spring-data-redis 连接泄漏,我 TM 人傻了
本系列是 我TM人傻了 系列第四期[捂脸],往期精彩回顾:

本文基于 Spring Data Redis 2.4.9
最近线上又出事儿了,新上线了一个微服务系统,上线之后就开始报各种发往这个系统的请求超时,这是咋回事呢?

还是经典的通过 JFR 去定位(可以参考我的其他系列文章,经常用到 JFR),对于历史某些请求响应慢,我一般按照如下流程去看:
- 是否有 STW(Stop-the-world,参考我的另一篇文章:JVM相关 - SafePoint 与 Stop The World 全解):
- 是否有 GC 导致的长时间 STW
- 是否有其他原因导致进程所有线程进入 safepoint 导致 STW
- 是否 IO 花了太长时间,例如调用其他微服务,访问各种存储(硬盘,数据库,缓存等等)
- 是否在某些锁上面阻塞太长时间?
- 是否 CPU 占用过高,哪些线程导致的?
通过 JFR 发现是很多 HTTP 线程在一个锁上面阻塞了,这个锁是从 Redis 连接池获取连接的锁。我们的项目使用的 spring-data-redis,底层客户端使用 lettuce。为何会阻塞在这里呢?经过分析,我发现 spring-data-redis 存在连接泄漏的问题。

我们先来简单介绍下 Lettuce,简单来说 Lettuce 就是使用 Project Reactor + Netty 实现的 Redis 非阻塞响应式客户端。spring-data-redis 是针对 Redis 操作的统一封装。我们项目使用的是 spring-data-redis + Lettuce 的组合。
为了和大家尽量说明白问题的原因,这里先将 spring-data-redis + lettuce API 结构简单介绍下。
首先 lettuce 官方,是不推荐使用连接池的,但是官方没有说,这是什么情况下的决定。这里先放上结论:
- 如果你的项目中,使用的 spring-data-redis + lettuce,并且使用的都是 Redis 简单命令,没有使用 Redis 事务,Pipeline 等等,那么不使用连接池,是最好的(并且你没有关闭 Lettuce 连接共享,这个默认是开启的)。
- 如果你的项目中,大量使用了 Redis 事务,那么最好还是使用连接池
- 其实更准确地说,如果你使用了大量会触发
execute(SessionCallback)的命令,最好使用连接池,如果你使用的都是execute(RedisCallback)的命令,就不太有必要使用连接池了。如果大量使用 Pipeline,最好还是使用连接池。
接下来介绍下 spring-data-redis 的 API 原理。在我们的项目中,主要使用 spring-data-redis 的两个核心 API,即同步的 RedisTemplate 和异步的 ReactiveRedisTemplate。我们这里主要以同步的 RedisTemplate 为例子,说明原理。ReactiveRedisTemplate 其实就是做了异步封装,Lettuce 本身就是异步客户端,所以 ReactiveRedisTemplate 其实实现更简单。
RedisTemplate 的一切 Redis 操作,最终都会被封装成两种操作对象,一是 RedisCallback<T>:
public interface RedisCallback<T> {
@Nullable
T doInRedis(RedisConnection connection) throws DataAccessException;
}
是一个 Functional Interface,入参是 RedisConnection,可以通过使用 RedisConnection 操作 Redis。可以是若干个 Redis 操作的集合。大部分 RedisTemplate 的简单 Redis 操作都是通过这个实现的。例如 Get 请求的源码实现就是:
//在 RedisCallback 的基础上增加统一反序列化的操作
abstract class ValueDeserializingRedisCallback implements RedisCallback<V> {
private Object key;
public ValueDeserializingRedisCallback(Object key) {
this.key = key;
}
public final V doInRedis(RedisConnection connection) {
byte[] result = inRedis(rawKey(key), connection);
return deserializeValue(result);
}
@Nullable
protected abstract byte[] inRedis(byte[] rawKey, RedisConnection connection);
}
//Redis Get 命令的实现
public V get(Object key) {
return execute(new ValueDeserializingRedisCallback(key) {
@Override
protected byte[] inRedis(byte[] rawKey, RedisConnection connection) {
//使用 connection 执行 get 命令
return connection.get(rawKey);
}
}, true);
}
另一种是SessionCallback<T>:
public interface SessionCallback<T> {
@Nullable
<K, V> T execute(RedisOperations<K, V> operations) throws DataAccessException;
}
SessionCallback也是一个 Functional Interface,方法体也是可以放若干个命令。顾名思义,即在这个方法中的所有命令,都是会共享同一个会话,即使用的 Redis 连接是同一个并且不能被共享的。一般如果使用 Redis 事务则会使用这个实现。
RedisTemplate 的 API 主要是以下这几个,所有的命令底层实现都是这几个 API:
execute(RedisCallback<?> action)和executePipelined(final SessionCallback<?> session):执行一系列 Redis 命令,是所有方法的基础,里面使用的连接资源会在执行后自动释放。executePipelined(RedisCallback<?> action)和executePipelined(final SessionCallback<?> session):使用 PipeLine 执行一系列命令,连接资源会在执行后自动释放。executeWithStickyConnection(RedisCallback<T> callback):执行一系列 Redis 命令,连接资源不会自动释放,各种 Scan 命令就是通过这个方法实现的,因为 Scan 命令会返回一个 Cursor,这个 Cursor 需要保持连接(会话),同时交给用户决定什么时候关闭。

通过源码我们可以发现,RedisTemplate 的三个 API 在实际应用的时候,经常会发生互相嵌套递归的情况。
例如如下这种:
redisTemplate.executePipelined(new RedisCallback<Object>() {
@Override
public Object doInRedis(RedisConnection connection) throws DataAccessException {
