Flink源码学习笔记(2) 基于Yarn的自动伸缩容实现

1.背景介绍
随着实时计算技术在之家内部的逐步推广,Flink 任务数及计算量都在持续增长,集群规模的也在逐步增大,本着降本提效的理念,我们研发了 Flink 任务伸缩容功能:
提供自动伸缩容功能,可自动调节 Flink 任务占用的资源,让计算资源分配趋于合理化。一方面避免用户为任务配置过多资源,造成资源浪费;另一方面,降低用户在调节资源方面的运维成本。
提供手动伸缩容功能,降低调节资源过程对业务的影响。伸缩容操作本质是先申请资源,待资源准备就绪后,才执行 Recover 操作,和重启任务相比,可以将业务受影响的时间从分钟级降低到秒级。
目前支持自动调节并行度以及 TaskManager 的 CPU、内存,用户可以在平台上定义个性化的自动伸缩容的策略:

2.设计思路
以伸缩容 CPU/内存为例,大致思路如下:
步骤一:向 ResourceManager 申请 Container ,并为新 Contianer 打标记
注意:新的 TaskManager Container 请求是通过 SlotPool 向 ResourceManager 请求的,这一步需要在 SlotPool 中维护新的资源配置(CPU:2核,内存:2 GB),且需要支持回滚机制(如果这次伸缩容失败资源设置回滚到 CPU:1核,内存:1 GB)

步骤二: 停掉任务,删除ExecutionGraph
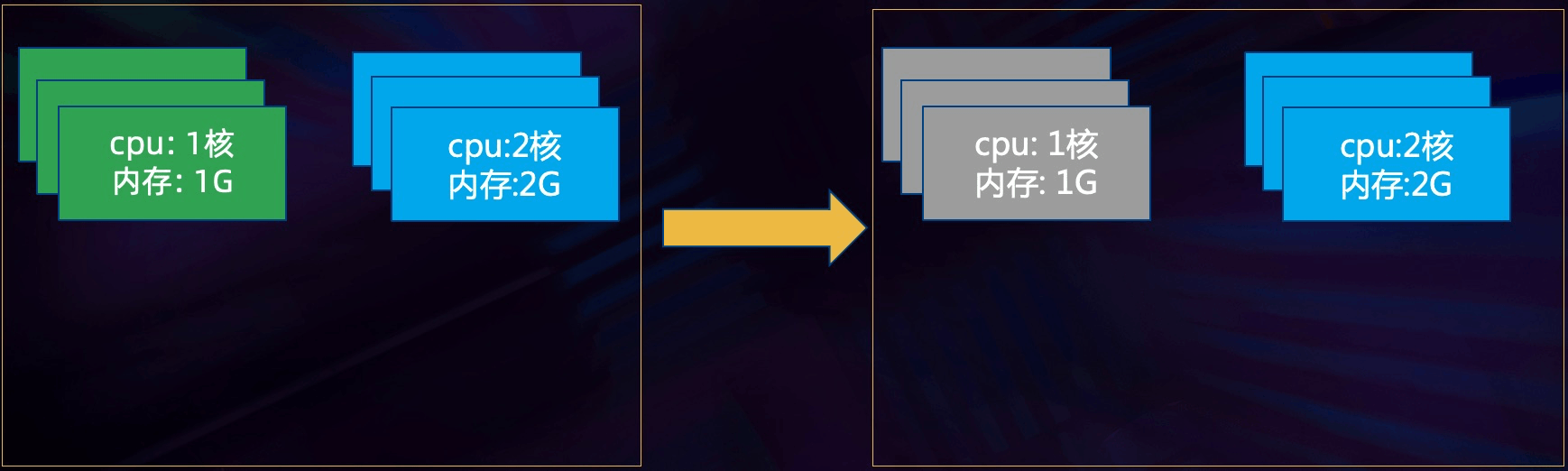
步骤三: 释放掉旧TaskManager,重新构建ExecutionGraph并在标记的TaskManager上从保存点恢复

