Python练习1-文档格式化成html
文档格式化成HTML
把文档格式化成了THML,并没有处理所有thml规则,只是处理了一部分,功能不重要,重要的是复习熟悉下Python对文档的处理细节。毕竟Python大多数给我的印象都是处理文档。代码里有很多逻辑可能不严谨,这里再次强调只是为了复习字符串以及文档操作。
同时提醒一下,如果运行失败,请删除注释,我是用vs2015编写的,返现当时中文注释导致编码错误运行失败。一共四个文档:

入口文档是markup.py。
参数 python markup.py < xxx.txt > xxx.html
执行效果和代码如下:
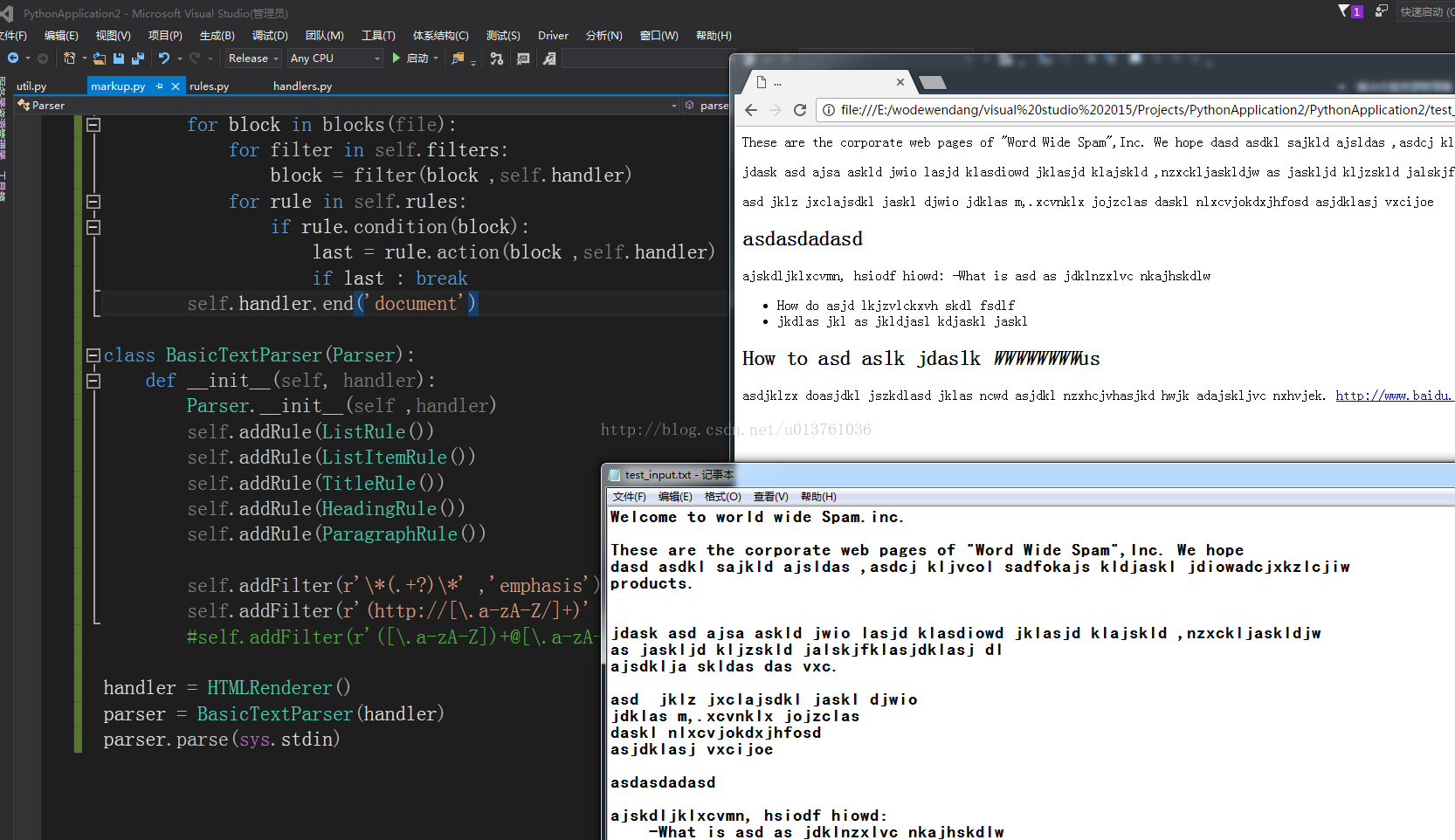
Util.py
def lines(file):
for line in file:yield line
yield '\n'
def blocks(file):
block = []
for line in lines(file):
if line.strip(): #'\n','\r','\t',' '
block.append(line);
elif block:
yield ''.join(block).strip()
block = []
Handlers.py
class Handler:
"""
处理从Parser调用的方法的对象。
这个解析器会在每个块的开始部分调用start()和end()方法,使用合适的
块名作为参数,sub()方法会用于正则表达式替换中。当使用了'emphasis'
这样的名字调用时,它会返回合适的替换函数。
"""
def callback(self ,prefix ,name ,*args):
method = getattr(self ,prefix + name ,None)
if callable(method) : return method(*agrs)
def start(self ,name):
self.callback('start_',name);
def end(self ,name):
self.callback('end_',name);
def sub(self ,name):
def substitution(match):
result = self.callback('sub_' ,name ,match)
if result is None: match.group(0)
return result
return substitution
class HTMLRenderer(Handler):
"""
用于生成HTML的具体处理程序
THMLRenderer内容的方法都是可以通过超类处理程序的start()、
end()和sub()方法来访问。他们实现了用于HTRML文档的基本标签。
"""
def start_document(self):
print('<html><head><title>...</title></head><body>')
def end_document(self):
print('</body></html>')
def start_paragraph(self):
print('<p>')
def end_paragraph(self):
print('</p>')
def start_heading(self):
print('<h2>')
def end_heading(self):
print('</h2>')
def start_list(self):
print('<ul>')
def end_list(self):
print('</ul>')
def start_listitem(self):
print('<li>')
def end_listitem(self):
print('</li>')
def start_title(self):
print('<title>')
def end_title(self):
print('</title>')
def sub_emphasis(self ,match):
return ('<em>%s</em>' % match.group(1))
def sub_url(self ,match):
return ('<a href = "%s">%s</a>' % (match.group(1),match.group(1)))
def sub_mail(self ,match):
return ('<a href="mailto:%s">%s</a>' % (match.group(1),match.group(1)))
def feed(self ,data):
print(data)
Rules.py
class Rule:
"""
所有规则的基类。
"""
def action(self ,block ,handler):
handler.start(self.type)
handler.feed(block)
handler.end(self.type)
return True
class HeadingRule(Rule):
"""
标题占一行,最多70个字符,并且不以冒号结尾。
"""
type = 'heading'
def condition(self ,block):
return not '\n' in block and len(block) <= 70 and not block[-1] == ':'
