Redis 集群伸缩原理
Redis 节点分别维护自己负责的槽和对应的数据。伸缩原理:Redis 槽和对应数据在不同节点之间移动
一、集群扩容
1. 手动扩容
(1) 准备节点 9007,并加入集群
192.168.11.40:9001> cluster meet 192.168.11.40 9007
【注意】若 cluster meet 加入已存在于其它集群的节点,会导致集群合并,造成数据错乱!。建议使用 redis-cli 的 add-node:
# 若节点已加入其它集群或包含数据,会报错
add-node new_host:new_port existing_host:existing_port
--cluster-slave # 直接添加为从节点
--cluster-master-id <arg> # 从节点对应的主节点id
(2) 迁移槽和数据
- 槽在迁移过程中集群可以正常提供读写服务
- 首先确定原有节点的哪些槽需要迁移到新节点。确保每个节点负责相似数量的槽,保证各节点的数据均匀
- 槽是 Redis 集群管理数据的基本单位。数据迁移是逐槽进行的
槽迁移流程:
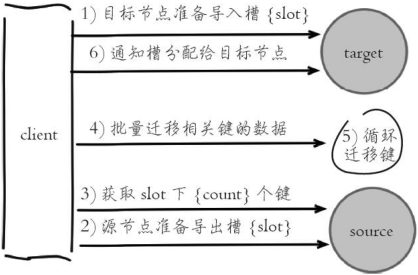
- 目标节点准备导入槽的数据:目标节点执行
cluster setslot {slot} importing {sourceNodeId} - 源节点准备迁出槽的数据:源节点执行
cluster setslot {slot} migrating {targetNodeId} - 获取 count 个属于槽 slot 的键:源节点执行
cluster getkeysinslot {slot} {count} - 迁移键:源节点执行
migrate {targetIp} {targetPort} "" 0 {timeout} keys {keys...},把键通过流水线(pipeline)机制批量迁移到目标节点。Redis3.0.6 后才支持批量迁移 - 重复上两步,直到槽下所有的键值数据迁移到目标节点
- 向集群所有主节点通知槽被分配给目标节点:集群内所有主节点执行
cluster setslot {slot} node {targetNodeId}
内部伪代码:
def move_slot(source,target,slot):
# 目标节点准备导入槽
target.cluster("setslot",slot,"importing",source.nodeId);
# 目标节点准备全出槽
source.cluster("setslot",slot,"migrating",target.nodeId);
while true :
# 批量从源节点获取键
keys = source.cluster("getkeysinslot",slot,pipeline_size);
if keys.length == 0:
# 键列表为空时,退出循环
break;
# 批量迁移键到目标节点
source.call("migrate",target.host,target.port,"",0,timeout,"keys",keys);
# 向集群所有主节点通知槽被分配给目标节点
for node in nodes:
if node.flag == "slave":
continue;
node.cluster("setslot",slot,"node",target.nodeId);
(3) 将 9001 的槽 4096 迁移到 9007 中
准备数据
192.168.11.40:9001> set key:test:5028 value:5028
192.168.11.40:9001> set key:test:68253 value:68253
目标节点准备工作
192.168.11.40:9007> cluster nodes
8ccdb0963411ebd05ce21952bdd4b7597825afdc 192.168.11.40:9001@19001 master - 0 1620928869000 2 connected 0-5461
bb1bb0f5f9e0ee67846ba8ec94a38da700e2e80d 192.168.11.40:9007@19007 myself,master - 0 1620928868000 0 connected
...
# 9007 准备导入槽 4096 的数据
192.168.11.40:9007> cluster setslot 4096 importing 8ccdb0963411ebd05ce21952bdd4b7597825afdc
OK
# 槽 4096 已开启导入状态
192.168.11.40:9007> cluster nodes
bb1bb0f5f9e0ee67846ba8ec94a38da700e2e80d 192.168.11.40:9007@19007 myself,master - 0 1620928959000 0 connected [4096-<-8ccdb0963411ebd05ce21952bdd4b7597825afdc]
...
