zookeeper的简介和相关命令操作
.personSunflowerP { background: rgba(51, 153, 0, 0.66); border-bottom: 1px solid rgba(0, 102, 0, 1); border-top-left-radius: 7px; border-top-right-radius: 7px; color: rgba(255, 255, 255, 1); height: 1.8em; line-height: 1.8em; padding: 5px }
1. zookeeper的简介
zookeeper由文件系统和通知机制构成
应用场景:
①dubbo+ zookeeper 实现rpc远程调用中
②负载均衡
③发布订阅
④分布通知、分布式锁
1)文件系统
Zookeeper使用树形结构管理数据。而且以“/”作为树形结构的根节点。树形结构中的每一个节点都是一个“znode”。文件系统中的目录可以存放其他目录和文件,znode中可以存放其他znode,也可以对应一个具体的值,znode和它对应的值之间是键值对的关系。
树形结构
①树形结构的主体由znode组成
②每一个节点包含下面两部分
I. 值:节点的路径和当前节点上保存的值构成一个“键值对(key-value)”关系
II. 状态 stat
2)通知机制
在分布式项目中随着业务功能越来越多,具体的功能模块也会越来越多,一个大型的电商项目能达到几十个模块甚至更多。这么多模块的工程由可能需要共享一些信息,这些信息一但发生变化,各个相关模块工程中手动逐一修改会非常的麻烦,甚至可能发生遗漏。
使用ZooKeeper的通知机制后,各个模块工程在特定的znode上设置Watcher(观察者)来监控当前节点上值的变化,一旦Watcher检测到了数据变化就会立即通知模块,从而实现“一处修改,处处生效”的效果。
①目的:一处修改处处更新
②机制:观察者模式
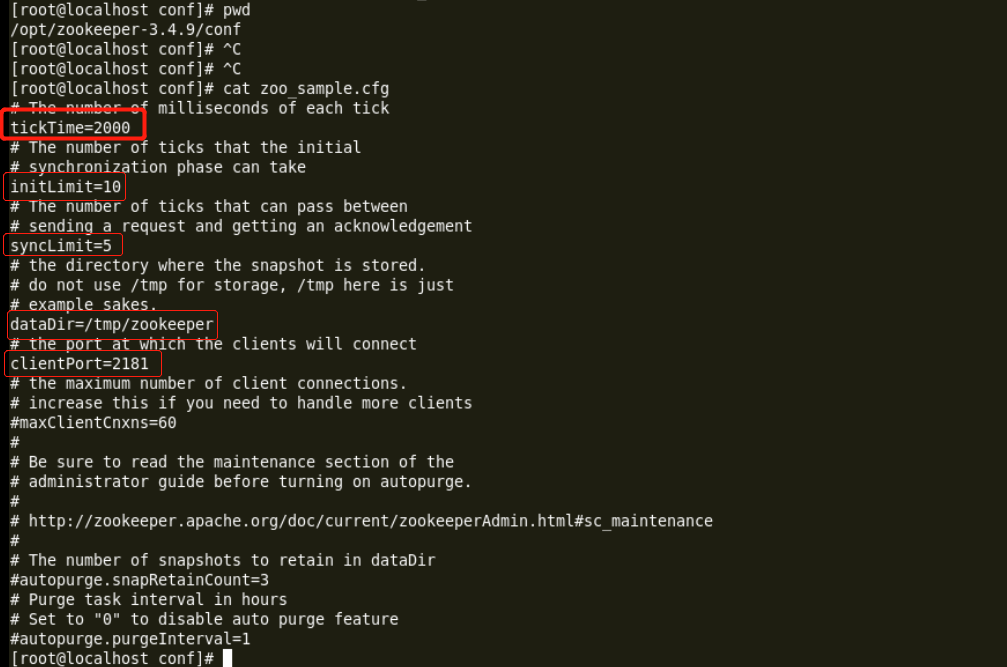
2. zoo_sample.cfg文件解析
该文件在zookeeper的解压包的conf中(如:/opt/zookeeper-3.4.9/conf)
文件中的各个参数的说明:
1)tickTime 通信心跳数,zookeeper服务器心跳时间,单位毫秒。
Zookeeper使用的基本时间,服务器之间或者客户端与服务器之间维持心跳的时间间隔,也就是每个tickTime时间就会发送一个心跳。
用于心跳机制,并且设置最小的session超时时间为两倍心跳时间(session的最小超时时间是2 * tickTime)。
2)initLimit LF初始通信时限
集群中的Follower跟随者服务器(F)与Leader领导者服务器(L)之间初始连接时能容忍的最多心跳数(tickTime的数量)
投票选举新Leader的初始化时间Follower在启动过程中,会从Leader同步所有最新数据,然后确定自己能够对外服务的起始状态。
Leader允许Follower在initLimit时间内完成这个工作。
3)syncLimit LF同步通信时限
集群中Leader与Follwer之间的最大响应时间单位,假如响应超过syncLimit * tickTime,Leader认为Follwer死掉,从服务器列表中删除Follower
在运行过程中,Leader负责与ZooKeeper集群中所有机器进行通信,例如通过一些心跳检测机制,来检测机器的存活状态。
如果L发出心跳包在syncLimit之后,还没有从F那收到响应,那么久认为这个F已经不在线了。
4)dataDir 数据文件目录 + 数据持久化路径
保存内存数据库快照信息的位置,如果没有其他说明,更新的事务日志也保存到数据库。
5)clientPort 客户端连接端口
