出问题 你是否有在使用 Gson 序列化对象时,见到如下异常: Abstract classes can't be instantiated! Register an InstanceCreat ...
- [ABC318G] Typical Path Problem
Problem Statement You are given a simple connected undirected graph $G$ with $N$ vertices and $M$ ed ...