docker搭建mysql集群
一、集群方案
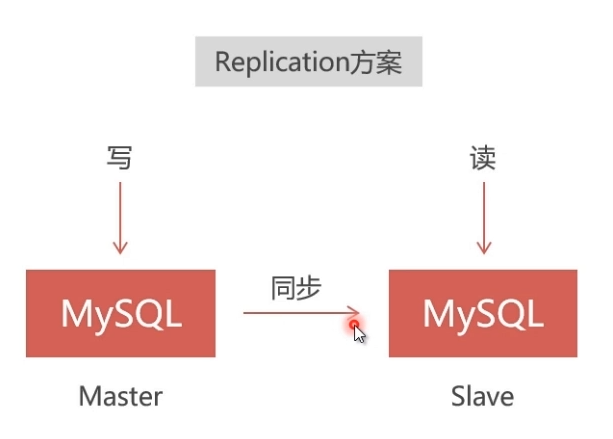
1、Replication
- 速度快,但仅能保证弱一致性,适用于保存价值不高的数据,比如日志、帖子、新闻等。
- 采用master-slave结构,在master写入会同步到slave,能从slave读出;但在slave写入无法同步到master。
- 采用异步复制,master写入成功就向客户端返回成功,但是同步slave可能失败,会造成无法从slave读出的结果
- 需要该方案的请查看我的另一篇文章:https://www.cnblogs.com/lvlinguang/p/15205389.html
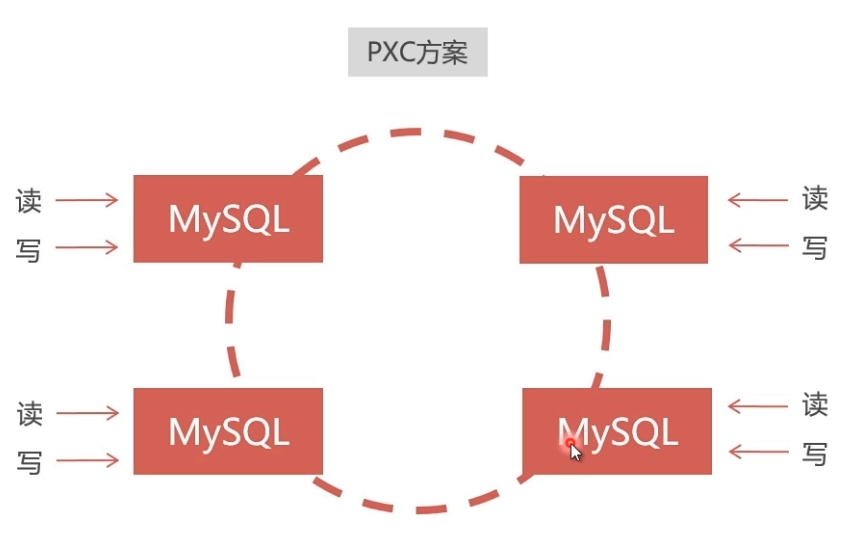
2、PXC (Percona XtraDB Cluster)
- 速度慢,但能保证强一致性,适用于保存价值较高的数据,比如订单、客户、支付等。
- 数据同步是双向的,在任一节点写入数据,都会同步到其他所有节点,在任何节点上都能同时读写。
- 采用同步复制,向任一节点写入数据,只有所有节点都同步成功后,才会向客户端返回成功。事务在所有节点要么同时提交,要么不提交。
二、安装PXC集群
1、安装镜像
docker pull percona/percona-xtradb-cluster:5.7.33
2、重命名镜像(缩短镜像名称)
docker tag percona/percona-xtradb-cluster:5.7.33 pxc
# 移除原镜像
docker rmi percona/percona-xtradb-cluster:5.7.33
3、创建net1网段
- 出于安全考虑,给PXC集群创建Docker内部网络
# 创建网段
docker network create --subnet=172.18.0.0/24 net1
# 查看网段
# docker network inspect net1
# 删除网段
# docker network rm net1
4、创建五个数据卷(pxc无法直接存取宿组机的数据,所以创建五个docker数据卷)
docker volume create v1
docker volume create v2
docker volume create v3
docker volume create v4
docker volume create v5
# 查看数据卷位置
#docker inspect v1
# 删除数据卷
#docker volume rm v1
5、创建5节点的PXC集群
- 第一个节点创建完成之后,需要等1分钟左右才能创建后面的节点。可以通过navicat连接第一个节点测试下,可以连接就说明可以了
#创建第1个MySQL节点