3. ZooKeeper常用命令
1)服务端的相关命令(在zookeeper安装目录的bin目录下)
启动:./zkServer.sh start
停止:./zkServer.sh stop
查看状态:./zkServer.sh status
2)客户端的相关命令
进入:./zkClient.sh
退出:quit
3)客户端节点相关操作
①ls / ls2
②create [-s] [-e] path data 创建节点和节点上对应的值
【-s】:含有序列
【-e】:临时(重启或者超时消失)
【path】:节点的路径
【data】:节点上绑定的值
例:create /test abc
③delete和rmr
【delete】 只能删除空节点
【rmr】可以在删除当前节点时递归删除子节点
④stat path 查看状态
4)节点值操作命令
①set path data:设置值
例:set /test aaa
②get path data:获取值
例:get /test
注:若敲错了命令,则会给出所有的命令操作提示信息
5)关于状态stat信息的详细说明:
简介:znode维护了一个stat结构,这个stat包含数据变化的版本号、访问控制列表变化、还有时间戳。版本号和时间戳一起,可让ZooKeeper验证缓存和协调更新。每次znode的数据发生了变化,版本号就增加。
参数说明:
czxid:引起这个znode创建的zxid,创建节点的事务的zxid(ZooKeeper Transaction Id)
ctime:znode被创建的毫秒数(从1970年开始)
mzxid:znode最后更新的zxid
mtime:znode最后修改的毫秒数(从1970年开始)
pZxid:znode最后更新的子节点zxid
cversion:znode子节点变化号,znode子节点修改次数
dataversion:znode数据变化号
aclVersion:znode访问控制列表的变化号
ephemeralOwner:如果是临时节点,这个是znode拥有者的session id。如果不是临时节点则是0。
dataLength:znode的数据长度
numChildren:znode子节点数量
6)四字命令
ZooKeeper支持某些特定的四字命令,他们大多是用来查询ZooKeeper服务的当前状态及相关信息的,使用时通过telnet或nc向ZooKeeper提交相应命令。例:echo ruok | nc localhost 2181
①nc命令需要安装对应的程序才可以使用。
yum install -y nc
②常用四字命令
ruok:测试服务是否处于正确状态。如果确实如此,那么服务返回“imok ”,否则不做任何相应
stat:输出关于性能和连接的客户端的列表
conf:输出相关服务配置的详细信息
cons:列出所有连接到服务器的客户端的完全的连接 /会话的详细信息。包括“接受 / 发送”的包数量、会话id 、操作延迟、最后的操作执行等等信息
dump:列出未经处理的会话和临时节点
envi:输出关于服务环境的详细信息(区别于conf命令)
reqs:列出未经处理的请求
wchs:列出服务器watch的详细信息
wchc:通过session列出服务器watch的详细信息,它的输出是一个与watch相关的会话的列表
wchp:通过路径列出服务器 watch的详细信息。它输出一个与 session相关的路径
zookeeper的简介和相关命令操作的更多相关文章
- ZooKeeper系列(3)命令操作 (转)
原文地址:http://www.cnblogs.com/wuxl360/p/5817524.html 一.Zookeeper的四字命令 Zookeeper支持某些特定的四字命令字母与其的交互.他们大多 ...