源节点准备工作
# 9001 准备导出槽 4096 数据
192.168.11.40:9001> cluster setslot 4096 migrating bb1bb0f5f9e0ee67846ba8ec94a38da700e2e80d
OK
# 槽 4096 已开启导出状态
192.168.11.40:9001> cluster nodes
8ccdb0963411ebd05ce21952bdd4b7597825afdc 192.168.11.40:9001@19001 myself,master - 0 1620929179000 2 connected 0-5461 [4096->-bb1bb0f5f9e0ee67846ba8ec94a38da700e2e80d]
...
导出数据
# 获取 100 个属于槽 4096 的键
192.168.11.40:9001> cluster getkeysinslot 4096 100
1) "key:test:5028"
2) "key:test:68253"
# 查看数据
192.168.11.40:9001> mget key:test:5028 key:test:68253
1) "value:5028"
2) "value:68253"
# 迁移这2个键:migrate 命令保证了每个键迁移过程的原子性
192.168.11.40:9001> migrate 192.168.11.40 9007 "" 0 5000 keys key:test:5028 key:test:68253
OK
# 再次查询会报 ASK 错误:引导客户端找到数据所在的节点
192.168.11.40:9001> mget key:test:5028 key:test:68253
(error) ASK 4096 192.168.11.40:9007
通知所有主节点:槽 4096 指派给 9007
192.168.11.40:9001> cluster setslot 4096 node bb1bb0f5f9e0ee67846ba8ec94a38da700e2e80d
192.168.11.40:9002> cluster setslot 4096 node bb1bb0f5f9e0ee67846ba8ec94a38da700e2e80d
192.168.11.40:9003> cluster setslot 4096 node bb1bb0f5f9e0ee67846ba8ec94a38da700e2e80d
192.168.11.40:9007> cluster setslot 4096 node bb1bb0f5f9e0ee67846ba8ec94a38da700e2e80d
查看最终结果
192.168.11.40:9007> cluster nodes
8ccdb0963411ebd05ce21952bdd4b7597825afdc 192.168.11.40:9001@19001 master - 0 1620931743303 7 connected 0-4095 4097-5461
bb1bb0f5f9e0ee67846ba8ec94a38da700e2e80d 192.168.11.40:9007@19007 myself,master - 0 1620931741000 8 connected 4096
...
2. 使用 redis-cli 扩容
redis-cli 提供了槽重分片功能
reshard 命令参数详解:
reshard host:port # 集群内任意节点地址
--cluster-from <arg> # 源节点id,逗号分隔
--cluster-to <arg> # 目标节点id,只有一个
--cluster-slots <arg> # 迁移多少个槽
--cluster-yes # 确认执行reshard
--cluster-timeout <arg> # 每次 migrate 操作的超时时间,默认 60000ms
--cluster-pipeline <arg> # 每次批量迁移键的数量,默认 10
--cluster-replace
将 9001、9002、9003 的槽迁移到 9007,共迁移 4096 个
$ /usr/local/redis/bin/redis-cli --cluster reshard 192.168.11.40:9001
M: 8ccdb0963411ebd05ce21952bdd4b7597825afdc 192.168.11.40:9001
slots:[0-4095],[4097-5461] (5461 slots) master
1 additional replica(s)
M: bb1bb0f5f9e0ee67846ba8ec94a38da700e2e80d 192.168.11.40:9007
slots:[4096] (1 slots) master
...
[OK] All 16384 slots covered.
How many slots do you want to move (from 1 to 16384)? 4096
What is the receiving node ID? bb1bb0f5f9e0ee67846ba8ec94a38da700e2e80d
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1: 8ccdb0963411ebd05ce21952bdd4b7597825afdc
Source node #2: 5786e3237c7fa413ed22465d15be721f95e72cfa
Source node #3: 85ceb9826e8aa003169c46fb4ba115c72002d4f9
Source node #4: done
Moving slot 0 from 8ccdb0963411ebd05ce21952bdd4b7597825afdc
...
Moving slot 12287 from 85ceb9826e8aa003169c46fb4ba115c72002d4f9
Do you want to proceed with the proposed reshard plan (yes/no)? yes
Moving slot 0 from 192.168.11.40:9001 to 192.168.11.40:9007:
...