docker run -d --name=mysql-node1 -p 3310:3306 --privileged=true -e MYSQL_ROOT_PASSWORD=123456 -e CLUSTER_NAME=PXC -e XTRABACKUP_PASSWORD=abc123456 -v v1:/var/lib/mysql --net=net1 --ip 172.18.0.2 pxc
#创建第2个MySQL节点
docker run -d --name=mysql-node2 -p 3311:3306 --privileged=true -e MYSQL_ROOT_PASSWORD=123456 -e CLUSTER_NAME=PXC -e XTRABACKUP_PASSWORD=abc123456 -e CLUSTER_JOIN=mysql-node1 -v v2:/var/lib/mysql --net=net1 --ip 172.18.0.3 pxc
#创建第3个MySQL节点
docker run -d --name=mysql-node3 -p 3312:3306 --privileged=true -e MYSQL_ROOT_PASSWORD=123456 -e CLUSTER_NAME=PXC -e XTRABACKUP_PASSWORD=abc123456 -e CLUSTER_JOIN=mysql-node1 -v v3:/var/lib/mysql --net=net1 --ip 172.18.0.4 pxc
#创建第4个MySQL节点
docker run -d --name=mysql-node4 -p 3313:3306 --privileged=true -e MYSQL_ROOT_PASSWORD=123456 -e CLUSTER_NAME=PXC -e XTRABACKUP_PASSWORD=abc123456 -e CLUSTER_JOIN=mysql-node1 -v v4:/var/lib/mysql --net=net1 --ip 172.18.0.5 pxc
#创建第5个MySQL节点
docker run -d --name=mysql-node5 -p 3314:3306 --privileged=true -e MYSQL_ROOT_PASSWORD=123456 -e CLUSTER_NAME=PXC -e XTRABACKUP_PASSWORD=abc123456 -e CLUSTER_JOIN=mysql-node1 -v v5:/var/lib/mysql --net=net1 --ip 172.18.0.6 pxc
6、测试集群
- 通过navicat连接任意一个数据库,进行增、删、改操作操作,观察其它库是否进行同步操作

三、Haproxy负载均衡
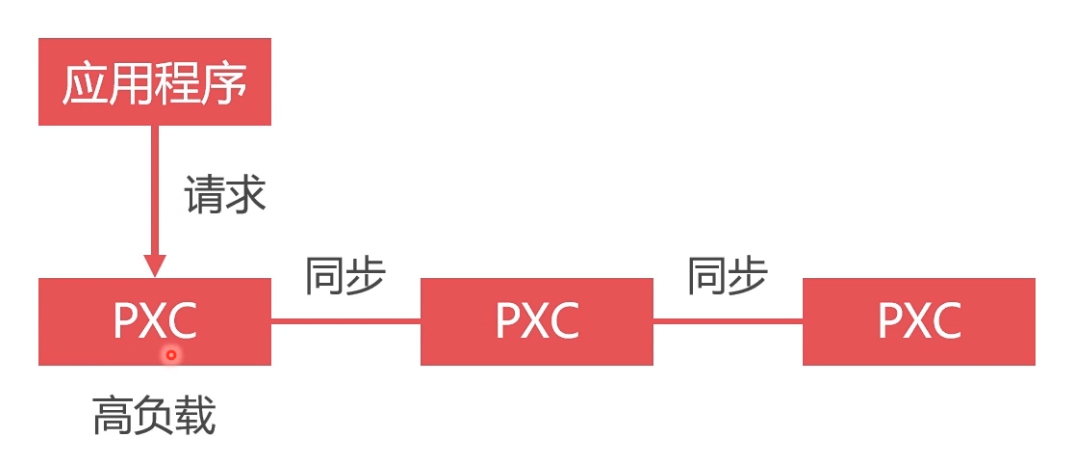
- 虽然搭建了集群,但是不使用数据库负载均衡,单节点处理所有请求,负载高,性能差,如下图
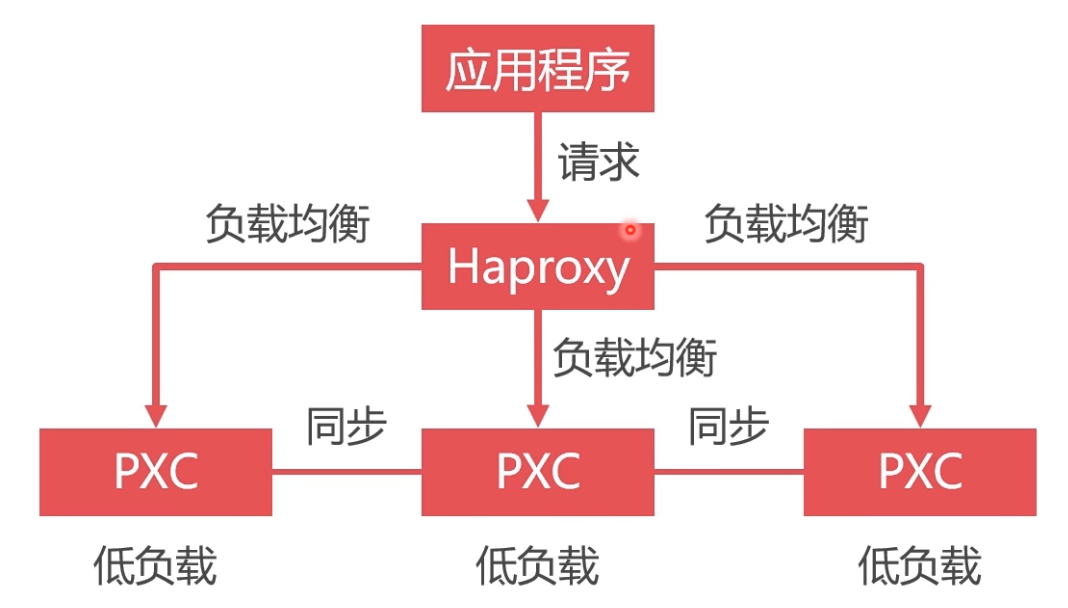
