自然语言处理 Paddle NLP - 快递单信息抽取 (ERNIE 1.0)
文档检索:需要把业务问题拆解成子任务。文本分类 -> 文本匹配 -> 等任务 -> Panddle API 完成子任务 -> 子任务再拼起来
介绍
在2017年之前,工业界和学术界对文本处理依赖于序列模型Recurrent Neural Network (RNN).
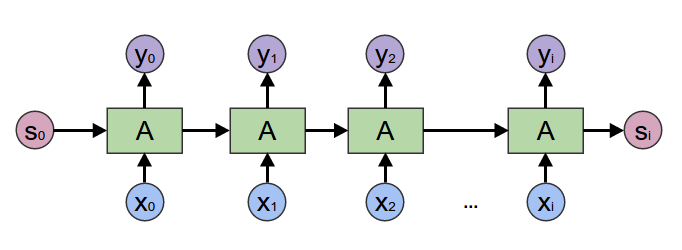
图1:RNN示意图
基于BiGRU+CRF的快递单信息抽取项目介绍了如何使用序列模型完成快递单信息抽取任务。
近年来随着深度学习的发展,模型参数的数量飞速增长。为了训练这些参数,需要更大的数据集来避免过拟合。然而,对于大部分NLP任务来说,构建大规模的标注数据集非常困难(成本过高),特别是对于句法和语义相关的任务。相比之下,大规模的未标注语料库的构建则相对容易。为了利用这些数据,我们可以先从其中学习到一个好的表示,再将这些表示应用到其他任务中。最近的研究表明,基于大规模未标注语料库的预训练模型(Pretrained Models, PTM) 在NLP任务上取得了很好的表现。
近年来,大量的研究表明基于大型语料库的预训练模型(Pretrained Models, PTM)可以学习通用的语言表示,有利于下游NLP任务,同时能够避免从零开始训练模型。随着计算能力的不断提高,深度模型的出现(即 Transformer)和训练技巧的增强使得 PTM 不断发展,由浅变深。
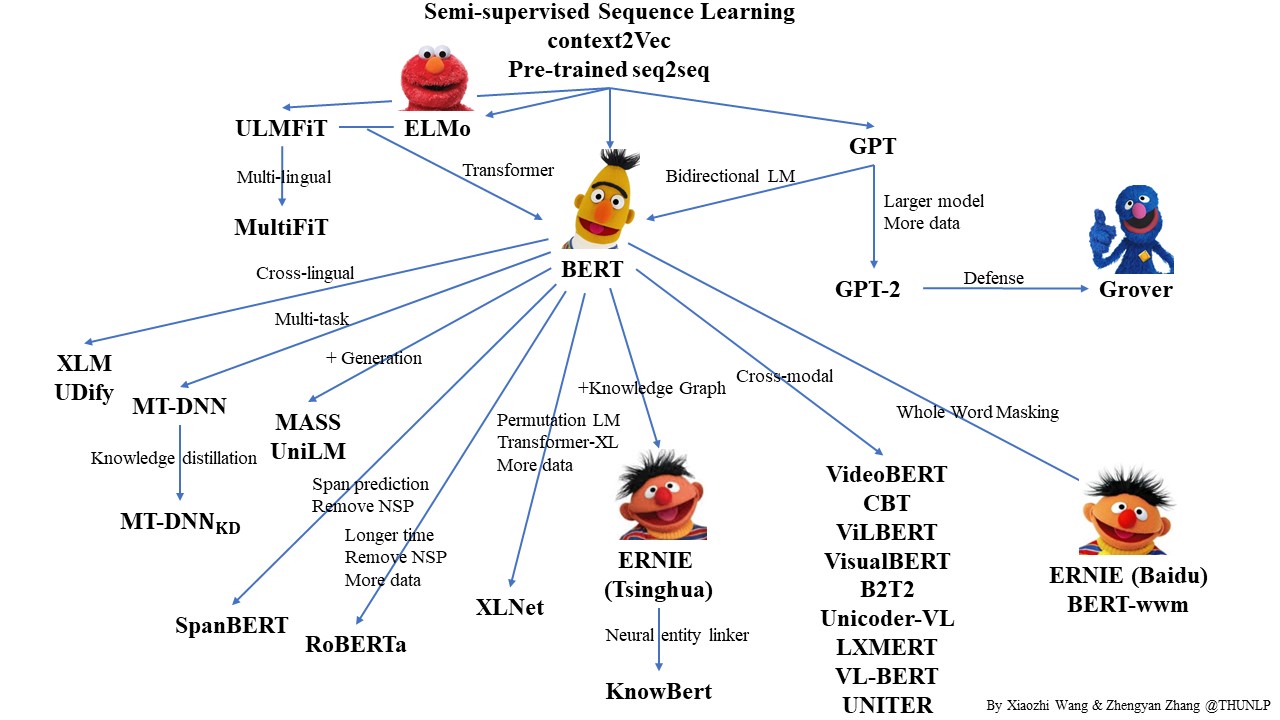
图2:预训练模型一览,图片来源于:https://github.com/thunlp/PLMpapers
本示例展示了以ERNIE(Enhanced Representation through Knowledge Integration)为代表的预训练模型如何Finetune完成序列标注任务。
实体定义标注
命名实体识别是NLP中一项非常基础的任务,是信息提取、问答系统、句法分析、机器翻译等众多NLP任务的重要基础工具。命名实体识别的准确度,决定了下游任务的效果,是NLP中的一个基础问题。在NER任务提供了两种解决方案,一类LSTM/GRU + CRF,通过RNN类的模型来抽取底层文本的信息,而CRF(条件随机场)模型来学习底层Token之间的联系;另外一类是通过预训练模型,例如ERNIE,BERT模型,直接来预测Token的标签信息。
本项目将演示如何使用PaddleNLP语义预训练模型ERNIE完成从快递单中抽取姓名、电话、省、市、区、详细地址等内容,形成结构化信息。辅助物流行业从业者进行有效信息的提取,从而降低客户填单的成本。
典型的命名实体识别(Named Entity Recognition,NER)场景,各实体类型及相应符号表示见下表:
张三18625584663广东省深圳市南山区百度国际大厦
人工定义实体,标注符号
| 抽取实体/字段 | 符号 | 抽取结果 |
|---|---|---|
| 姓名 | P | 张三 |
| 电话 | N | 13812345678 |
| 省 | A1 | 广东省 |
| 市 | A2 | 深圳市 |
| 区 | A3 | 南山区 |
| 详细地址 | A4 | 百度国际大厦 |
在序列标注任务中,一般会定义一个标签集合,来表示所以可能取到的预测结果。上文中针对需要抽取的“姓名、电话、省、市、区、详细地址”等实体,标签集合可以定义为:
label={P-B,P-I,T-B,T-I,A1-B,A1-I,A2-B,A2-I,A3-B,A3-I,A4-B,A4-I,0)