class TitleRule(HeadingRule):
"""
题目是文档的第一个块,但前提它是大标题。
"""
type = 'title'
first = True
def condition(self, block):
if not self.first:return False
self.first = HeadingRule.condition(self ,block)
class ListItemRule(Rule):
"""
列表项是以连字符开始的段落。作为格式化的一部分,要移除连字符。
"""
type = 'listitem'
def condition(self ,block):
return block[0] == '-'
def action(self, block, handler):
handler.start(self.type)
handler.feed(block[1:].strip())
handler.end(self.type)
return True
class ListRule(ListItemRule):
"""
列表从不是列表项的块和岁以后的列表项之间。在最后一个连续的列表项之后结束。
"""
type = 'list'
inside = False
def condition(self ,block):
return True
def action(self, block, handler):
if not self.inside and ListItemRule.condition(self ,block):
handler.start(self.type)
self.inside = True
elif self.inside and not ListItemRule.condition(self ,block):
handler.end(self.type)
self.inside = False
return False
class ParagraphRule(Rule):
"""
段落只是其他规则并没有覆盖到的块
"""
type = 'paragraph'
def condition(self ,block):
return TrueMarkup.py
import sys,re
from handlers import *
from util import *
from rules import *
class Parser:
#"""
#语法分析器读取文本文件、应用规则并且控制处理程序
# """
def __init__(self ,handler):
self.handler = handler
self.rules = []
self.filters = []
def addRule(self ,rule):
self.rules.append(rule)
def addFilter(self ,pattern ,name):
def filter(bolck ,handler):
return re.sub(pattern ,handler.sub(name),bolck)
self.filters.append(filter)
def parse(self ,file):
self.handler.start('document')
for block in blocks(file):
for filter in self.filters:
block = filter(block ,self.handler)
for rule in self.rules:
if rule.condition(block):
last = rule.action(block ,self.handler)
if last : break
self.handler.end('document')
class BasicTextParser(Parser):
"""
在构造函数中添加规则和过滤器的具体语法分析器
"""
def __init__(self, handler):
Parser.__init__(self ,handler)
self.addRule(ListRule)
self.addRule(ListItemRule)
self.addRule(TitleRule)
self.addRule(HeadingRule)
self.addRule(ParagraphRule)
self.addFilter(r'\*(.+?)\*' ,'emphasis')
self.addFilter(r'(http://[\.a-zA-Z/]+)' ,'url')
self.addFilter(r'([\.a-zA-Z])+@[\.a-zA-Z]+[a-zA-Z]+)' ,'mail')
handler = HTMLRenderer()
parser = BasicTextParser(handler)
parser.parse(sys.stdin)Python练习1-文档格式化成html的更多相关文章
- Python之word文档模板套用 - 真正的模板格式套用
Python之word文档模板套用: 1 ''' 2 #word模板套用2:套用模板 3 ''' 4 5 #导入所需库 6 from docx import Document 7 ''' 8 #另存w ...
