实战|如何低成本训练一个可以超越 70B Llama2 的模型 Zephyr-7B
每一周,我们的同事都会向社区的成员们发布一些关于 Hugging Face 相关的更新,包括我们的产品和平台更新、社区活动、学习资源和内容更新、开源库和模型更新等,我们将其称之为「Hugging News」。快来看看有哪些近期更新吧!
新的训练方法 Zephyr-7B 模型超越 70B Llama2
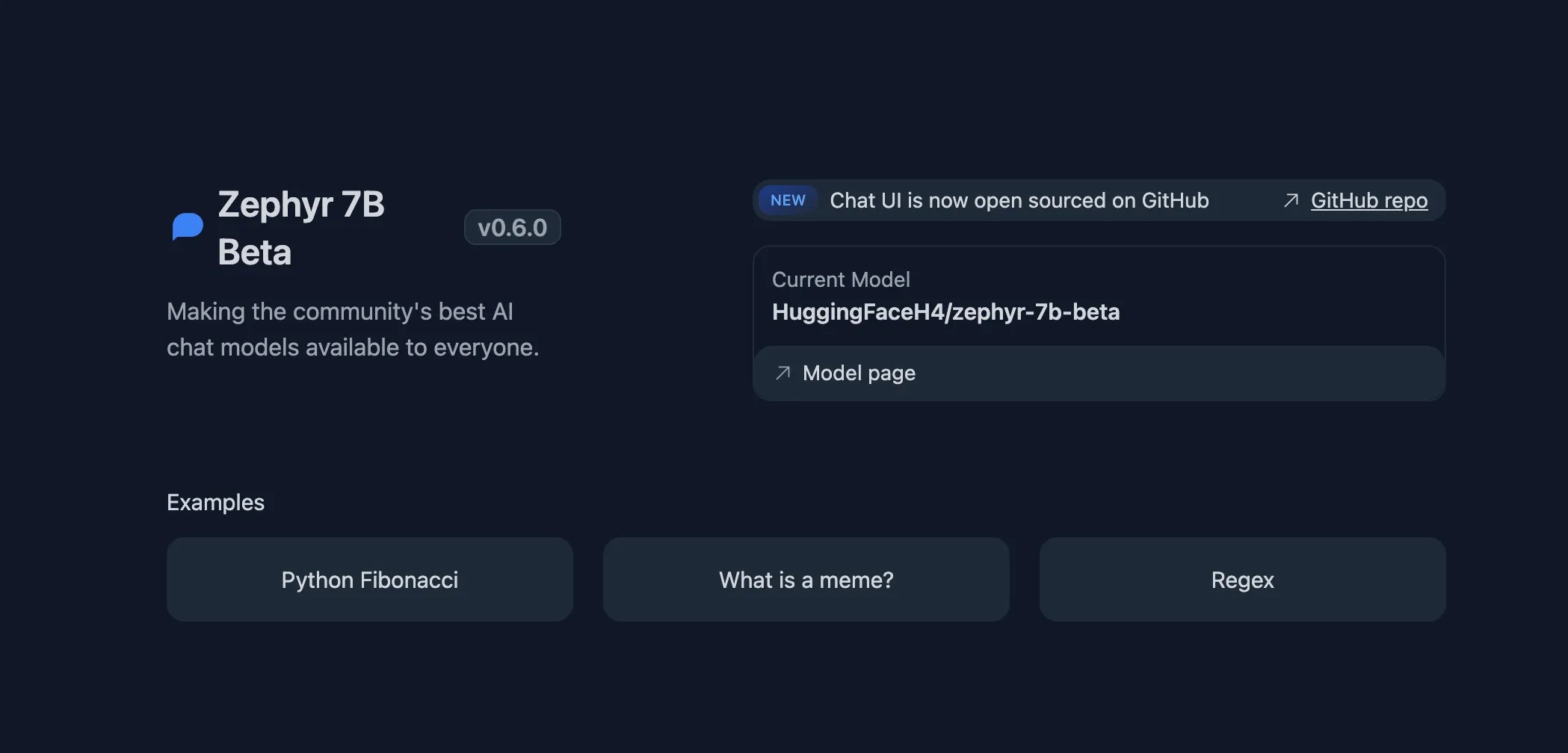
跟大家介绍一个比较简单的方法训练出的一个 7B 的模型,它在 MT Bench 测试中的表现甚至超过了 Llama2 70B 模型。
马上就试试看?https://huggingfaceh4-zephyr-chat.hf.space/
=== 方法揭秘 ===
首先,使用 UltraChat 数据集对 SFT Mistral 7B 模型进行训练。
然后,使用"直接偏好优化" (DPO) 方法,将 SFT 模型调整到 UltraFeedback 数据集上。
=== 细节揭秘 ===
对于 SFT 训练,我们使用了 UltraChat 数据集,它包含了约 1.6M个 由 GPT3.5 生成的对话。我们最初是在所有数据上进行训练的,但后来发现训练出来的模型性格有点让人讨厌。因此,我们筛选出了大约 200K 个更注重有益帮助的例子进行训练:https://hf.co.co/datasets/stingning/ultrachat
接下来,我们使用了来自 Stanford 研究者们的超棒 DPO 算法进行了另一轮微调。我们发现, DPO 比 PPO 稳定得多——强烈推荐去看他们的论文,了解更多信息!https://hf.co/papers/2305.18290
在使用 DPO 的过程中,我们选用了 UltraFeedback 数据集,它包含了 64K 个提示和完整的回答,涵盖了各种开放和封闭访问模型的范围。每个回答都由 GPT-4 根据有益性等标准进行了评分,以此来推导 AI 的偏好:https://hf.co/datasets/openbmb/UltraFeedback
在训练方面,我们在所有实验中都使用了 TRL 和 DeepSpeed ZeRO-3:
- SFTTrainer https://hf.co/docs/trl/sft_trainer
- DPOTrainer: https://hf.co/docs/trl/dpo_trainer
总计算成本:$500 或在16 x A100 上运行 8 小时
为了评估,我们使用了 LMSYS 提供的优秀工具 MT Bench。这个多轮的基准测试可以评估聊天机器人在创意写作、编码和数学等各个领域的能力。相比其他排行榜,它能提供更准确的关于聊天机器人性能的信息:https://hf.co/spaces/lmsys/mt-bench