| 标签 | 定义 |
|---|---|
| P-B | 姓名起始位置 |
| P-I | 姓名中间位置或结束位置 |
| T-B | 电话起始位置 |
| T-I | 电话中间位置或结束位置 |
| A1-B | 省份起始位置 |
| A1-I | 省份中间位置或结束位置 |
| A2-B | 城市起始位置 |
| A2-I | 城市中间位置或结束位置 |
| A3-B | 县区起始位置 |
| A3-I | 县区中间位置或结束位置 |
| A4-B | 详细地址起始位置 |
| A4-I | 详细地址中间位置或结束位置 |
| O | 无关字符 |
注意每个标签的结果只有 B、I、O 三种,这种标签的定义方式叫做 BIO 体系,BIO(B-begin,I-inside,O-other) 标签转换,
B:表示一个标签类别的开头,比如 P-B 指的是姓名的开头
I:中间或结束,表示一个标签的延续
O:不想抽取的,无用的实体
对于句子“张三18625584663广东省深圳市南山区百度国际大厦”,每个汉字及对应标签为:
图3:数据集标注示例

注意到“张“,”三”在这里表示成了“P-B” 和 “P-I”,“P-B”和“P-I”合并成“P” 这个标签。这样重新组合后可以得到以下信息抽取结果:
| 张三 | 18625584663 | 广东省 | 深圳市 | 南山区 | 百度国际大厦 |
|---|---|---|---|---|---|
| P | T | A1 | A2 | A3 | A4 |
准备
# 下载并解压数据集
from paddle.utils.download import get_path_from_url
URL = "https://paddlenlp.bj.bcebos.com/paddlenlp/datasets/waybill.tar.gz"
get_path_from_url(URL, "./")
# 查看预测的数据
!head -n 5 data/test.txt
text_a label
黑龙江省双鸭山市尖山区八马路与东平行路交叉口北40米韦业涛18600009172 A1-BA1-IA1-IA1-IA2-BA2-IA2-IA2-IA3-BA3-IA3-IA4-BA4-IA4-IA4-IA4-IA4-IA4-IA4-IA4-IA4-IA4-IA4-IA4-IA4-IA4-IP-BP-IP-IT-BT-IT-IT-IT-IT-IT-IT-IT-IT-IT-I
广西壮族自治区桂林市雁山区雁山镇西龙村老年活动中心17610348888羊卓卫 A1-BA1-IA1-IA1-IA1-IA1-IA1-IA2-BA2-IA2-IA3-BA3-IA3-IA4-BA4-IA4-IA4-IA4-IA4-IA4-IA4-IA4-IA4-IA4-IA4-IT-BT-IT-IT-IT-IT-IT-IT-IT-IT-IT-IP-BP-IP-I
15652864561河南省开封市顺河回族区顺河区公园路32号赵本山 T-BT-IT-IT-IT-IT-IT-IT-IT-IT-IT-IA1-BA1-IA1-IA2-BA2-IA2-IA3-BA3-IA3-IA3-IA3-IA4-BA4-IA4-IA4-IA4-IA4-IA4-IA4-IA4-IP-BP-IP-I
河北省唐山市玉田县无终大街159号18614253058尚汉生 A1-BA1-IA1-IA2-BA2-IA2-IA3-BA3-IA3-IA4-BA4-IA4-IA4-IA4-IA4-IA4-IA4-IT-BT-IT-IT-IT-IT-IT-IT-IT-IT-IT-IP-BP-IP-I
