Table.Skip删除前面N….Skip/RemoveFirstN(Power Query 之 M 语言)
数据源:
“姓名”“基数”“个人比例”“个人缴纳”“公司比例”“公司缴纳”“总计”,共7列5行数据
目标:
删除掉前面三行(只留下后面两行数据)
操作过程:
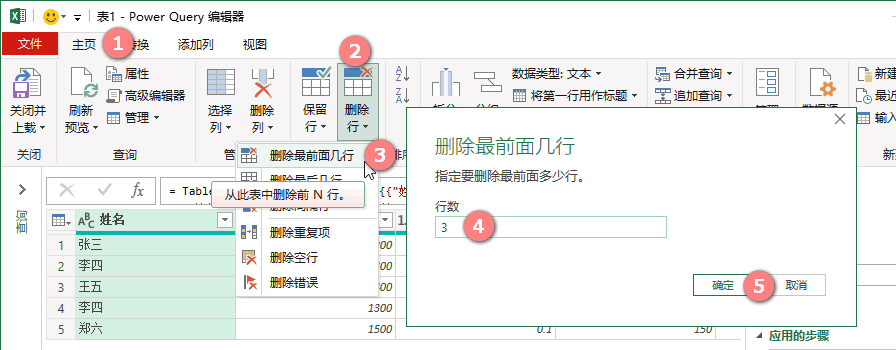
【主页】》【删除行】》【删除最前面几行】》输入删除的行数》【确定】
M公式:
删除行:= Table.Skip( 表, 删除的行数或条件)
说明:
第二参数缺省时默认为1
最终效果:
数据只剩下后两行
多说一句:
Table.FirstN/Table.RemoveLastN/ Table.LastN/Table.Skip这4个M函数的作用,就在于按固定行数删除一个数据表前面或后面的行,参数都非常简单,只有两个,步骤名和待删除或保留的行数(或条件)。
这4个M函数的现实意义非常大,因为我们的制表习惯,一个数据表的标题行(表头)往往不在整个数据表的第一行,数据表的后面又会加一些固定的内容,如下图。

其实,这种结构在做多工作表/簿合并的时候,这些多出来的表头和表尾都会给操作带来麻烦,这时候就需要借助于M公式,先将数据表中不需要的行去除,再进行合并。这一操作除了涉及到以上M函数以外,还会涉及到函数嵌套。关于具体的应用,后续会有相关文章说明。
扩展:
表中删除前N行:=Table.RemoveFirstN( 表, 删除的行数或条件)
用法、效果与Table.Skip相同,Skip意为“跳过”,Remove才是正经“删除”
列表中删除前N项:= List.Skip( 列表, 删除的项数或条件)
第二参数缺省时默认为1
示例:=List.Skip({1..10}, 7)
结果:保留列表中的后3项,即{8,9,10}
列表中删除前N项:= List.RemoveFirstN( 列表, 删除的项数或条件)
第二参数缺省时默认为1
示例:=List.RemoveFirstN({1..10}, 3)
结果:删除列表中的前3项,即{4,5,6,7,8,9,10}
Table.Skip删除前面N….Skip/RemoveFirstN(Power Query 之 M 语言)的更多相关文章
- Table.RemoveLastN删除后面N….RemoveLastN(Power Query 之 M 语言)
数据源: "姓名""基数""个人比例""个人缴纳""公司比例""公司缴纳"&qu ...
- Table.FirstN保留前面N….First…(Power Query 之 M 语言)
数据源: "姓名""基数""个人比例""个人缴纳""公司比例""公司缴纳"&qu ...
- Table.LastN保留后面N….Last…(Power Query 之 M 语言)
数据源: "姓名""基数""个人比例""个人缴纳""公司比例""公司缴纳"&qu ...
- 删除…Remove…(Power Query 之 M 语言)
删除行(表): 删除指定行:=Table.RemoveRows( 表, 起始行数, 删除的行数) 起始行数从0开始计 删除前面N-.Skip/RemoveFirstN 删除后面N-.RemoveLas ...