步骤四:将这次伸缩容的资源设置持久化到Zookeeper和HDFS
如果 JobManager 挂掉那么之前伸缩容的资源配置都会丢失。所以需要将伸缩容后的资源配置保存在 Zookeeper,HDFS 上 (数据存在 Flink 基于 HDFS 的 BlobServer 中,在 Zookeeper 会中保存 BlobServer 的key,节点在HA的根目录),在 JobManager 被重新拉起时可以从最近一次伸缩容请求恢复。

3.架构设计
我们在 JobManager 中添加了一个新的组件 RescaleCoordinator ,使用HA维护其生命周期,且与 Dispatcher 之间彼此通过 RPC通信。
RescaleCoordinator 选上 leader 后,会定期检查是否需要伸缩容。如果需要伸缩容,则向 Dispatcher 通知 JobMaster 开始伸缩容(这里省略掉 JobManagerRunner);
JobMaster 会向 ResourceManager 请求 TaskManager(这里省略掉 SlotPool 和 SlotManager);
待所有请求的 TaskManager 就绪,开始将旧的 TaskManager 释放掉,然后基于新的TaskManager重新调度;
最终把这次结果持久化到 Zookeeper 和 HDFS,像上文提到的存到 Zookeeper 和 Flink 基于HDFS的 BlobServer,平台上的 Flink 使用 Zookeeper 和 HDFS 做 HA,所以不会引入其他组件;