orders.forEach(order -> {
connection.hashCommands().hSet(orderKey.getBytes(), order.getId().getBytes(), JSON.toJSONBytes(order));
});
return null;
}
});
和
redisTemplate.executePipelined(new RedisCallback<Object>() {
@Override
public Object doInRedis(RedisConnection connection) throws DataAccessException {
orders.forEach(order -> {
redisTemplate.opsForHash().put(orderKey, order.getId(), JSON.toJSONString(order));
});
return null;
}
});
是等价的。redisTemplate.opsForHash().put()其实调用的是 execute(RedisCallback) 方法,这种就是 executePipelined 与 execute(RedisCallback) 嵌套,由此我们可以组合出各种复杂的情况,但是里面使用的连接是怎么维护的呢?
其实这几个方法获取连接的时候,使用的都是:RedisConnectionUtils.doGetConnection 方法,去获取连接并执行命令。对于 Lettuce 客户端,获取的是一个 org.springframework.data.redis.connection.lettuce.LettuceConnection. 这个连接封装包含两个实际 Lettuce Redis 连接,分别是:
private final @Nullable StatefulConnection<byte[], byte[]> asyncSharedConn;
private @Nullable StatefulConnection<byte[], byte[]> asyncDedicatedConn;
- asyncSharedConn:可以为空,如果开启了连接共享,则不为空,默认是开启的;所有 LettuceConnection 共享的 Redis 连接,对于每个 LettuceConnection 实际上都是同一个连接;用于执行简单命令,因为 Netty 客户端与 Redis 的单处理线程特性,共享同一个连接也是很快的。如果没开启连接共享,则这个字段为空,使用 asyncDedicatedConn 执行命令。
- asyncDedicatedConn:私有连接,如果需要保持会话,执行事务,以及 Pipeline 命令,固定连接,则必须使用这个 asyncDedicatedConn 执行 Redis 命令。
我们通过一个简单例子来看一下执行流程,首先是一个简单命令:redisTemplate.opsForValue().get("test"),根据之前的源码分析,我们知道,底层其实就是 execute(RedisCallback),流程是:
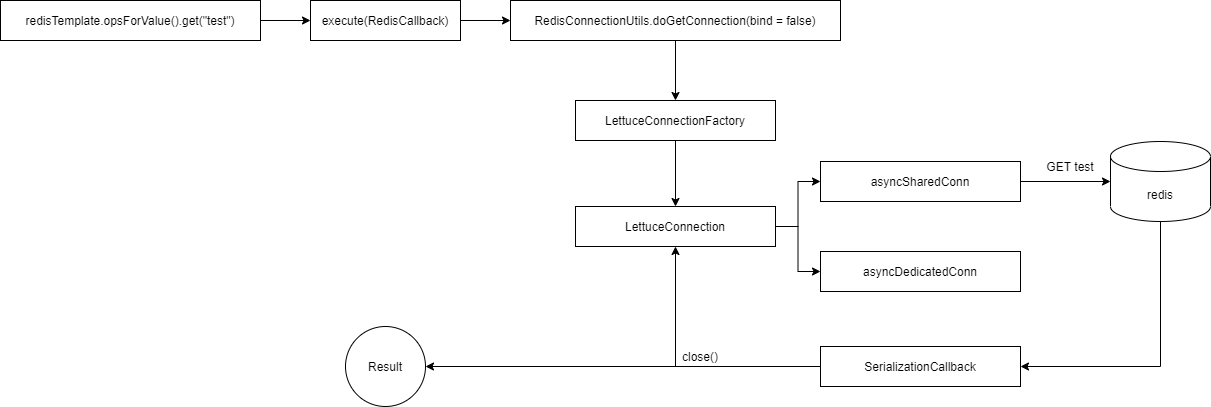
可以看出,如果使用的是 RedisCallback,那么其实不需要绑定连接,不涉及事务。Redis 连接会在回调内返回。需要注意的是,如果是调用 executePipelined(RedisCallback),需要使用回调的连接进行 Redis 调用,不能直接使用 redisTemplate 调用,否则 pipeline 不生效:
Pipeline 生效:
List<Object> objects = redisTemplate.executePipelined(new RedisCallback<Object>() {
@Override