from functools import partial
import paddle
from paddlenlp.datasets import MapDataset
from paddlenlp.data import Stack, Tuple, Pad
from paddlenlp.transformers import ErnieTokenizer, ErnieForTokenClassification
from paddlenlp.metrics import ChunkEvaluator # 词与块的指标 不是 A1-B 对了就算对,A1-B~A1I 全对了才算对
from utils import convert_example, evaluate, predict, load_dict
加载自定义数据集
推荐使用MapDataset()自定义数据集。
def load_dataset_1(datafiles):
def read(data_path):
with open(data_path, 'r', encoding='utf-8') as fp:
next(fp) # Skip header
for line in fp.readlines():
words, labels = line.strip('\n').split('\t')
words = words.split('\002')
labels = labels.split('\002')
yield words, labels
if isinstance(datafiles, str):
return MapDataset(list(read(datafiles)))
elif isinstance(datafiles, list) or isinstance(datafiles, tuple):
return [MapDataset(list(read(datafile))) for datafile in datafiles]
# Create dataset, tokenizer and dataloader.
train_ds, dev_ds, test_ds = load_dataset_1(datafiles=(
'./data/train.txt', './data/dev.txt', './data/test.txt'))
for i in range(5):
print(train_ds[i])
(['1', '6', '6', '2', '0', '2', '0', '0', '0', '7', '7', '宣', '荣', '嗣', '甘', '肃', '省', '白', '银', '市', '会', '宁', '县', '河', '畔', '镇', '十', '字', '街', '金', '海', '超', '市', '西', '行', '5', '0', '米'], ['T-B', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'P-B', 'P-I', 'P-I', 'A1-B', 'A1-I', 'A1-I', 'A2-B', 'A2-I', 'A2-I', 'A3-B', 'A3-I', 'A3-I', 'A4-B', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I'])
(['1', '3', '5', '5', '2', '6', '6', ...