- linux中weblogic相关命令操作
在weblogic的目录下找到bin目录,其中有startWeblogic.sh.startManagerWeblogic.sh等 首先需要启动startWeblogic.sh,这个是管理服务,也就是 ...
- Set,Sorted Set相关命令操作,批量插入及管道,事务
Set SADD key member [member ...] 向key指定的set集合添加成员,次集合是排重的,从2.4版本后才支持添加多个如果key不存在则创建key以及set集合返回当前操作成 ...
- gitlab相关命令操作
[root@xuegod63 ~]# git config --global user.name "zsl3"[root@xuegod63 ~]# git config --glo ...
- Linux for CentOS 下的 keepalived 安装与卸载以及相关命令操作之详细教程
百度百科解释: keepalived 是一个类似于 layer3, 4 & 7 交换机制的软件,也就是我们平时说的第 3 层.第 4 层和第 7 层交换.Keepalived 的作用是检测 w ...
- windows环境变量和相关命令操作
1.很多程序在windows上运行都需要设置环境变量. 2.具体步骤 复制路径 打开系统设置 高级系统设置 环境变量 设置path 重启cmd 3.可以把路径设置成变量,这样就不用随时 改path而是 ...
- Redis中String类型的相关命令操作
String append 如果key已存在,则直接在value追加值,如果key不存在,则会插件一个新的value为空的key,然后在追加 127.0.0.1:6379> set name l ...
- 光盘 iso 镜像制作相关命令操作
1. 安装制作工具 mkisofs yum install mkisofs -y 2. Linux 操作系统镜像 iso 打包 mkisofs -o /root/.iso \ -V mini7 -b ...
- Redis客户端、服务端的安装以及命令操作
目的: redis简介 redis服务端安装 redis客户端安装 redis相关命令操作 redis简介 官网下载(https://redis.io/) Redis 是完全开源免费的,遵守BSD协议 ...
随机推荐
- JS 获取JSON数据的属性
var tballdata= [{ 'tjqd': '', 'A1': '', 'A2': '', 'A3': '', 'A4': '' };] if (typeof tballdata[0] == ...
- 5shell中的数组
0.理解数组 (1)shell不限制数组的大小,数组元素的下标从0开始计数 (2)获取数组中的元素要使用下标[ ],下标可以是一个整数,也可以是一个结果为整数的表达式,但是下标必须大于等于0 (3)b ...
- 重学Docker
转了云方向,代码都少写了 1. 为什么出现Docker 以前开发项目有开发的环境.测试的环境.还有生产的环境,每经过一阶段就要迁移项目.不同的环境有不同的配置,可能导致不可预估的错误,运维要经常性的改 ...
- 「CF1208G」 Polygons
「CF1208G」 Polygons 似乎我校神犇在很久以前和我提过这题? 首先有一点显而易见:这 \(k\) 个多边形肯定至少有一个公共的顶点.假设我们将此点定义为起点. 那么对于一个正 \(n\) ...
- 交通规则:HOV车道
多乘员车道的限行时间一般为工作日上下班高峰,车上只有一个人时不能走该车道
- 前端开发入门到进阶第三集【JavaScript中如何将html字符串转化为Jquery对象或者Dom对象】
https://www.cnblogs.com/mingjiatang/p/4746845.html
- MySql数据库-查询、插入数据时转义函数的使用
最近在看一部php的基础视频教程,在做案例的时,当通过用户名查询用户信息的时候,先使用了转义函数对客户提交的内容进行过滤之后再交给sql语句进行后续的操作.虽然能看到转义函数本身的作用,但是仍然有一些 ...
- 配置软ISCSI存储
说明:这里是Linux服务综合搭建文章的一部分,本文可以作为单独使用RedHat Enterprise Linux 7搭建软ISCSI的参考. 注意:这里所有的标题都是根据主要的文章(Linux基础服 ...
- Python基础之用PyQt5创建menu
前一篇文章中,我们已经安装了PyQt5,并且已经测试过可用.那么接下来第一步开始学习如何创建菜单. 第一步:在想要运行py的地方右击External Tools-->designer,打开des ...
- intouch制作历史报警查询(时间查询,筛选关键字)
在项目中,intouch制作历史报警查询已属于标配功能,如何做出按时间以及关键字来进行综合查询,提高历史报警查询效率仍然是一个值得研究的问题,接下来参考网上文章自己总结下如何制作. 1.DTPicke ...