- 使用Haproxy做负载均衡,可以将请求均匀地发送给每个节点,单节点负载低,性能好,如下图
1、安装haproxy镜像
docker pull haproxy:2.3.13
2、新建目录
mkdir -p /home/apps/haproxy
3、新建Haproxy配置文件
vim /home/apps/haproxy/haproxy.cfg
# 增加以下内容
global
#工作目录
chroot /usr/local/etc/haproxy
#日志文件,使用rsyslog服务中local5日志设备(/var/log/local5),等级info
log 127.0.0.1 local5 info
#守护进程运行
daemon
defaults
log global
mode http
#日志格式
option httplog
#日志中不记录负载均衡的心跳检测记录
option dontlognull
#连接超时(毫秒)
timeout connect 5000
#客户端超时(毫秒)
timeout client 50000
#服务器超时(毫秒)
timeout server 50000
#监控界面
listen admin_stats
#监控界面的访问的IP和端口
bind 0.0.0.0:8888
#访问协议
mode http
#URI相对地址
stats uri /dbs
#统计报告格式
stats realm Global\ statistics
#登录帐户信息
stats auth admin:123456
#数据库负载均衡
listen proxy-mysql
#访问的IP和端口
bind 0.0.0.0:3306
#网络协议
mode tcp
#负载均衡算法(轮询算法)
#轮询算法:roundrobin
#权重算法:static-rr
#最少连接算法:leastconn
#请求源IP算法:source
balance roundrobin
#日志格式
option tcplog
#在MySQL中创建一个没有权限的haproxy用户,密码为空。Haproxy使用这个账户对MySQL数据库心跳检测
option mysql-check user haproxy
server mysql-node1 172.18.0.2:3306 check weight 1 maxconn 2000
server mysql-node2 172.18.0.3:3306 check weight 1 maxconn 2000
server mysql-node3 172.18.0.4:3306 check weight 1 maxconn 2000
server mysql-node4 172.18.0.5:3306 check weight 1 maxconn 2000
server mysql-node5 172.18.0.6:3306 check weight 1 maxconn 2000
#使用keepalive检测死链
option tcpka
