Pandas对象(数据结构)
Pandas是Python的一个扩展程序库,是在Numpy基础上建立的,提供高性能、易使用的数据结构和数据分析工具。
Pandas 可以从各种文件格式比如 CSV、JSON、SQL、Excel 等中导入数据;
Pandas 可以对各种数据进行运算操作,比如归并、再成形、选择,还有数据清洗和数据加工特征;
Pandas 广泛应用在学术、金融、统计学等各个数据分析领域。
Pandas对象(数据结构)
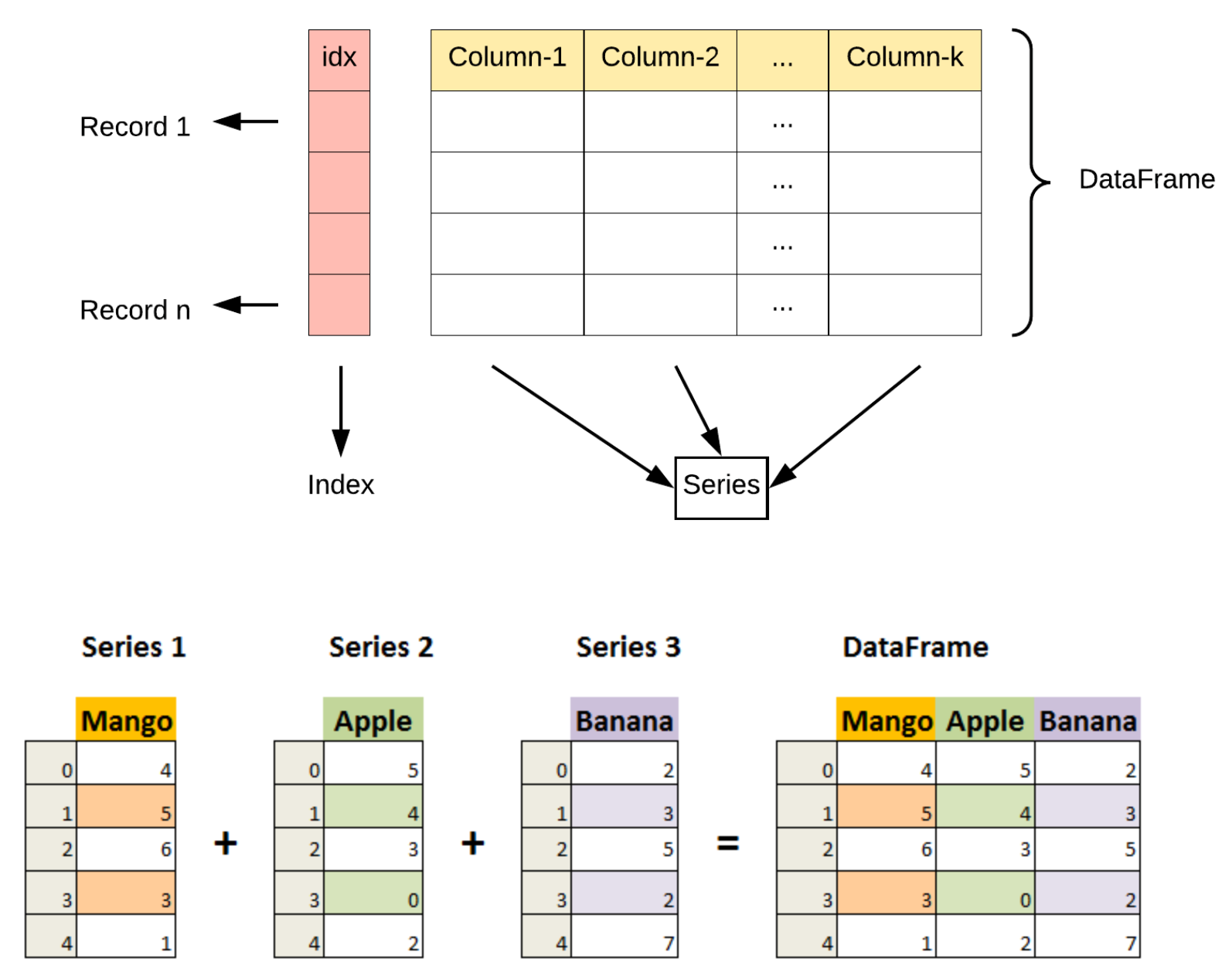
Pandas 三个基本的数据结构是 :Series (一维数据对象)、 DataFrame(二维数据对象)和 Index(标签对象)。Pandas数据对象可以看成增强版的Numpy数组,不过行列不仅仅只是简单的数据索引,还可以带上标签,是一种显式定义的索引,索引可以是重复的。
Series对象
Series对象是一个带索引数据构成的一维数组。
pandas.Series(data, index, dtype, name, copy)
参数说明:
data:一组数据(ndarray、字典、列表类型等)。
index:数据索引标签,如果不指定,默认从 0 开始。
dtype:数据类型,默认会自己判断。
name:设置名称。
copy:拷贝数据,默认为 False。
In [1]: import pandas as pd
#输入的数组可以是列表或Numpy数组,index默认整数序列
In [2]: data = pd.Series([0.3,0.05,1,30])
In [3]: data
Out[3]:
0 0.30
1 0.05
2 1.00
3 30.00
dtype: float64
In [4]: data.index #Series的索引是一个pd.Index类型对象
Out[4]: RangeIndex(start=0, stop=4, step=1)
In [5]: data[0] #和Numpy一样可以通过整数索引进行取值
Out[5]: 0.3
#添加显性索引,索引会覆盖顺序整数索引,但是两种索引方式都可用
In [8]: data = pd.Series([0.3,0.07,3,4],index=['a','b','c','d'])
In [9]: data
Out[9]:
a 0.30
b 0.07
c 3.00
d 4.00
dtype: float64
In [10]: data[1]
Out[10]: 0.07
In [11]: data['b']
Out[11]: 0.07
#添加显性整数索引,索引会覆盖原来顺序整数索引,原来的顺序整数索引不可用
In [12]: data = pd.Series([0.23,9,3,6],index=[2,7,3,9])
In [13]: data
Out[13]:
2 0.23
7 9.00
3 3.00
9 6.00
dtype: float64
In [14]: data[2]
Out[14]: 0.23
#输入一个字典,index默认为排序的key值
In [15]: population_dict = {'California': 3333333,
'Texas': 233242321,'New York': 43897653,
'Florida':32097644,'Illinois':2222229}
In [16]: population = pd.Series(population_dict)
In [17]: population
Out[17]:
California 3333333
Texas 233242321
New York 43897653
Florida 32097644
Illinois 2222229
dtype: int64