每条数据包含一句文本和这个文本中每个汉字以及数字对应的label标签。
之后,还需要对输入句子进行数据处理,如切词,映射词表id等。
数据处理
预训练模型ERNIE对中文数据的处理是以字为单位。PaddleNLP对于各种预训练模型已经内置了相应的tokenizer。指定想要使用的模型名字即可加载对应的tokenizer。
tokenizer作用为将原始输入文本转化成模型model可以接受的输入数据形式。
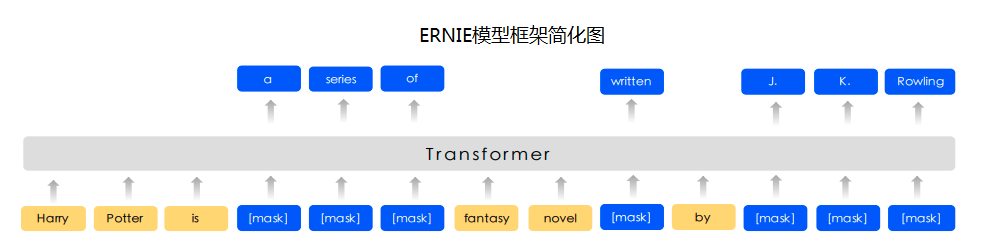
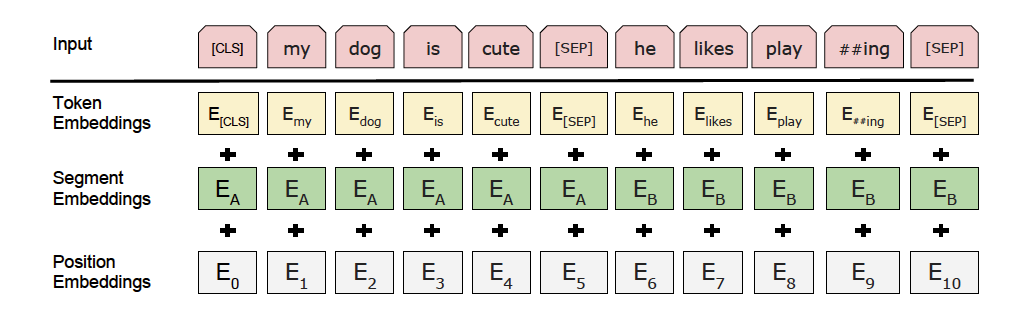
图3:ERNIE模型示意图
utils.py 工具类
import numpy as np
import paddle
import paddle.nn.functional as F
from paddlenlp.data import Stack, Tuple, Pad
def load_dict(dict_path):
vocab = {}
i = 0
for line in open(dict_path, 'r', encoding='utf-8'):
key = line.strip('\n')
vocab[key] = i
i+=1
return vocab
def convert_example(example, tokenizer, label_vocab):
tokens, labels = example
tokenized_input = tokenizer(
tokens, return_length=True, is_split_into_words=True)
# Token '[CLS]' and '[SEP]' will get label 'O'
labels = ['O'] + labels + ['O']
tokenized_input['labels'] = [label_vocab[x] for x in labels]
return tokenized_input['input_ids'], tokenized_input[
'token_type_ids'], tokenized_input['seq_len'], tokenized_input['labels']
@paddle.no_grad()
def evaluate(model, metric, data_loader):
model.eval()
metric.reset()
for input_ids, seg_ids, lens, labels in data_loader:
logits = model(input_ids, seg_ids)
preds = paddle.argmax(logits, axis=-1)
n_infer, n_label, n_correct = metric.compute(None, lens, preds, labels)
metric.update(n_infer.numpy(), n_label.numpy(), n_correct.numpy())
precision, recall, f1_score = metric.accumulate()
print("eval precision: %f - recall: %f - f1: %f" %
(precision, recall, f1_score))
model.train()
def predict(model, data_loader, ds, label_vocab):
pred_list = []
len_list = []
for input_ids, seg_ids, lens, labels in data_loader:
logits = model(input_ids, seg_ids)
pred = paddle.argmax(logits, axis=-1)
pred_list.append(pred.numpy())
len_list.append(lens.numpy())
preds = parse_decodes(ds, pred_list, len_list, label_vocab)
return preds
def parse_decodes(ds, decodes, lens, label_vocab):
decodes = [x for batch in decodes for x in batch]
lens = [x for batch in lens for x in batch]