- Python中定义文档字符串__doc__需要注意格式对齐的处理
Python中的文档字符串是个很不错的提升代码交付质量.编写文档方便的特征,但是需要注意在使用文档字符串时,将文档字符串标识的引号对必须遵守缩进的规则,否则Python语法检查时会无法通过,而引号内的 ...
- Python处理Excel文档(xlrd, xlwt, xlutils)
简介 xlrd,xlwt和xlutils是用Python处理Excel文档(*.xls)的高效率工具.其中,xlrd只能读取xls,xlwt只能新建xls(不可以修改),xlutils能将xlrd.B ...
- 【好文翻译】一步一步教你使用Spire.Doc转换Word文档格式
背景: 年11月,微软宣布作为ECMA国际主要合作伙伴,将其开发的基于XML的文件格式标准化,称之为"Office Open XML" .Open XML的引进使office文档结 ...
- python 解析docx文档的方法,以及利用Python从docx文档提取插入的文本对象和图片
首先安装docx模块,通过pip install docx或者在docx官方链接上下载安装都可以 下面来看下如何解析docx文档:文档格式如下 有3个部分组成 1 正文:text文档 2 一个表格. ...
- 【转】Python之xml文档及配置文件处理(ElementTree模块、ConfigParser模块)
[转]Python之xml文档及配置文件处理(ElementTree模块.ConfigParser模块) 本节内容 前言 XML处理模块 ConfigParser/configparser模块 总结 ...
- python操作docx文档(转)
python操作docx文档 关于python操作docx格式文档,我用到了两个python包,一个便是python-docx包,另一个便是python-docx-template;,同时我也用到了很 ...
- python实用小技能分享,教你如何使用 Python 将 pdf 文档进行 加密 解密
上次说了怎么将word转换为pdf格式 及 实现批量将word转换为pdf格式(点击这里),这次我又get到一个新技能–使用 Python 将 pdf 文档进行 加密 解密,哈哈哈 希望帮到更多人! ...
- Python中的文档字符串作用
文档字符串是使用一对三个单引号 ''' 或者一对三个双引号 """来包围且没有赋值给变量的一段文字说明(如果是单行且本身不含引号,也可以是单引号和双引号), 它在代码执行 ...
随机推荐
- 免费报表工具 积木报表(JiMuReport)的安装
分享一b/s报表工具(服务),积木报表(JiMuReport),张代浩大佬出品. 官网:http://www.jimureport.com/ 离线版官方下载:https://github.com/zh ...
- 通达OA 前台任意用户登录漏洞复现
漏洞描述 通达OA是一套办公系统.通达OA官方于4月17日发布安全更新.经分析,在该次安全更新中修复了包括任意用户登录在内的高危漏洞.攻击者通过构造恶意请求,可以直接绕过登录验证逻辑,伪装为系统管理身 ...
- 如何报告FreeBSD 的bug?
https://bugs.freebsd.org/bugzilla/ 注册个账号即可,请使用英语,把程序在不同程序上的运行结果列出来即可- 注意标记架构,如果有log还请一并附上,英语差可以 ...
- 用实战玩转pandas数据分析(一)——用户消费行为分析(python)
CD商品订单数据的分析总结.根据订单数据(用户的消费记录),从时间维度和用户维度,分析该网站用户的消费行为.通过此案例,总结订单数据的一些共性,能通过用户的消费记录挖掘出对业务有用的信息.对其他产 ...
- android 调用js,js调用android
Java调用JavaScript 1.main.xml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 <?xml v ...
- 让JS代码Level提升的忍者秘籍(实用)
本文章共2377字,预计阅读时间5-10分钟. 前言 没有前言. 你准备好成为同事眼中深藏不露.高深莫测.阳光帅气的前端开发了吗? 那就开始吧! 本文秉承宗旨:代码实用与逼格并存. 提升JS代码Lev ...
- Cable Protection
题目大意:求一颗基环树的最小点覆盖. 题解:其实是一道比较板子的树形dp,dp[i][0/1]表示取或者不取i点的最小点.但是首先我们要把基环树断开,然后分别考虑a被覆盖和b被覆盖的情况. dp[i] ...
- P1208 [USACO1.3]混合牛奶 Mixing Milk(JAVA语言)
思路 按单价排序然后贪心 题目描述 由于乳制品产业利润很低,所以降低原材料(牛奶)价格就变得十分重要.帮助Marry乳业找到最优的牛奶采购方案. Marry乳业从一些奶农手中采购牛奶,并且每一位奶农为 ...
- 搞懂 ZooKeeper 集群的数据同步
本文作者:HelloGitHub-老荀 Hi,这里是 HelloGitHub 推出的 HelloZooKeeper 系列,免费开源.有趣.入门级的 ZooKeeper 教程,面向有编程基础的新手. 项 ...
- 快速上手阿里云oss SDK
使用阿里云oss SDK 依赖安装: pip install oss2 pip install aliyun-python-sdk-sts 版本最好是 2.7.5 或以上 如果要开启 crc64 循环 ...