3、在数据库集群中创建空密码、无权限用户haproxy,来供Haproxy对MySQL数据库进行心跳检测
# 进入容器
docker exec -it mysql-node1 /bin/bash
# 登录mysql
mysql -uroot -p123456
# 创建用户
create user 'haproxy'@'%' identified by '';
4、创建第1个Haproxy负载均衡服务器
docker run -it -d --name haproxy-node1 -p 4001:8888 -p 4002:3306 --restart always --privileged=true -v /home/apps/haproxy:/usr/local/etc/haproxy --net=net1 --ip 172.18.0.7 haproxy:2.3.13
5、启动Haproxy
# 进入容器
docker exec -it haproxy-node1 /bin/bash
# 启动haproxy
haproxy -f /usr/local/etc/haproxy/haproxy.cfg
四、访问测试
1、页面访问
- ip:4001/dbs,在配置文件中定义有用户名admin,密码123456
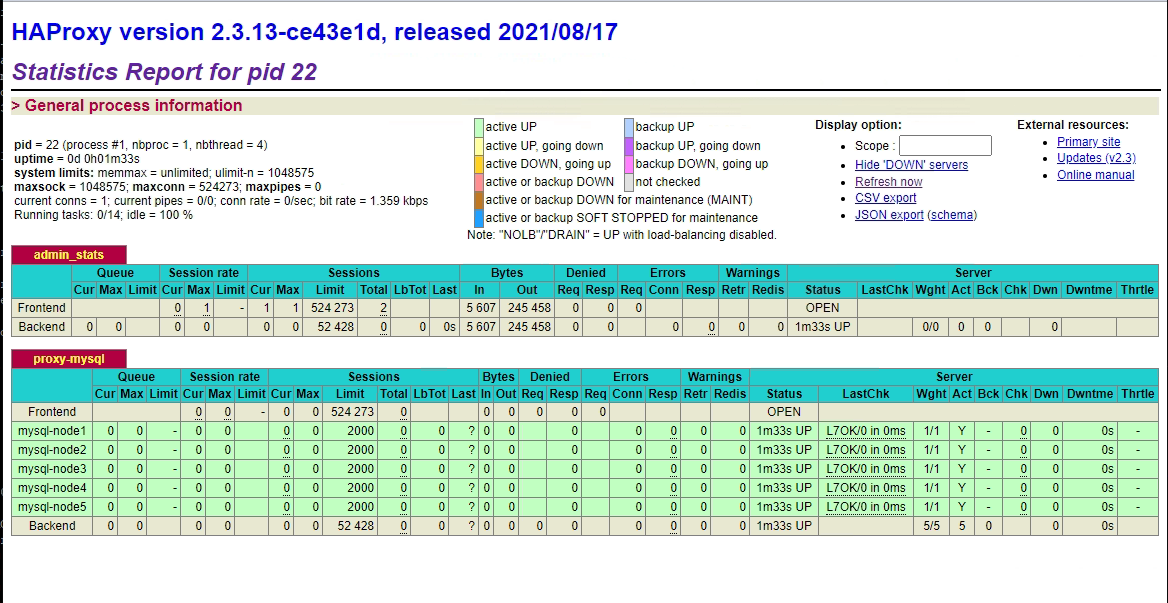
2、数据库访问
- 使用navacat访问代理集群,端口为4002

3、测试docker挂掉
- 分别下线第一和第二个节点,通过访问其它节点或代理节点都能正常使用
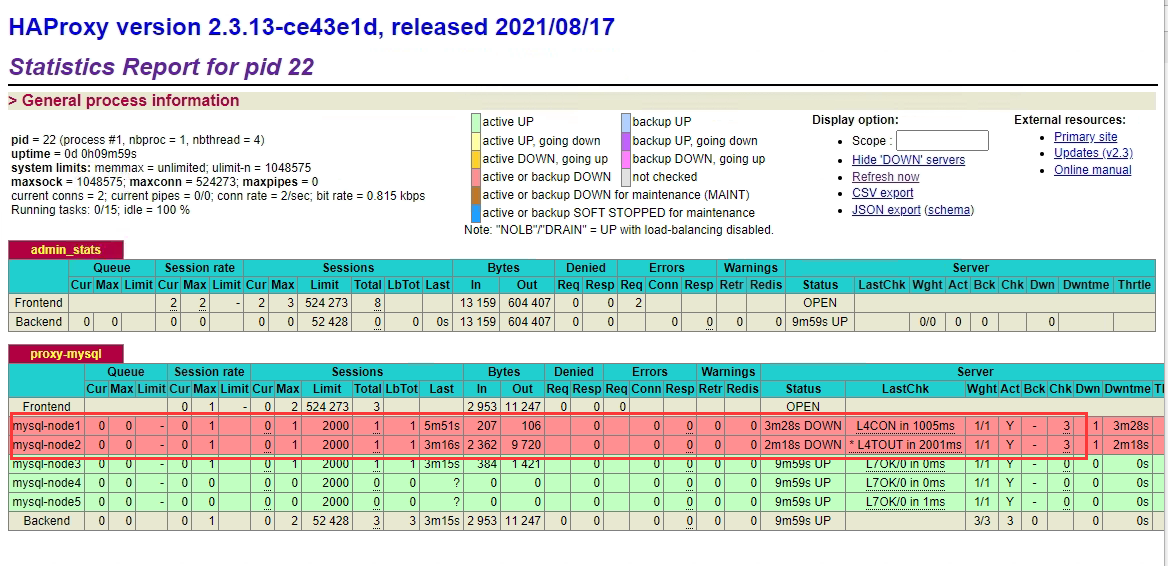
五、节点宕机或重启
1、从节点宕机后的操作
- 如果指定的主节点没有宕机,直接启动从节点容器,数据会自动同步
2、主节点宕机后的操作
- 【重启用此操作】如果主节点是最后一个离开集群的(说明数据是最新的),只要重启主节点即可,主节点的启动需要设置safe_to_bootstrap: 1 才能启动
# 修改grastate.dat
vim /var/lib/docker/volumes/v1/_data/grastate.dat
# 将以下值改为1
safe_to_bootstrap: 1
# 启动主节点
docker start mysql-node1
- 如果其他节点还在运行中,主节点挂掉了(说明主节点的数据已经不是最新的了),需要删除主节点容器,原来的数据卷无需删除(继续使用,避免数据丢失),然后再以从节点方式加入集群,注意加参数 "-e CLUSTER_JOIN=mysql-node2",指定可用的从节点启动
docker run -d --name=mysql-node1 -p 3310:3306 --privileged=true -e MYSQL_ROOT_PASSWORD=123456 -e CLUSTER_NAME=PXC -e XTRABACKUP_PASSWORD=abc123456 -e CLUSTER_JOIN=mysql-node2 -v v1:/var/lib/mysql --net=net1 --ip 172.18.0.2 pxc