id_label = dict(zip(label_vocab.values(), label_vocab.keys()))
outputs = []
for idx, end in enumerate(lens):
sent = ds.data[idx][0][:end]
tags = [id_label[x] for x in decodes[idx][1:end]]
sent_out = []
tags_out = []
words = ""
for s, t in zip(sent, tags):
if t.endswith('-B') or t == 'O':
if len(words):
sent_out.append(words)
tags_out.append(t.split('-')[0])
words = s
else:
words += s
if len(sent_out) < len(tags_out):
sent_out.append(words)
outputs.append(''.join(
[str((s, t)) for s, t in zip(sent_out, tags_out)]))
return outputs
def predict(model, data_loader, ds, label_vocab):
pred_list = []
len_list = []
for input_ids, seg_ids, lens, labels in data_loader:
logits = model(input_ids, seg_ids)
pred = paddle.argmax(logits, axis=-1)
pred_list.append(pred.numpy())
len_list.append(lens.numpy())
preds = parse_decodes(ds, pred_list, len_list, label_vocab)
return preds
label_vocab = load_dict('./data/tag.dic')
tokenizer = ErnieTokenizer.from_pretrained('ernie-1.0') # 现在3.0 了
# convert_example => utils.py,先把Id读出来,加了 CLS
# label_vocab => 13个分类 cat tag.dic
# tokenizer => ERNIE 字典里面对应的位置
trans_func = partial(convert_example, tokenizer=tokenizer, label_vocab=label_vocab)
train_ds.map(trans_func)
dev_ds.map(trans_func)
test_ds.map(trans_func)
print (train_ds[0])
数据读入
使用paddle.io.DataLoader接口多线程异步加载数据。
ignore_label = -1 # 在交叉熵计算时,PAD 位,就不会参与计算,目的:为了减少计算量
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input_ids
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # token_type_ids
Stack(), # seq_len
Pad(axis=0, pad_val=ignore_label) # labels
): fn(samples)
train_loader = paddle.io.DataLoader(
dataset=train_ds,
batch_size=36, # 看性能监控,空闲多的话可以调大
return_list=True,
collate_fn=batchify_fn)
dev_loader = paddle.io.DataLoader(
dataset=dev_ds,
batch_size=36,
return_list=True,
collate_fn=batchify_fn)
test_loader = paddle.io.DataLoader(
dataset=test_ds,
batch_size=36,
return_list=True,
collate_fn=batchify_fn)
PaddleNLP一键加载预训练模型