Moving slot 12287 from 192.168.11.40:9003 to 192.168.11.40:9007:
查看最终结果
192.168.11.40:9007> cluster nodes
8ccdb0963411ebd05ce21952bdd4b7597825afdc 192.168.11.40:9001@19001 master - 0 1620933907753 7 connected 1366-4095 4097-5461
5786e3237c7fa413ed22465d15be721f95e72cfa 192.168.11.40:9002@19002 master - 0 1620933906733 1 connected 6827-10922
85ceb9826e8aa003169c46fb4ba115c72002d4f9 192.168.11.40:9003@19003 master - 0 1620933905000 3 connected 12288-16383
bb1bb0f5f9e0ee67846ba8ec94a38da700e2e80d 192.168.11.40:9007@19007 myself,master - 0 1620933900000 8 connected 0-1365 4096 5462-6826 10923-12287
...
检查节点之间槽的均衡性
$ /usr/local/redis/bin/redis-cli --cluster rebalance 192.168.11.40:9001
...
[OK] All 16384 slots covered.
*** No rebalancing needed! All nodes are within the 2.00% threshold.
迁移之后所有主节点负责的槽数量差异在 2% 以内,因此集群节点数据相对均匀,无需调整
二、集群收缩
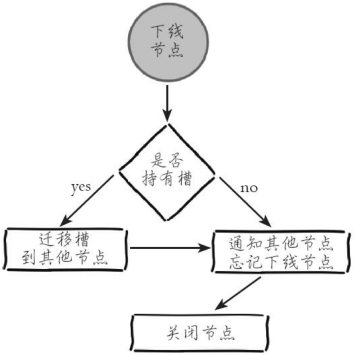
1. 迁移槽
执行 reshard 三次,将数据平均分布到其他三个节点
2. 忘记节点
60s 内对所有节点执行如下操作:(不建议)
# 执行后,会将该节点加入禁用列表(持续 60s),不再向其发送 Gossip 消息
cluster forget {nodeId}
建议使用 redis-cli 的 del-node 忘记节点:
/usr/local/redis/bin/redis-cli --cluster del-node {host:port} {nodeId}
内部伪代码
def delnode_cluster_cmd(downNode):
# 下线节点不允许包含slots
if downNode.slots.length != 0
exit 1
end
# 向集群内节点发送cluster forget
for n in nodes:
if n.id == downNode.id:
# 不能对自己做forget操作
continue;
# 如果下线节点有从节点则把从节点指向其他主节点
if n.replicate && n.replicate.nodeId == downNode.id :
# 指向拥有最少从节点的主节点
master = get_master_with_least_replicas();
n.cluster("replicate",master.nodeId);
#发送忘记节点命令
n.cluster('forget',downNode.id)
# 节点关闭
downNode.shutdown();
若主从节点都要下线,先下线从,避免全量复制
Redis 集群伸缩原理的更多相关文章
- Redis集群的原理和搭建(转载)
转载来源:https://www.jianshu.com/p/c869feb5581d Redis集群的原理和搭建 前言 Redis 是我们目前大规模使用的缓存中间件,由于它强大高效而又便捷的功能,得 ...
- redis集群伸缩【转】
一:实验介绍 在不影响集群对外服务的情况下,可以为集群添加节点进行扩容,也可以下线部分节点进行缩容. 原理可以抽象为槽和对应数据在不同节点之间灵活移动. 如果希望加入一个节点来实现集群扩容时,需要通过 ...
- 三张图秒懂Redis集群设计原理
转载Redis Cluster原理 转载https://blog.csdn.net/yejingtao703/article/details/78484151 redis集群部署方式: 单机 主从 r ...
- Redis集群设计原理
---恢复内容开始--- Redis集群设计包括2部分:哈希Slot和节点主从,本篇博文通过3张图来搞明白Redis的集群设计. 节点主从: 主从设计不算什么新鲜玩意,在数据库中我们也经常用主从来做读 ...
- 【集群】Redis集群设计原理
Redis集群设计包括2部分:哈希Slot和节点主从 节点主从: 主从设计不算什么新鲜玩意,在数据库中我们也经常用主从来做读写分离,直接上图: 图上能看得到的信息: 1, 只有1个Master,可以有 ...