3、另一种启动方式,删除集群容器和数据卷中的grastate.dat文件,重新创建
- 该方案会以主节点的数据恢复,如果主节点数据不是最新的,会造成数据丢失
# 移除容器
docker rm mysql-node1 mysql-node2 mysql-node3 mysql-node4 mysql-node5
# 移除数据卷中的grastate.dat文件
rm -rf /var/lib/docker/volumes/v1/_data/grastate.dat
rm -rf /var/lib/docker/volumes/v2/_data/grastate.dat
rm -rf /var/lib/docker/volumes/v3/_data/grastate.dat
rm -rf /var/lib/docker/volumes/v4/_data/grastate.dat
rm -rf /var/lib/docker/volumes/v5/_data/grastate.dat
# 按上面的方式重新创建集群容器
六、参考
- https://www.cnblogs.com/wanglei957/p/11819547.html
- https://www.cnblogs.com/zhenghongxin/p/9228101.html
- https://blog.csdn.net/belonghuang157405/article/details/80808541
- 节点宕机:https://www.cnblogs.com/wangbiaohistory/p/14638935.html
docker搭建mysql集群的更多相关文章
- docker 搭建Mysql集群
docker基本指令: 更新软件包 yum -y update 安装Docker虚拟机(centos 7) yum install -y docker 运行.重启.关闭Docker虚拟机 servic ...
- Docker搭建PXC集群
如何创建MySQL的PXC集群 下载PXC集群镜像文件 下载 docker pull percona/percona-xtradb-cluster 重命名 [root@hongshaorou ~]# ...
- Docker 搭建 etcd 集群
阅读目录: 主机安装 集群搭建 API 操作 API 说明和 etcdctl 命令说明 etcd 是 CoreOS 团队发起的一个开源项目(Go 语言,其实很多这类项目都是 Go 语言实现的,只能说很 ...
- Docker搭建RabbitMQ集群
Docker搭建RabbitMQ集群 Docker安装 见官网 RabbitMQ镜像下载及配置 见此博文 集群搭建 首先,我们需要启动运行RabbitMQ docker run -d --hostna ...