快递单信息抽取本质是一个序列标注任务,PaddleNLP对于各种预训练模型已经内置了对于下游任务文本分类Fine-tune网络。以下教程以ERNIE为预训练模型完成序列标注任务。
paddlenlp.transformers.ErnieForTokenClassification()一行代码即可加载预训练模型ERNIE用于序列标注任务的fine-tune网络。其在ERNIE模型后拼接上一个全连接网络进行分类。
paddlenlp.transformers.ErnieForTokenClassification.from_pretrained()方法只需指定想要使用的模型名称和文本分类的类别数即可完成定义模型网络。
# Define the model netword and its loss
model = ErnieForTokenClassification.from_pretrained("ernie-1.0", num_classes=len(label_vocab))
PaddleNLP不仅支持ERNIE预训练模型,还支持BERT、RoBERTa、Electra等预训练模型。
下表汇总了目前PaddleNLP支持的各类预训练模型。您可以使用PaddleNLP提供的模型,完成文本分类、序列标注、问答等任务。同时我们提供了众多预训练模型的参数权重供用户使用,其中包含了二十多种中文语言模型的预训练权重。中文的预训练模型有bert-base-chinese, bert-wwm-chinese, bert-wwm-ext-chinese, ernie-1.0, ernie-tiny, gpt2-base-cn, roberta-wwm-ext, roberta-wwm-ext-large, rbt3, rbtl3, chinese-electra-base, chinese-electra-small, chinese-xlnet-base, chinese-xlnet-mid, chinese-xlnet-large, unified_transformer-12L-cn, unified_transformer-12L-cn-luge等。
更多预训练模型参考:PaddleNLP Transformer API。
更多预训练模型fine-tune下游任务使用方法,请参考:examples。
设置Fine-Tune优化策略,模型配置
适用于ERNIE/BERT这类Transformer模型的迁移优化学习率策略为warmup的动态学习率。
先慢慢加速,再衰减
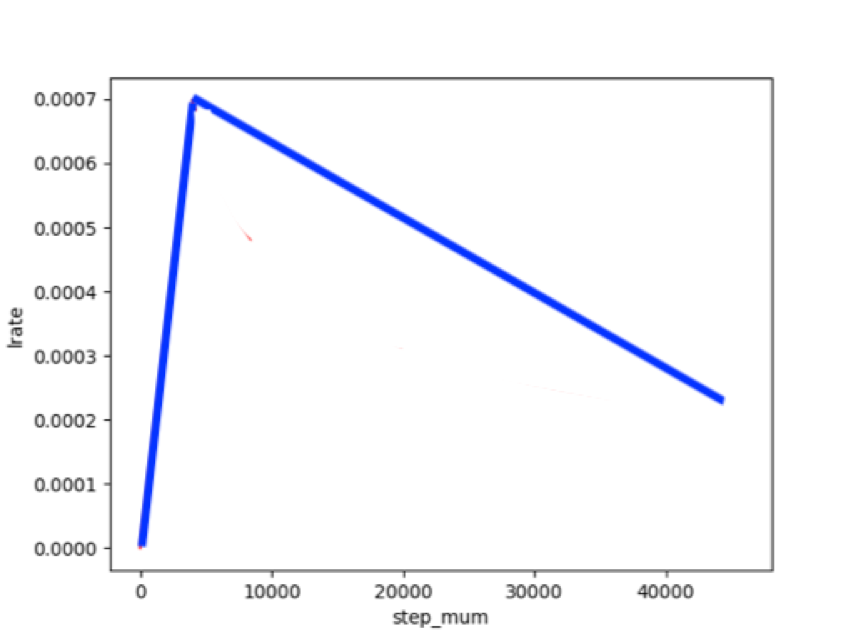
图4:动态学习率示意图
# 定义评测指标
metric = ChunkEvaluator(label_list=label_vocab.keys(), suffix=True)
loss_fn = paddle.nn.loss.CrossEntropyLoss(ignore_index=ignore_label) # 忽略标签计算,如果都是PAD标签参与计算,费力不讨好 -1 不参与交叉熵计算
optimizer = paddle.optimizer.AdamW(learning_rate=2e-5, parameters=model.parameters())
模型训练与评估
模型训练的过程通常有以下步骤:
- 从dataloader中取出一个batch data
- 将batch data喂给model,做前向计算
- 将前向计算结果传给损失函数,计算loss。将前向计算结果传给评价方法,计算评价指标。
- loss反向回传,更新梯度。重复以上步骤。
每训练一个epoch时,程序将会评估一次,评估当前模型训练的效果。
step = 0
for epoch in range(10):
for idx, (input_ids, token_type_ids, length, labels) in enumerate(train_loader):
logits = model(input_ids, token_type_ids)
loss = paddle.mean(loss_fn(logits, labels))
loss.backward()
optimizer.step()
optimizer.clear_grad()
step += 1
print("epoch:%d - step:%d - loss: %f" % (epoch, step, loss))
evaluate(model, metric, dev_loader)
