4.3CNN卷积神经网络最详细最容易理解--tensorflow源码MLP对比
自己开发了一个股票智能分析软件,功能很强大,需要的点击下面的链接获取:
https://www.cnblogs.com/bclshuai/p/11380657.html
1.1 CNN卷积神经网络
1.1.1 什么是CNN卷积神经网络
CNN(convolutional neural network)卷积神经网络是一种具有局部连接和权重共享等特性的深层前馈神经网络。简单来说神经网络都是为了提取特征。卷积提取特征的方式如下图所示,加入图片是5*5个像素的图片,用一个3*3的卷积核在图片矩阵上移动,用卷积核中行列中的值乘以图片数据中3*3的数据值,得到一个值,作为图片区域的特征值,然后卷积核向右移动一位,继续计算。移动到最右边,在向下移动一格,从左往右继续计算,最后将5*5的图片数据,转化为3*3的图片特征数据,转化后的图片特征数据仍然保留着原始图片数据的特征。
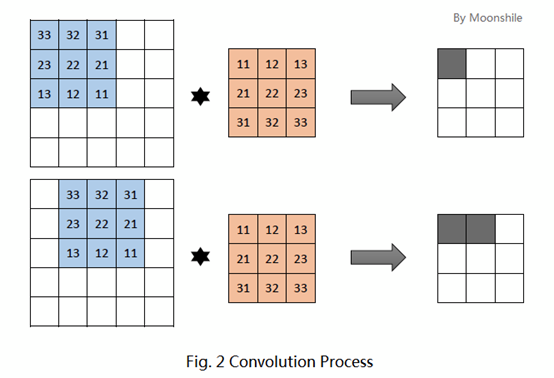
1.1.2 卷积神经网络解决什么问题
(1) 全连接参数过多的问题
全连接层如果图片是100*100*3(高,宽,RGB三色值),则第一个隐藏层的参数有30000个。参数多会导致训练效率低,也容易出现过拟合。
(2) 局部不变性特征提取
图像缩放,平移,旋转都不影响其特征信息,而全连接层很难提取局部不变性特征。
1.1.3 卷积神经网络原理
(1) 卷积层初步提取特征
通过卷积核去乘之后得出值,初步提取特征。卷积层的作用其实就是通过不断的改变卷积核,来确定能初步表征图片特征的有用的卷积核是哪些,再得到与相应的卷积核相乘后的输出矩阵。

(2) 池化层提取主要特征
通过池化层减少训练参数的数量,降低卷积层输出的特征向量的维度。减小过拟合现象,只保留最有用的图片信息,减少噪声的传递。例如卷积层输出是8*8的二维矩阵。把它分成4个2*2的局部矩阵,对局部矩阵进行最大值或者平均值计算,得出一个2*2的矩阵,作为原始图片的特征矩阵。如果池化层的输入单元大小不是二的整数倍,一般采取边缘补零(zero-padding)的方式补成2的倍数,然后再池化。

(3) 全连接层将各部分特征汇总
卷积层和池化层的工作就是提取特征,并减少原始图像带来的参数。全连接层先将二维矩阵转化为1维数组,然后用全连接层进行训练学习,通过前馈误差计算、激活函数、梯度下降法修改参数来提高分类器的准确率。来生成一个等于我们需要的类的数量的分类器。

(4) 产生分类器,进行预测识别
通过训练准确率达到要求之后,就可以用模型去预测分类。
1.1.4 卷积知识点
(1)感受野:后一层中某个区域的值是前面某一层固定区域的输入计算出来的,那这个前一层的固定区域就是后一层该位置的感受野。其实就是卷积核移动经过的地方。