public Object doInRedis(RedisConnection connection) throws DataAccessException {
connection.get("test".getBytes());
connection.get("test2".getBytes());
return null;
}
});
Pipeline 不生效:
List<Object> objects = redisTemplate.executePipelined(new RedisCallback<Object>() {
@Override
public Object doInRedis(RedisConnection connection) throws DataAccessException {
redisTemplate.opsForValue().get("test");
redisTemplate.opsForValue().get("test2");
return null;
}
});
然后,我们尝试将其加入事务中,由于我们的目的不是真的测试事务,只是为了演示问题,所以,仅仅是用 SessionCallback 将 GET 命令包装起来:
redisTemplate.execute(new SessionCallback<Object>() {
@Override
public <K, V> Object execute(RedisOperations<K, V> operations) throws DataAccessException {
return operations.opsForValue().get("test");
}
});
这里最大的区别就是,外层获取连接的时候,这次是 bind = true 即将连接与当前线程绑定,用于保持会话连接。外层流程如下:
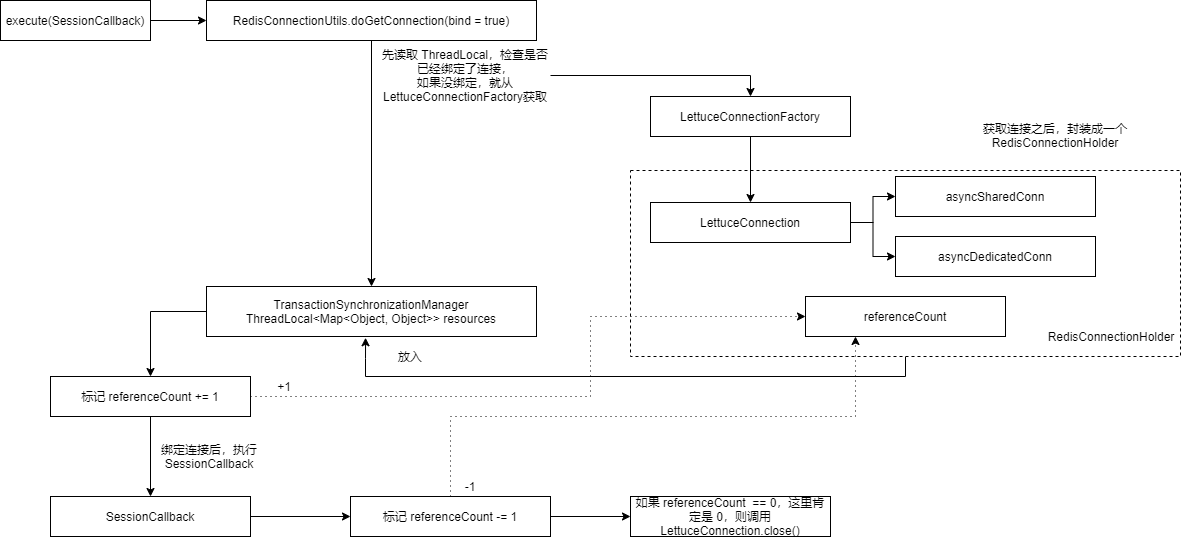
里面的 SessionCallback 其实就是 redisTemplate.opsForValue().get("test"),使用的是共享的连接,而不是独占的连接,因为我们这里还没开启事务(即执行 multi 命令),如果开启了事务使用的就是独占的连接,流程如下:
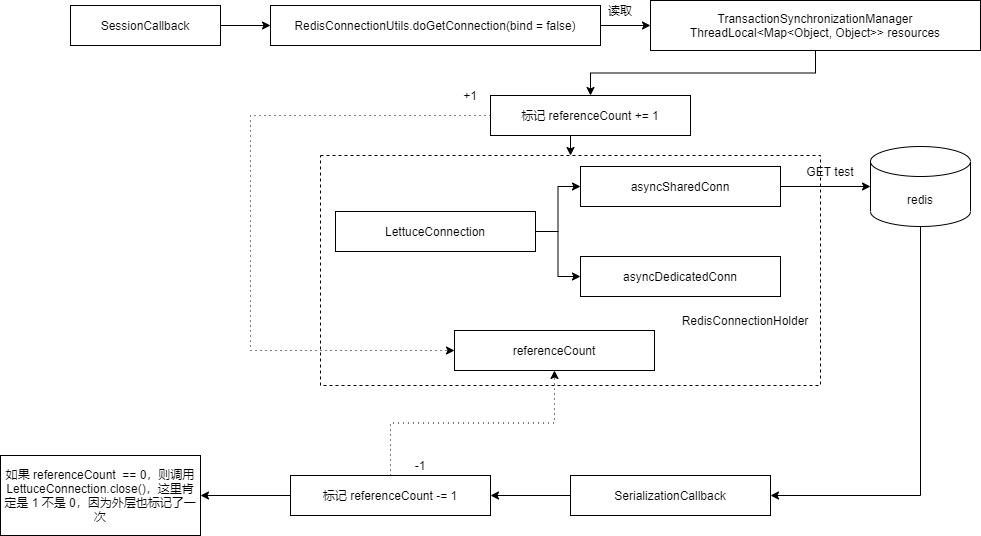
由于 SessionCallback 需要保持连接,所以流程有很大变化,首先需要绑定连接,其实就是获取连接放入 ThreadLocal 中。同时,针对 LettuceConnection 进行了封装,我们主要关注这个封装有一个引用计数的变量。每嵌套一次 execute 就会将这个计数 + 1,执行完之后,就会将这个计数 -1, 同时每次 execute 结束的时候都会检查这个引用计数,如果引用计数归零,就会调用 LettuceConnection.close()。
接下来再来看,如果是 executePipelined(SessionCallback) 会怎么样:
List<Object> objects = redisTemplate.executePipelined(new SessionCallback<Object>() {
@Override
public <K, V> Object execute(RedisOperations<K, V> operations) throws DataAccessException {
operations.opsForValue().get("test");
return null;
}
});
其实与第二个例子在流程上的主要区别在于,使用的连接不是共享连接,而是直接是独占的连接。
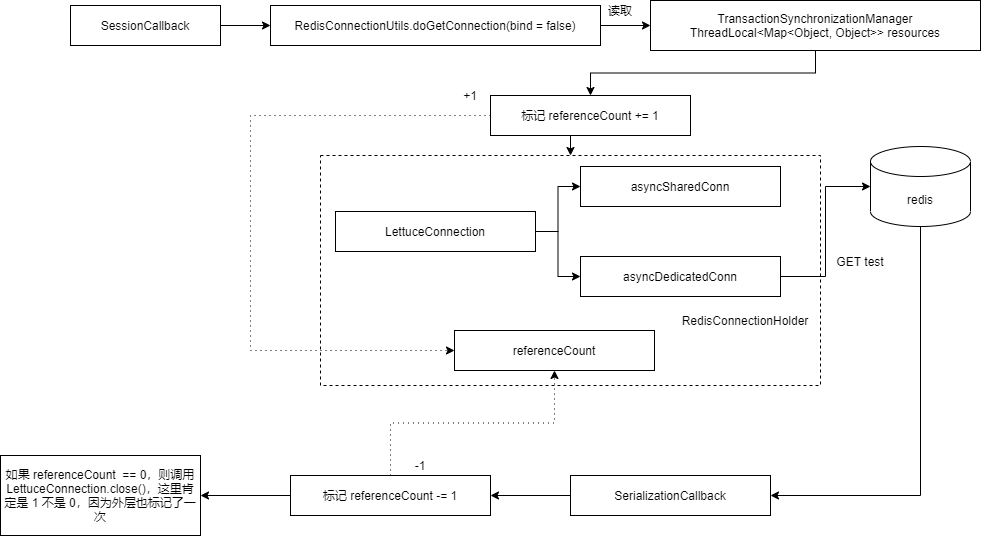