In [18]: population['Texas']
Out[18]: 233242321
#显性索引也具有切片功能
In [19]: population['California':'New York']
Out[19]:
California 3333333
Texas 233242321
New York 43897653
dtype: int64
#也可以输入一个标量,每个索引上都重复赋值
In [20]: pd.Series(3,index=['a','b','c'])
Out[20]:
a 3
b 3
c 3
dtype: int64
#筛选索引应用
In [21]: pd.Series({'a':1,'b':2,'c':3},index=['a','c'])
Out[21]:
a 1
c 3
dtype: int64
DataFrame对象
DataFrame对象可以看成是有序排列的若干Series对象,DataFrame除了有index属性外,还有columns属性。
pandas.DataFrame( data, index, columns, dtype, copy)
参数说明:
data:一组数据(ndarray、series, map, lists, dict 等类型)。
index:索引值,或者可以称为行标签。
columns:列标签,默认为 RangeIndex (0, 1, 2, …, n) 。
dtype:数据类型。
copy:拷贝数据,默认为 False。
#通过单个Series创建
In [22]: pd.DataFrame(population,columns=['population'])
Out[22]:
population
California 3333333
Texas 233242321
New York 43897653
Florida 32097644
Illinois 2222229
#通过字典列表创建,缺失值用NaN补充
In [23]: data = [{'a':i,'b':i**2} for i in range(5)]
In [24]: pd.DataFrame(data)
Out[24]:
a b
0 0 0
1 1 1
2 2 4
3 3 9
4 4 16
In [25]: pd.DataFrame([{'a':1,'b':2},
{'c':3,'b':4}])
Out[25]:
a b c
0 1.0 2 NaN
1 NaN 4 3.0
#通过Series对象字典创建
In [26]: area = pd.Series({'California': 3883333, 'Texas': 233771,'New York':435653,
'Florida':320644,'Illinois':2224429})
In [27]: area
Out[27]:
California 3883333
Texas 233771
New York 435653
Florida 320644
Illinois 2224429
dtype: int64
In [28]: population
Out[28]:
California 3333333
Texas 233242321
New York 43897653
Florida 32097644
Illinois 2222229
dtype: int64
In [29]: pd.DataFrame({'population':population,'area':area})
Out[29]:
population area
California 3333333 3883333
Texas 233242321 233771
New York 43897653 435653
Florida 32097644 320644