- Redis学习总结(六)--Redis集群伸缩
我们在上一章讲了如何创建集群,今天我们来实现下集群的伸缩. 添加节点 操作流程 1.启动节点 2.将节点加入到集群中 3.将数据槽从原来的节点迁移部分到新节点上 实践 1)准备两个新节点并启动 [ro ...
- Redis集群伸缩
集群扩容 前提准备,目前集群中一共有6台机器,端口号分别是6381.6382.6383.6384.6385.6386 1) 准备新节点 准备两个新节点,端口号为6387和6388,配置和以前集群配置一 ...
- 分布式缓存技术redis学习系列(四)——redis高级应用(集群搭建、集群分区原理、集群操作)
本文是redis学习系列的第四篇,前面我们学习了redis的数据结构和一些高级特性,点击下面链接可回看 <详细讲解redis数据结构(内存模型)以及常用命令> <redis高级应用( ...
- 分布式缓存技术redis学习(四)——redis高级应用(集群搭建、集群分区原理、集群操作)
本文是redis学习系列的第四篇,前面我们学习了redis的数据结构和一些高级特性,点击下面链接可回看 <详细讲解redis数据结构(内存模型)以及常用命令> <redis高级应用( ...
随机推荐
- 11、pass,is,位运算的补充
pass的补充 一般Python的代码是基于:和缩进来实现,Python中规定代码块中必须要有代码才算完整,在没有代码的情况下为了保证语法的完整性可以用pass代替 if 条件: pass else: ...
- 一个名叫Sentinel-Rules-SDK的组件,使得Sentinel的流控&熔断规则的配置更加方便
原文链接:一个名叫Sentinel-Rules-SDK的组件,使得Sentinel的流控&熔断规则的配置更加方便 1 Sentinel 是什么? 随着微服务的流行,服务和服务之间的稳定性变得越 ...
- C语言之漫谈指针(上)
C语言之漫谈指针(上) 在C语言学习的途中,我们永远有一个绕不了的坑,那就是--指针. 在这篇文章中我们就谈一谈指针的一些基础知识. 纲要: 零.谈指针之前的小知识 一.指针与指针变量 二.指针变量的 ...
- python爬取三国演义的所有章节储存到本地文件中
#爬取三国演义的全部章节 2 3 import urllib 4 import urllib.request 5 import urllib.parse 6 from lxml import etre ...
- P1604_B进制星球(JAVA语言)
思路:BigInteger 五杀!利用BigInteger自带的进制转换. //第一次提交WA了几组数据,下载测试数据发现带字母的答案要转换为大写. 题目背景 进制题目,而且还是个计算器~~ 题目描述 ...
- 创建Maven父子项目以及它们的优点
此文引用:https://blog.csdn.net/zxl8876/article/details/104180133 创建maven父子项目 第一步创建父项目: 新建一个普通的maven项目 删除 ...
- OpenGL 绘制你的 github skyline 模型
前言 好久没更新博客了,上一篇文章还是在去年6月份,乍一看居然快要过去一年了,不时还能看到粉丝数和排名在涨,可是却一直没有内容更新,怪不好意思的- -(主要是一直没想好要写些什么,中间也有过一些想法, ...
- UML第二部分和创建型模式
状态机视图通过对每个类的对象的生命期进行建模 描述了对象时间上的动态行为 .状态指就某个特定类而言 对于发生的事件具有相同性质响应的一系列对象值.状态机不但可以描述类的行为 而且可以描述用例 协作和方 ...
- 利用Navicat premium实现将数据从Oracle导入到MySQL
背景:我们给用户提供了新的直播系统,但客户之前的老系统用的数据库是Oracle,我们提供的新系统用的是MySQL 客户诉求:将老系统中的所有直播数据导入到MySQL中: 思路:我知道Navicat有数 ...
- C# .NET Socket 简单实用框架,socket组件封装
参考资料 https://www.cnblogs.com/coldairarrow/p/7501645.html 根据.NET Socket 简单实用框架进行了改造,这个代码对socket通信封装还是 ...