- M函数目录(Power Query 之 M 语言)
2021-12-11更新 主页(选项卡) 管理列(组) 选择列 选择列Table.SelectColumns 删除列 删除列Table.RemoveColumns 删除其他列Table.SelectC ...
- Excel.CurrentWorkbook数据源(Power Query 之 M 语言)
数据源: 任意超级表 目标: 将超级表中的数据加载到Power Query编辑器中 操作过程: 选取超级表中任意单元格(选取普通表时会自动增加插入超级表的步骤)>数据>来自表格/区域 M公 ...
- M语言的写、改、删(Power Query 之 M 语言)
M语言基本上和其他语言一样,用敲键盘的方式写入.修改.删除,这个是废话. M语言可以在[编辑栏]或[高级编辑器]里直接写入.修改.删除,这个也是废话. M语言还有个地方可以写入.修改.删除,就是[自定 ...
- 自定义函数(Power Query 之 M 语言)
数据源: 任意工作簿 目标: 使用自定义函数实现将数据源导入Power Query编辑器 操作过程: PowerQuery编辑器>主页>新建源>其他源>空查询 编辑栏内写入公式 ...
- M语言的藏身之地(Power Query 之 M 语言)
M函数和M公式是Power Query专用的函数与公式,M代码是Power Query专用的用于实现查询功能的代码.M函数公式和M代码统称M语言. 查看M公式:[编辑栏] 查看方法:在Power Qu ...
随机推荐
- [loj2863]组合动作
先用两次猜出第一个字符,后面就不会出现这个字符了 (我们假设这个字符是c0,其余三种字符分别是c1.c2和c3) ,然后考虑已知s的前i个字符(不妨就s),来推出后面的字符 询问:s+c1和s+c2, ...
- [bzoj1391]order
考虑最小割,即最少要去掉多少收益先S向所有机器连边,流量为购买费用:所有机器向工作连边,流量为租借费用:工作向T连边,流量为收益那么对于每一个工作,要么割掉连向T的边,要么购买/租借所有机器,同时由于 ...
- Java-ASM框架学习-修改类的字节码
Tips: ASM使用访问者模式,学会访问者模式再看ASM更加清晰 ClassReader 用于读取字节码,父类是Object 主要作用: 分析字节码里各部分内容,如版本.字段等等 配合其他Visit ...
- 【机器学习基础】卷积神经网络(CNN)基础
最近几天陆续补充了一些"线性回归"部分内容,这节继续机器学习基础部分,这节主要对CNN的基础进行整理,仅限于基础原理的了解,更复杂的内容和实践放在以后再进行总结. 卷积神经网络的基 ...
- 『与善仁』Appium基础 — 10、Appium基本原理
目录 1.Appium自动化测试架构 2.Appium架构图 3.Session说明 4.Desired Capabilities说明 5.Appium Server说明 6.Appium Clien ...
- BehaviorTree.CPP行为树BT的入门(二)
节点与树 用户必须创建自己的ActionNodes和ConditionNodes(LeafNodes):该库可帮助您轻松地将它们组成树. 将LeafNodes视为组成复杂系统所需的构建块. 根据定义, ...
- 统计学习1:朴素贝叶斯模型(Numpy实现)
模型 生成模型介绍 我们定义样本空间为\(\mathcal{X} \subseteq \mathbb{R}^n\),输出空间为\(\mathcal{Y} = \{c_1, c_2, ..., c_K\ ...
- admixture 群体结构分析
tructure是与PCA.进化树相似的方法,就是利用分子标记的基因型信息对一组样本进行分类,分子标记可以是SNP.indel.SSR.相比于PCA,进化树,群体结构分析可明确各个群之间是否存在交流及 ...
- 【GS模型】使用R包sommer进行基因组选择的GBLUP和RRBLUP分析?
目录 简介 GS示例代码 简介 R包sommer内置了C++,运算速度还是比较快的,功能也很丰富,可求解各种复杂模型.语法相比于lme4包也要好懂一些. 建议查看文档:vignette("v ...
- Python基础笔记4
模块 模块是一组Python代码的集合,一个.py文件就称之为一个模块(Module),按目录来组织模块称为包(Package).优点:提高了代码的可维护性:避免函数名和变量名冲突. mycompan ...