最后我们再来看一个例子,如果是在 execute(RedisCallback) 中执行基于 executeWithStickyConnection(RedisCallback<T> callback) 的命令会怎么样,各种 SCAN 就是基于 executeWithStickyConnection(RedisCallback<T> callback) 的,例如:
redisTemplate.execute(new SessionCallback<Object>() {
@Override
public <K, V> Object execute(RedisOperations<K, V> operations) throws DataAccessException {
Cursor<Map.Entry<Object, Object>> scan = operations.opsForHash().scan((K) "key".getBytes(), ScanOptions.scanOptions().match("*").count(1000).build());
//scan 最后一定要关闭,这里采用 try-with-resource
try (scan) {
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
});
这里 Session callback 的流程,如下图所示,因为处于 SessionCallback,所以 executeWithStickyConnection 会发现当前绑定了连接,于是标记 + 1,但是并不会标记 - 1,因为 executeWithStickyConnection 可以将资源暴露到外部,例如这里的 Cursor,需要外部手动关闭。
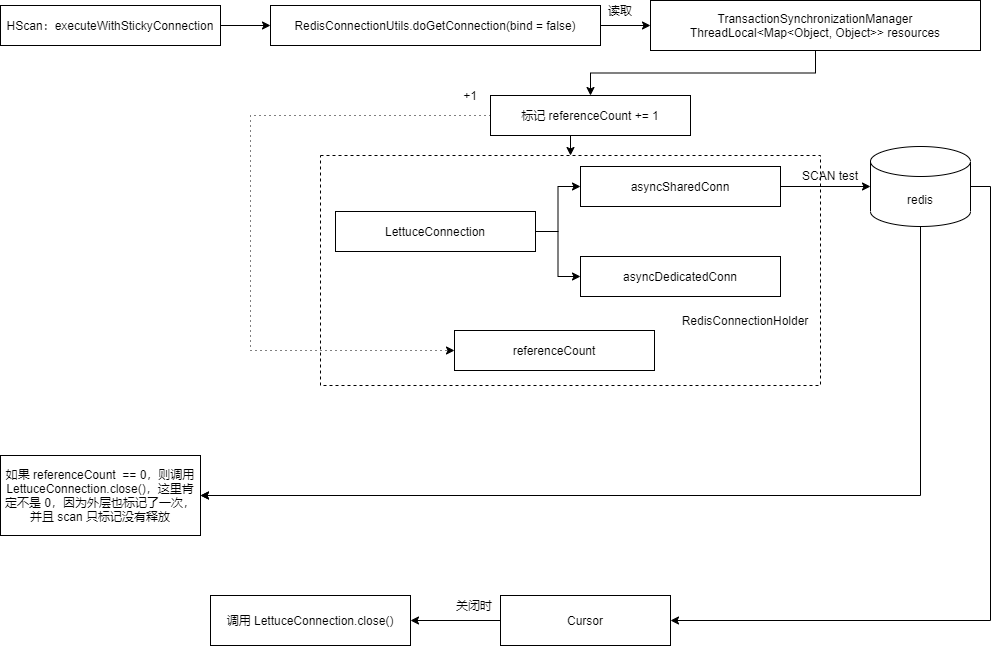

在这个例子中,会发生连接泄漏,首先执行:
redisTemplate.execute(new SessionCallback<Object>() {
@Override
public <K, V> Object execute(RedisOperations<K, V> operations) throws DataAccessException {
Cursor<Map.Entry<Object, Object>> scan = operations.opsForHash().scan((K) "key".getBytes(), ScanOptions.scanOptions().match("*").count(1000).build());
//scan 最后一定要关闭,这里采用 try-with-resource
try (scan) {
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
});
这样呢,LettuceConnection 会和当前线程绑定,并且在结束时,引用计数不为零,而是 1。并且 cursor 关闭时,会调用 LettuceConnection 的 close。但是 LettuceConnection 的 close 的实现,其实只是标记状态,并且把独占的连接 asyncDedicatedConn 关闭,由于当前没有使用到独占的连接,所以为空,不需要关闭;如下面源码所示:
@Override
public void close() throws DataAccessException {
super.close();
if (isClosed) {
return;
}
isClosed = true;
if (asyncDedicatedConn != null) {
try {
if (customizedDatabaseIndex()) {
potentiallySelectDatabase(defaultDbIndex);
}
connectionProvider.release(asyncDedicatedConn);