paddle.save(model.state_dict(),
'./ernie_result/model_%d.pdparams' % step)
# model.save_pretrained('./checkpoint')
# tokenizer.save_pretrained('./checkpoint')
wc -l /data/train.txt # 1601 条训练集
epoch:0 - step:1 - loss: 2.623411
epoch:0 - step:2 - loss: 2.393340
epoch:0 - step:3 - loss: 2.246286
epoch:0 - step:4 - loss: 2.080738
epoch:0 - step:5 - loss: 1.959701
epoch:0 - step:6 - loss: 1.842479
epoch:0 - step:7 - loss: 1.765124
epoch:0 - step:8 - loss: 1.621435
epoch:0 - step:9 - loss: 1.590034
epoch:0 - step:10 - loss: 1.503715

模型预测
训练保存好的模型,即可用于预测。如以下示例代码自定义预测数据,调用predict()函数即可一键预测。
preds = predict(model, test_loader, test_ds, label_vocab)
file_path = "ernie_results.txt"
with open(file_path, "w", encoding="utf8") as fout:
fout.write("\n".join(preds))
# Print some examples
print(
"The results have been saved in the file: %s, some examples are shown below: "
% file_path)
print("\n".join(preds[:10]))
想要更准一点,可以加上 PaddleNLP提供了CRF Layer
摘要生成:中文用 GPT-2、英文用 ERNIE-GEN 模型
原文:
视频:https://aistudio.baidu.com/aistudio/course/introduce/24177?sharedLesson=1459080&sharedType=2&sharedUserId=2631487&ts=1686018319058
项目:https://aistudio.baidu.com/aistudio/projectdetail/6333693?forkThirdPart=1&sUid=2631487&shared=1&ts=1686018298519
自然语言处理 Paddle NLP - 快递单信息抽取 (ERNIE 1.0)的更多相关文章
- [信息抽取]基于ERNIE3.0的多对多信息抽取算法:属性关系抽取
[信息抽取]基于ERNIE3.0的多对多信息抽取算法:属性关系抽取 实体关系,实体属性抽取是信息抽取的关键任务:实体关系抽取是指从一段文本中抽取关系三元组,实体属性抽取是指从一段文本中抽取属性三元组: ...
- NLP知识图谱项目合集(信息抽取、文本分类、图神经网络、性能优化等)
NLP知识图谱项目合集(信息抽取.文本分类.图神经网络.性能优化等) 这段时间完成了很多大大小小的小项目,现在做一个整体归纳方便学习和收藏,有利于持续学习. 1. 信息抽取项目合集 1.PaddleN ...
- 基于ERNIELayout&pdfplumber-UIE的多方案学术论文信息抽取
本项目链接:https://aistudio.baidu.com/aistudio/projectdetail/5196032?contributionType=1 基于ERNIELayout& ...
- 个人永久性免费-Excel催化剂功能第97波-快递单号批量查询物流信息
电商时代,快递已进千万家,做电商零售行业的,快递信息的再挖掘,也显得更有意义,是数据精细化运营中必不可少的一环.一般站在系统的角度,数据用于业务流转的增删改查使用,而对于分析需求来说,这些业务系统里集 ...
- 自然语言处理(NLP)知识结构总结
自然语言处理知识太庞大了,网上也都是一些零零散散的知识,比如单独讲某些模型,也没有来龙去脉,学习起来较为困难,于是我自己总结了一份知识体系结构,不足之处,欢迎指正.内容来源主要参考黄志洪老师的自然语言 ...