这个教程其实是我们在 Hugging Face 工作的一部分,是 “Alignment Handbook” 手册的预告,我们在这本手册中分享了关于 SFT、DPO、PPO 等多种训练方法的稳健训练方法。我们计划不久后发布初版,你可以在这里跟踪项目的进度:https://github.com/huggingface/alignment-handbook
Hugging Face Hub 0.18.0 现已发布

0.17.0 发布的内容已经很多了,现在,0.18.0 也发布啦!0.18.0 加入了对网站上 Collection 的 API 支持,文档也有了社区支持的韩语和德语的翻译。更多详细内容,请查看此次 release note https://github.com/huggingface/huggingface_hub/releases/tag/v0.18.0
Hugging Face Hub|Follow 功能上线
Hub 刚刚更新了 Follow - 互相关注功能,可以随时关注你喜欢的 / 仰慕的 / 想一起合作的 / 社群小伙伴啦 ️(社群小伙伴 = 业界大牛)
来试试 然后告诉我们你的使用感受和建议吧
以上就是本周的 Hugging News,周末愉快!
实战|如何低成本训练一个可以超越 70B Llama2 的模型 Zephyr-7B的更多相关文章
- A TensorBoard plugin for visualizing arbitrary tensors in a video as your network trains.Beholder是一个TensorBoard插件,用于在模型训练时查看视频帧。
Beholder is a TensorBoard plugin for viewing frames of a video while your model trains. It comes wit ...
- 【PyTorch深度学习60分钟快速入门 】Part4:训练一个分类器
太棒啦!到目前为止,你已经了解了如何定义神经网络.计算损失,以及更新网络权重.不过,现在你可能会思考以下几个方面: 0x01 数据集 通常,当你需要处理图像.文本.音频或视频数据时,你可以使用标准 ...
- Fine-tuning Convolutional Neural Networks for Biomedical Image Analysis: Actively and Incrementally如何使用尽可能少的标注数据来训练一个效果有潜力的分类器
作者:AI研习社链接:https://www.zhihu.com/question/57523080/answer/236301363来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载 ...
- 深度学习笔记 (二) 在TensorFlow上训练一个多层卷积神经网络
上一篇笔记主要介绍了卷积神经网络相关的基础知识.在本篇笔记中,将参考TensorFlow官方文档使用mnist数据集,在TensorFlow上训练一个多层卷积神经网络. 下载并导入mnist数据集 首 ...