Illinois 2222229 2224429
#通过Numpy二维数组创建
In [30]: import numpy as np
In [31]: pd.DataFrame(np.random.rand(3,2),columns=['a','b'],index=['ff','dd','gg'])
Out[31]:
a b
ff 0.258254 0.591041
dd 0.091217 0.029136
gg 0.822554 0.661956
#通过Numpy结构化数组创建
In [32]: A = np.zeros(3,dtype=[('a','i8'),('b','f8')])
In [33]: A
Out[33]: array([(0, 0.), (0, 0.), (0, 0.)], dtype=[('a', '<i8'), ('b', '<f8')])
In [34]: pd.DataFrame(A)
Out[34]:
a b
0 0 0.0
1 0 0.0
2 0 0.0
Index对象
Series和DataFrame对象的显性索引其实是一个Index对象,可以看做一个不可变的数组或有序集合(元素可以重复)。
In [35]: ind = pd.Index([2,3,5,7])
In [36]: ind
Out[36]: Int64Index([2, 3, 5, 7], dtype='int64')
#可以像数组一样索引
In [37]: ind[1]
Out[37]: 3
In [38]: ind[::2]
Out[38]: Int64Index([2, 5], dtype='int64')
#与数组有相似的属性
In [40]: print(ind.size,ind.shape,ind.ndim,ind.dtype)
4 (4,) 1 int64
#可以进行数集运算
In [41]: indA = pd.Index([1,3,5,7,9])
In [42]: indB = pd.Index([2,3,5,7,8])
In [43]: indA & indB #交集
Out[43]: Int64Index([3, 5, 7], dtype='int64')
In [44]: indA | indB #并集
Out[44]: Int64Index([1, 2, 3, 5, 7, 8, 9], dtype='int64')
In [45]: indA ^ indB #异或
Out[45]: Int64Index([1, 2, 8, 9], dtype='int64')
Pandas对象(数据结构)的更多相关文章
- Pandas 的数据结构
Pandas的数据结构 导入pandas: 三剑客 from pandas import Series,DataFrame import pandas as pd import numpy as np ...
- pandas的数据结构之series
Pandas的数据结构 1.Series Series是一种类似于一维数组的对象,由下面两个部分组成: index:相关的数据索引标签 values:一组数据(ndarray类型) series的创建 ...
- Pandas之数据结构
pandas入门 由于最近公司要求做数据分析,pandas每天必用,只能先跳过numpy的学习,先学习大Pandas库 Pandas是基于Numpy构建的,让以Numpy为中心的应用变得更加简单 pa ...
- pandas 的数据结构(Series, DataFrame)
Pandas 讲解 Python Data Analysis Library 或 pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的. Pandas 纳入了大量库和一些标 ...