} catch (RuntimeException ex) {
throw convertLettuceAccessException(ex);
}
}
if (subscription != null) {
if (subscription.isAlive()) {
subscription.doClose();
}
subscription = null;
}
this.dbIndex = defaultDbIndex;
}
之后我们继续执行一个 Pipeline 命令:
List<Object> objects = redisTemplate.executePipelined(new RedisCallback<Object>() {
@Override
public Object doInRedis(RedisConnection connection) throws DataAccessException {
connection.get("test".getBytes());
redisTemplate.opsForValue().get("test");
return null;
}
});
这时候由于连接已经绑定到当前线程,同时同上上一节分析我们知道第一步解开释放这个绑定,但是调用了 LettuceConnection 的 close。执行这个代码,会创建一个独占连接,并且,由于计数不能归零,导致连接一直与当前线程绑定,这样,这个独占连接一直不会关闭(如果有连接池的话,就是一直不返回连接池)
即使后面我们手动关闭这个链接,但是根据源码,由于状态 isClosed 已经是 true,还是不能将独占链接关闭。这样,就会造成连接泄漏。
针对这个 Bug,我已经向 spring-data-redis 一个 Issue:Lettuce Connection Leak while using execute(SessionCallback) and executeWithStickyConnection in same thread by random turn

- 尽量避免使用
SessionCallback,尽量仅在需要使用 Redis 事务的时候,使用SessionCallback。 - 使用
SessionCallback的函数单独封装,将事务相关的命令单独放在一起,并且外层尽量避免再继续套RedisTemplate的execute相关函数。
微信搜索“我的编程喵”关注公众号,每日一刷,轻松提升技术,斩获各种offer:

spring-data-redis 连接泄漏,我 TM 人傻了的更多相关文章
- spring data redis使用1——连接的创建
spring data redis集成了几个Redis客户端框架,Jedis , JRedis (Deprecated since 1.7), SRP (Deprecated since 1.7) a ...
- Spring Cloud Gateway 雪崩了,我 TM 人傻了
本系列是 我TM人傻了 系列第六期[捂脸],往期精彩回顾: 升级到Spring 5.3.x之后,GC次数急剧增加,我TM人傻了 这个大表走索引字段查询的 SQL 怎么就成全扫描了,我TM人傻了 获取异 ...
- Spring Cloud Gateway 没有链路信息,我 TM 人傻了(下)
本系列是 我TM人傻了 系列第五期[捂脸],往期精彩回顾: 升级到Spring 5.3.x之后,GC次数急剧增加,我TM人傻了 这个大表走索引字段查询的 SQL 怎么就成全扫描了,我TM人傻了 获取异 ...
- spring-data-redis 上百万的 QPS 压力太大连接失败,我 TM 人傻了
大家好,我们最近业务量暴涨,导致我最近一直 TM 人傻了.前几天晚上,发现由于业务压力激增,某个核心微服务新扩容起来的几个实例,在不同程度上,出现了 Redis 连接失败的异常: org.spring ...