- docker搭建etcd集群环境
其实关于集群网上说的方案已经很多了,尤其是官网,只是这里我个人只有一个虚拟机,在开发环境下建议用docker-compose来搭建etcd集群. 1.拉取etcd镜像 docker pull quay ...
- docker 搭建zookeeper集群和kafka集群
docker 搭建zookeeper集群 安装docker-compose容器编排工具 Compose介绍 Docker Compose 是 Docker 官方编排(Orchestration)项目之 ...
- 使用Docker搭建Spark集群(用于实现网站流量实时分析模块)
上一篇使用Docker搭建了Hadoop的完全分布式:使用Docker搭建Hadoop集群(伪分布式与完全分布式),本次记录搭建spark集群,使用两者同时来实现之前一直未完成的项目:网站日志流量分析 ...
- 使用Docker搭建Hadoop集群(伪分布式与完全分布式)
之前用虚拟机搭建Hadoop集群(包括伪分布式和完全分布式:Hadoop之伪分布式安装),但是这样太消耗资源了,自学了Docker也来操练一把,用Docker来构建Hadoop集群,这里搭建的Hado ...
- 超详细,多图文使用galera cluster搭建mysql集群并介绍wsrep相关参数
超详细,多图文使用galera cluster搭建mysql集群并介绍wsrep相关参数 介绍galera cluster原理的文章已经有一大堆了,百度几篇看一看就能有相关了解,这里就不赘述了.本文主 ...
随机推荐
- PAT甲级:1025 PAT Ranking (25分)
PAT甲级:1025 PAT Ranking (25分) 题干 Programming Ability Test (PAT) is organized by the College of Comput ...
- redis数据类型及应用场景
0.key的通用操作 KEYS * keys a keys a* 查看已存在所有键的名字 ****TYPE 返回键所存储值的类型 ****EXPIRE\ PEXPIRE 以秒\毫秒设定生存时间 *** ...
- UIAutomator2 之 计算机积极拒绝
启动 问题: Failed to establish a new connection 由于目标计算机积极拒绝,无法连接 原因: 电脑重启被IE主动开了本地代理 解决: 网络设置-关闭手动代理
- 构建前端第12篇之---在Vue中对组件,变量,函数的全局引入
张燕涛写于2020-01-16 星期two 本篇还是源于import和export的使用,昨天看es6入门 和MDN文档,大体上用法了解了,但今天看ElementUI源码的时候,看到 //src/in ...
- 【LeetCode】204.计数质数
问题描述: 统计所有小于非负整数 n 的质数的数量. 示例: 输入: 10 输出: 4 解释: 小于 10 的质数一共有 4 个, 它们是 2, 3, 5, 7 . 这是一道简单题,但是却并没有那么直 ...
- 用Ubuntu的命令行来远程访问Jupyter Notebook
远程访问Jupyter Notebook 相关配置:Ubuntu 16.04服务器,本地Win10,使用了Xshell,Xftp工具. 相关配置主要分为三步: 服务器上的Jupyter配置 本地Xsh ...
- 图解 HTTP 连接管理
熟悉我的小伙伴都知道,我之前肝了本<HTTP 核心总结>的 PDF,这本 PDF 是取自我 HTTP 系列文章的汇总,然而我写的 HTTP 相关内容都是一年前了,我回头看了一下这本 PDF ...
- LAMP介绍以及Apache安装
一.LAMP架构介绍 1.1 LAMP概述 LAMP架构是目前成熟的企业网站应用模式之一,指的是协同工作的一整套系统和相关软件,能够提供动态Web站点服务及其应用开发环境.LAMP是一个缩写词,具体包 ...
- 剑指 Offer 32 - II. 从上到下打印二叉树 II
剑指 Offer 32 - II. 从上到下打印二叉树 II 从上到下按层打印二叉树,同一层的节点按从左到右的顺序打印,每一层打印到一行. 例如: 给定二叉树: [3,9,20,null,null,1 ...
- 2021字节跳动校招秋招算法面试真题解题报告--leetcode206 反转链表,内含7种语言答案
206.反转链表 1.题目描述 反转一个单链表. 示例: 输入: 1->2->3->4->5->NULL输出: 5->4->3->2->1-> ...