- 【Android开发VR实战】三.开发一个寻宝类VR游戏TreasureHunt
转载请注明出处:http://blog.csdn.net/linglongxin24/article/details/53939303 本文出自[DylanAndroid的博客] [Android开发 ...
- Keras 训练一个单层全连接网络的线性回归模型
1.准备环境,探索数据 import numpy as np from keras.models import Sequential from keras.layers import Dense im ...
- 案例实战之如何写一个webpack plugin
案例实战之如何写一个webpack plugin 1.写一个生成打包文件目录的file.md文件 // 生成一个目录项目目录的文件夹 class FileListPlugin { constructo ...
- PyTorch Tutorials 4 训练一个分类器
%matplotlib inline 训练一个分类器 上一讲中已经看到如何去定义一个神经网络,计算损失值和更新网络的权重. 你现在可能在想下一步. 关于数据? 一般情况下处理图像.文本.音频和视频数据 ...
- 如何正确训练一个 SVM + HOG 行人检测器
这几个月一直在忙着做大论文,一个基于 SVM 的新的目标检测算法.为了做性能对比,我必须训练一个经典的 Dalal05 提出的行人检测器,我原以为这个任务很简单,但是我错了. 为了训练出一个性能达标的 ...
- 我把阿里、腾讯、字节跳动、美团等Android性能优化实战整合成了一个PDF文档
安卓开发大军浩浩荡荡,经过近十年的发展,Android技术优化日异月新,如今Android 11.0 已经发布,Android系统性能也已经非常流畅,可以在体验上完全媲美iOS. 但是,到了各大厂商手 ...
随机推荐
- 《Among Us》火爆全球,实时语音助力派对游戏开启第二春
今年在全球"宅经济"的影响下,社交派对类游戏意外的迎来了爆发. 8月份,<糖豆人:终极淘汰赛>突然爆火,创造了首日150万玩家.首周Steam 200万销量.单周Twi ...
- 解读 --- yield 关键字
引言 yield关键字是 C# 中的一种语言特性,用于在枚举器中简化迭代器的实现.它使得开发人员可以通过定义自己的迭代器来简化代码,而不必手动实现 IEnumerable 和 IEnumerator ...
- 2023ccpc大学生程序设计竞赛-zzh
比赛开始没有开到签到题,看了一会别的题才开始跟榜.A题我写的,不过没有考虑到S长度为1的情况,wa了一次.然后lhy和zx把F题做了出来.接着他俩去看H,我去看B.他俩把H过了,B我想出了一个n*根n ...
- Android 妙用TextView实现左边文字,右边图片
原文: Android 妙用TextView实现左边文字,右边图片 - Stars-One的杂货小窝 有时候,需要文字在左边,右边有个箭头,我个人之前会有两种做法: 使用线性布局来实现 或者使用约束布 ...
- windows CMD命令的一些使用方法及注意事项
windows CMD命令的一些使用方法及注意事项 转载请著名出处:https://www.cnblogs.com/funnyzpc/p/17572397.html 一.执行路径或参数带中文.空格.特 ...
- Linux 脚本:shell
# 以脚本所在目录作为脚本执行时的当前路径. -P 选项寻找物理上的地址,忽略软连接. SCRIPT_DIR=$(cd $(dirname $0); pwd -P) # 在任意位置执行自己的可执行程序 ...
- Angular 报错 Cannot Resolve Module
file:///E:/C#/angular-client/src/app/app.component.sass?FngResource 一些文件解释不到,最后发现是这个目录的问题,里面有个特殊的字符 ...
- go语言全景俯瞰
本篇是语言教学的"传统项目".每个写go语言教学的人,都会介绍它的发展历程,应用领域,优缺点和特点来介绍自己的理由.当然如果你有自己的理解,那就更好了,欢迎讨论! 全景简介 go语 ...
- pycharm链接mysql报错: Server returns invalid timezone. Go to 'Advanced' tab and set 'serverTimezone' property manually.
检查驱动 我本机安装的mysql版本是5.6的,那么IDEA要连接mysql也应该匹配下驱动版本.把Driver改成MySQL for 5.1就可以了. 参考链接:https://blog.csdn. ...
- 【pandas小技巧】--拆分列
拆分列是pandas中常用的一种数据操作,它可以将一个包含多个值的列按照指定的规则拆分成多个新列,方便进行后续的分析和处理.拆分列的使用场景比较广泛,以下是一些常见的应用场景: 处理日期数据:在日期数 ...