- 2023计算机领域顶会(A类)以及ACL 2023自然语言处理(NLP)研究子方向领域汇总
2023年的计算语言学协会年会(ACL 2023)共包含26个领域,代表着当前前计算语言学和自然语言处理研究的不同方面.每个领域都有一组相关联的关键字来描述其潜在的子领域, 这些子领域并非排他性的,它 ...
- 基于Label studio实现UIE信息抽取智能标注方案,提升标注效率!
基于Label studio实现UIE信息抽取智能标注方案,提升标注效率! 项目链接见文末 人工标注的缺点主要有以下几点: 产能低:人工标注需要大量的人力物力投入,且标注速度慢,产能低,无法满足大规模 ...
- java抓取快递100信息接口
package zeze; import java.io.IOException; import org.json.JSONArray; import org.json.JSONException; ...
- php快递单号查询源码
贴下记录下php查询快递单号的源码,能查询各种快递的快递单号记录,中通.圆通快递.顺丰快递等都不是问题.只需要在 爱快递(www.aikuaidi.cn)上面申请一个快递key即可,下面把源码分享下, ...
- ACL2016信息抽取与知识图谱相关论文掠影
实体关系推理与知识图谱补全 Unsupervised Person Slot Filling based on Graph Mining 作者:Dian Yu, Heng Ji 机构:Computer ...
随机推荐
- vue之头像管理思路
思路是在vant库中使用插件将上传的头像转码存入数据库中.每个用户存一个,不同用户就有不同的头像了.若数据库中没有头像,那么就给一个默认头像 头像上传后端接口: var express = requi ...
- 使用kubeadm初始化IPV4/IPV6集群
使用kubeadm初始化IPV4/IPV6集群 图片 CentOS 配置YUM源 cat <<EOF > /etc/yum.repos.d/kubernetes.repo [kube ...
- Bootstrapd导航条使用
要想在程序中集成Bootstrap,显然要对模板做所有必要的改动.不过,更简单的方法是使用一个名为Flask-Bootstrap 的Flask 扩展,简化集成的过程. 安装:Flask-Bootstr ...
- python文字转语音库及使用方法
作者:陈哲链接:https://www.zhihu.com/question/473797102/answer/2019063801来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请 ...
- 高可用(keepalived)部署方案
前言:为了减少三维数据中心可视化管理系统的停工时间,保持其服务的高度可用性.同时部署多套同样的三维可视化系统,让三维数据中心可视化系统同时部署并运行到多个服务器上.同时提供一个虚拟IP,然后外面通过这 ...
- 部署:mysql搭建多主一从源复制环境
问题描述:搭建过一主多从的环境,由于数据库数据一致性要求高,有些情景会搭建一主多从的架构,搭建多主一从的模式,相对来说适合数据整合,将多个业务的库整合到一起,方便做查询,也可以当做一个监控其他主库数据 ...
- Yii初学者必看-yii 表单验证规则
对yii深入了解总结出:希望对初学者有些帮助 Active Record (AR) 是一个流行的 对象-关系映射 (ORM) 技术. 每个 AR 类代表一个数据表(或视图),数据表(或视图)的列在 A ...
- YOLO精讲------YOLOV1
CV小白说YOLOV1 题外话: 目标检测是什么? 它是在图像中对一类或多类感兴趣的目标进行查找和分类,确定它们的类别和位置.由于各类物体有不同的外观.形状和姿态,加上成像时各种因素的干扰,目标检测一 ...
- 自定义Mybatis-plus插件(限制最大查询数量)
自定义Mybatis-plus插件(限制最大查询数量) 需求背景 一次查询如果结果返回太多(1万或更多),往往会导致系统性能下降,有时更会内存不足,影响系统稳定性,故需要做限制. 解决思路 1.经 ...
- Java:Should I use a `HashSet` or a `TreeSet` for a very large dataset?
这是StackOverflow上一个有意思的提问,记录一下. 原地址在这 翻译: 对于大型数据集,应该使用"哈希集"还是"树集"? (因为HashTable有着 ...