- Spring Data Redis 让 NoSQL 快如闪电(2)
[编者按]本文作者为 Xinyu Liu,文章的第一部分重点概述了 Redis 方方面面的特性.在第二部分,将介绍详细的用例.文章系国内 ITOM 管理平台 OneAPM 编译呈现. 把 Redis ...
- Spring Cloud Gateway 没有链路信息,我 TM 人傻了(上)
本系列是 我TM人傻了 系列第五期[捂脸],往期精彩回顾: 升级到Spring 5.3.x之后,GC次数急剧增加,我TM人傻了 这个大表走索引字段查询的 SQL 怎么就成全扫描了,我TM人傻了 获取异 ...
- Spring Cloud Gateway 没有链路信息,我 TM 人傻了(中)
本系列是 我TM人傻了 系列第五期[捂脸],往期精彩回顾: 升级到Spring 5.3.x之后,GC次数急剧增加,我TM人傻了 这个大表走索引字段查询的 SQL 怎么就成全扫描了,我TM人傻了 获取异 ...
- Spring Cloud Gateway 不小心换了个 Web 容器就不能用了,我 TM 人傻了
个人创作公约:本人声明创作的所有文章皆为自己原创,如果有参考任何文章的地方,会标注出来,如果有疏漏,欢迎大家批判.如果大家发现网上有抄袭本文章的,欢迎举报,并且积极向这个 github 仓库 提交 i ...
- spring data redis RedisTemplate操作redis相关用法
http://blog.mkfree.com/posts/515835d1975a30cc561dc35d spring-data-redis API:http://docs.spring.io/sp ...
随机推荐
- Pytest单元测试框架之parametrize参数化
1.参数化的本质:相同的步骤,但测试数据不同,比如登录的场景 import mathimport pytest# 方式一:分离出Listdef list_Test(): list = [ [2, 2, ...
- 微信小程序云开发-云存储-上传文件(word/excel/ppt/pdf)到云存储
说明 word/excel/ppt/pdf是从客户端会话选择文件.使用chooseMessageFile中选择文件. 一.wxml文件 上传按钮,绑定chooseFile <!--上传文件(wo ...
- PAT乙级:1092 最好吃的月饼 (20分)
PAT乙级:1092 最好吃的月饼 (20分) 题干 月饼是久负盛名的中国传统糕点之一,自唐朝以来,已经发展出几百品种. 若想评比出一种"最好吃"的月饼,那势必在吃货界引发一场腥风 ...
- windows系统下 PHP怎么安装redis扩展
在windows系统下安装redis就不赘述了,基本上就是下一步,下一步. 然后通过通过命令行启动服务. 我是在xamp 3.2.2的集成环境下进行本地redis扩展安装配置的,php的版本是5.6. ...
- 记一次Vue跨导航栏问题解决方案
简述 这篇文章是我项目中,遇到的一个issue,我将解决过程和方法记录下来. 本篇文章基于Vue.js进行的前端页面构建,由于仅涉及前端,将不做数据来源及其他部分的叙述.使用的CSS框架是 Boots ...
- STEVE JOBS: Stanford Commencement【Stay Hungry. Stay Foolish.】
In 2005, a year after he was first diagnosed with cancer, Apple CEO Steve Jobs made a candid speech ...
- 解决proto文件生成pb文件时提示(e.g."message")的问题
原因:格式不支持 解决办法:去下个notepad,打开方式选择notepad,文件属性的只读取消掉 打开后会发现最下面显示了文件的格式是unix,utf-8 右键红框处,选择转换为windows格式, ...
- k8s系列文章第五篇(docker-compose)
更多精彩内容,猛搓这里 目录 一.Docker Compose 1.前言 2.官方介绍 1.Compose 中有两个重要的概念 2.三步骤 3.Compose是Docker官方的开源项目,需要安装! ...
- Vmware 虚拟机网络通讯
VMware Workstation(中文名"威睿工作站")是一款功能强大的桌面虚拟计算机软件,提供用户可在单一的桌面上同时运行不同的操作系统,和进行开发.测试 .部署新的应用程序 ...
- linux下利用JMX监控Tomcat
利用JMX监控Tomcat,就是相当于部署在tomcat上的应用作为服务端,也就是被管理资源的对象.然后通过程序或者jconsole远程连接到该应用上来.远程连接需要服务器端提供ip和port.如果需 ...