因为新 Container 是提前申请好的,这样就省去了申请 Container 的时间,同时也避免了因为资源不够申请不到slot的问题。
并行度的伸缩容 与CPU/内存类似,不同点:需要在发起新调度前修改JobGraph的并行度来实现修改并行度
4.自动伸缩容策略
| 类型 | 原因 |
|---|---|
| 并行度 | 存在消费 Kafka 延迟,且 CPU 使用率较低,很可能是 IO 密集型任务,可以增加并行度扩容;存在空闲 slot,则执行缩容避免资源浪费 |
| CPU | 根据 CPU 使用率来判定需要扩容或缩容 |
| 内存 | 根据内存使用率及 GC 情况判定需要扩容或缩容 |
5. 后续规划
1.利用离线/实时错峰特点提高服务器资源利用率
由于离线任务一般跑在半夜,导致离线集群半夜比较繁忙,白天空闲,而实时任务恰好相反。我们准备支持基于时间的策略,白天在指定时间将任务资源调高,晚上再将资源还给离线任务,以提高服务器资源利用率。
2.细粒度的扩缩容
我们目前伸缩容都是调节所有 TaskManager 的 CPU/内存,后续想调研下只调节某几个 TaskManager 的可行性。
Flink源码学习笔记(2) 基于Yarn的自动伸缩容实现的更多相关文章
- Flink源码学习笔记(3)了解Flink HA功能的实现
使用Flink HA功能维护JobManager中组件的生命周期,可以有效的避免因为JobManager 进程失败导致任务无法恢复的情况. 接下来分享下 Flink HA功能的实现 大纲 基于Zook ...
- Spring源码学习笔记之基于ClassPathXmlApplicationContext进行bean标签解析
bean 标签在spring的配置文件中, 是非常重要的一个标签, 即便现在boot项目比较流行, 但是还是有必要理解bean标签的解析流程,有助于我们进行 基于注解配置, 也知道各个标签的作用,以及 ...
- Hadoop源码学习笔记(4) ——Socket到RPC调用
Hadoop源码学习笔记(4) ——Socket到RPC调用 Hadoop是一个分布式程序,分布在多台机器上运行,事必会涉及到网络编程.那这里如何让网络编程变得简单.透明的呢? 网络编程中,首先我们要 ...
- RocketMQ 源码学习笔记————Producer 是怎么将消息发送至 Broker 的?
目录 RocketMQ 源码学习笔记----Producer 是怎么将消息发送至 Broker 的? 前言 项目结构 rocketmq-client 模块 DefaultMQProducerTest ...
- RocketMQ 源码学习笔记 Producer 是怎么将消息发送至 Broker 的?
目录 RocketMQ 源码学习笔记 Producer 是怎么将消息发送至 Broker 的? 前言 项目结构 rocketmq-client 模块 DefaultMQProducerTest Roc ...
- JUC源码学习笔记2——AQS共享和Semaphore,CountDownLatch
本文主要讲述AQS的共享模式,共享和独占具有类似的套路,所以如果你不清楚AQS的独占的话,可以看我的<JUC源码学习笔记1> 主要参考内容有<Java并发编程的艺术>,< ...
- Spring源码学习笔记9——构造器注入及其循环依赖
Spring源码学习笔记9--构造器注入及其循环依赖 一丶前言 前面我们分析了spring基于字段的和基于set方法注入的原理,但是没有分析第二常用的注入方式(构造器注入)(第一常用字段注入),并且在 ...
- JUC源码学习笔记4——原子类,CAS,Volatile内存屏障,缓存伪共享与UnSafe相关方法
JUC源码学习笔记4--原子类,CAS,Volatile内存屏障,缓存伪共享与UnSafe相关方法 volatile的原理和内存屏障参考<Java并发编程的艺术> 原子类源码基于JDK8 ...
- JUC源码学习笔记5——线程池,FutureTask,Executor框架源码解析
JUC源码学习笔记5--线程池,FutureTask,Executor框架源码解析 源码基于JDK8 参考了美团技术博客 https://tech.meituan.com/2020/04/02/jav ...
随机推荐
- 【LeetCode】923. 3Sum With Multiplicity 解题报告(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 题目地址: https://leetcode.com/problems/3sum-wit ...
- 【LeetCode】870. Advantage Shuffle 解题报告(Python)
[LeetCode]870. Advantage Shuffle 解题报告(Python) 作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn ...
- 【LeetCode】386. Lexicographical Numbers 解题报告(Python)
[LeetCode]386. Lexicographical Numbers 解题报告(Python) 标签(空格分隔): LeetCode 作者: 负雪明烛 id: fuxuemingzhu 个人博 ...
- Docker 与 K8S学习笔记(三)—— 镜像的使用
前面的文章介绍过镜像的三种获取方式: 下载并使用别人创建好的镜像: 在现有镜像上创建新的镜像: 从无到有创建镜像. 本文主要介绍前两种. 一.下载镜像 在Docker Hub上有大量优质镜像可以使用, ...
- 一、SQL高级语句
摘抄别的博主的博客主要总去CSDN看不太方便自己整理一下加深记忆! 导入文件至数据库 #将脚本导入 source 加文件路径 mysql> source /backup/test.sql; se ...
- ROS机器人导航一 : 从英雄联盟到ROS导航
写在前面: 这是这个系列的第一篇 本系列主要从零开始深入探索ROS(机器人操作系统)的导航和规划. 这个系列的目标,是让大家了解: 1.ROS的导航是怎么实现的 2.认识ROS里各种已有的导航算法,清 ...
- node.js安装及环境配置超详细教程【Windows系统安装包方式】
文章目录 Step1:下载安装包 Step2:安装程序 Step3:查看 Step4:环境配置 最后补充: Step1:下载安装包 https://nodejs.org/zh-cn/download/ ...
- 编写Java程序,使用JTable表格组件展现人员信息列表
返回本章节 返回作业目录 需求说明: 使用JTable组件显现人员信息列表 实现思路: 创建一个JTable对象. 创建一个JScrollPane对象(显示横向和纵向滚动条). 将表格添加到滚动面板. ...
- SpringBoot+神通数据库+JPA
先上原文 https://blog.csdn.net/Helloworld_pang/article/details/114266130 一.SpringBoot + 神通数据库 基本上按照上面的参考 ...
- 【ASP.NET Core】Blazor+MiniAPI完成文件下载
今天老周要说的内容比较简单,所以大伙伴们不必紧张,能识字的都能学会. 在开始之前先来一段废话. 许多人都很关心,blazor 用起来如何?其实也没什么,做Web的无非就是后台代码+前台HTML(包含J ...