- Pandas常用数据结构
Pandas 概述 Pandas(Python Data Analysis Library)是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的.Pandas 纳入了大量库和一些标准的数 ...
- pandas 学习 第1篇:pandas基础 - 数据结构和数据类型
pandas是基于NumPy构建的模块,含有使数据分析更快更简单的操作工具和数据结构,是数据分析必不可少的五个包之一.pandas包含序列Series和数据框DataFrame两种最主要数据结构,索引 ...
- pandas中数据结构-Series
pandas中数据结构-Series pandas简介 Pandas是一个开源的,BSD许可的Python库,为Python编程语言提供了高性能,易于使用的数据结构和数据分析工具.Python与Pan ...
- Pandas的使用(3)---Pandas的数据结构
Pandas的使用(3) Pandas的数据结构 1.Series 2.DataFrame
- ES6中的Set和Map对象数据结构
set对象数据结构 构建某一类型的对象 -对象的实例化 let arr = [1, 2, 3, 3, 4, 5] let rec = new Set(arr)//可以传参数,数组或者对象 consol ...
- 02. Pandas 1|数据结构Series、Dataframe
1."一维数组"Series Pandas数据结构Series:基本概念及创建 s.index . s.values # Series 数据结构 # Series 是带有标签的一 ...
随机推荐
- 【Azure 应用服务】如果发现当前使用的订阅无法在China North 3 区中创建App Service服务,如何来解决这个问题呢?
问题描述 在创建App Service服务时,突然发现无法选择China North 3区域,如何来解决这个问题呢? 问题解答 根据Azure中服务都需要在订阅中注册的原理,因为China North ...
- Nebula Graph 特性讲解——RocksDB 统计信息的收集和展示
由于 Nebula Graph 的底层存储使用了 RocksDB,出于运维管理需要,我们的社区用户 @chenxu14 在 pr#2243 为 Nebula Graph 贡献了 RocksDB 统计信 ...
- 十五: InnoDB的存储结构
InnoDB的存储结构 1.数据库的存储结构:页 索引结构给我们提供了高效的索引方式,不过索引|信息以及数据记录都是保存在文件上的,确切说是存储在页结构中.另一方面,索引是在存储引擎中实现的,MySQ ...
- java基本数据类型及运算的注意事项
java基本数据类型及运算的注意事项 一.基本数据类型 序号 类型 位数 范围 说明 整数类型 (最高位为符号位) byte 8位 -128(-27)~127(27-1) 默认类型为int 二进制0b ...
- isPrimitive()方法和包装类
java.lang.Class.isprimitive()是说:确定指定的Class对象是基本类型,其返回是个boolean值,true代表你指定的这个Class对象是基本类型,false代表这个Cl ...
- 使用Java给图片添加水印
什么是水印呢?比如使用手机拍摄一张照片的时候,照片右下角的位置显示得有日期和时间信息,那就表示一个水印. 项目开发中给图片添加水印的操作很常见,比如给图片添加日期和时间,给图片添加公司的logo之类的 ...
- 深度观察2024中国系统架构师大会(SACC)
今年的中国系统架构师大会(SACC)在我所在的城市广州举办,很荣幸受邀参加.这次能接触到国内最优秀的架构师,学习他们的架构思想和行业经验.对我而言非常有意义. 大会分为上下午共4场,我参加了上午的多云 ...
- docker相关命令杂理
- 2020.11.16docker commit [OPTIONS] CONTAINER [REPOSITORY[:TAG]] #保存现有的镜像 # docker commit -a "r ...
- Python 汇总列数据到行
Python汇总Excel列数据到行(方法一) import pandas as pd # 读取Excel文件 df = pd.read_excel('C:\\Users\\liuchunlin2\\ ...
- 《Go程序设计语言》学习笔记之数组
<Go程序设计语言>学习笔记之数组 一. 环境 Centos8.5, go1.17.5 linux/amd64 二. 概念 数组是具有固定长度且拥有零个或多个相同数据类型元素的序列. 三. ...