(2)步幅(stride):卷积核计算时每次向右移动和向下移动的长度。
(3)深度(depth) : 顾名思义,它控制输出单元的深度,也就是filter的个数,连接同一块区域的神经元个数。
(4)补零(zero-padding) : 我们可以通过在输入单元周围补零来改变输入单元整体大小,从而控制输出单元的空间大小。例如5*5的输入矩阵,通过3*3的卷积之后,输出是3*3,如果希望通过卷积之后,输出仍然是5*5,则需要输入矩阵周围补0,变成7*7的矩阵。
1.1.5 CNN实现手写数字识别
代码实例
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plot
#(1)定义手写数字数据获取类,用于下载数据和随机获取小批量训练数据
class MNISTLoader():
def __init__(self):
minist = tf.keras.datasets.mnist
#训练数据x_train, 正确值y_train,测试数据x_test,测试数据正确值self.y_test
(self.x_train, self.y_train), (self.x_test, self.y_test) = minist.load_data()
#[60000,28,28,1],60000个28*28像素的图片数据,每个像素点时0-255的整数,除以255.0是将每个像素值归一化为0-1间
#的浮点数,并通过np.expand_dims增加一维,作为颜色通道.默认值为1。
self.x_train = np.expand_dims(self.x_train.astype(np.float) / 255.0, axis=-1)
print(self.x_train.shape)
#[10000,28,28]->[10000,28,28,1]
self.x_test = np.expand_dims(self.x_test.astype(np.float) / 255.0, axis=-1)
#训练用的标签值
self.y_train = self.y_train.astype(np.int)
#测试用的标签值
self.y_test = self.y_test.astype(np.int)
self.num_train_data = self.x_train.shape[0]
self.num_test_data = self.x_test.shape[0]
#随机从数据集中获取大小为batch_size手写图片数据
def get_batch(self, batch_size):
#shape[0]获取数据总数量,在0-总数量之间随机获取数据的索引值,相当于抽样。
index = np.random.randint(0, self.x_train.shape[0], batch_size)
#通过索引值去数据集中获取训练数据集。
return self.x_train[index, :], self.y_train[index]
#(2)定义CNN卷积神经网络模型,继承继承keras.Model,init函数定义层,call函数中组织数据处理流程
class CNN(tf.keras.Model):
def __init__(self):
super(CNN, self).__init__()
#卷积层1
self.conv1 = tf.keras.layers.Conv2D(filters=32,#卷积核数目
kernel_size=[5,5],#感受野大小
padding='same',#矩阵补0使得输入输出大小一致,valid则不补0
activation=tf.nn.relu)#激活函数
#池化层1
self.pool1=tf.keras.layers.MaxPool2D(pool_size=[2,2],strides=2)
#卷积层2
self.conv2 = tf.keras.layers.Conv2D(filters=64, # 卷积核数目
kernel_size=[5, 5], # 感受野大小
padding='same', # 矩阵补0使得输入输出大小一致,valid则不补0
activation=tf.nn.relu) # 激活函数
# 池化层2
self.pool2= tf.keras.layers.MaxPool2D(pool_size=[2, 2], #2*2的感受野
strides=2)#步长为2
# 维度转换,三维7*7*64,转为1维3136
self.flatten = tf.keras.layers.Reshape(target_shape=[7*7*64,])
#全连接层,将3136个像素点转化为1024个
self.dence1 = tf.keras.layers.Dense(units=1024, activation=tf.nn.relu)
#全连接层,将1024个单元转化为10个点
self.dence2 = tf.keras.layers.Dense(units=10) def call(self, inputs, training=None, mask=None):
#编写数据流的处理过程,
x=self.conv1(inputs)#[batch_size,28,28,32]
x=self.pool1(x)#[batch_size,14,14,32]图片大小变为14*14
x=self.conv2(x)#[batch_size,14,14,,64],
x=self.pool2(x)#[batch_size,7,7,64],
x = self.flatten(x)#三维7*7*64数组转化为3136一维数组
x = self.dence1(x)#3136个映射到1024个
x = self.dence2(x)#1024个映射到10个,分别表示对应0,1..9数字的概率
output = tf.nn.softmax(x)#输出0,1..9概率最大的值。
return output #(3)定义训练参数和模型对象,数据集对象
num_epochs = 5
batch_size = 500#一批数据的数量
learning_rate = 0.001#学习率
model = CNN()#创建模型
data_loader = MNISTLoader()#创建数据源对象
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)#创建优化器,用于参数学习优化
#开始训练参数
num_batches=int(data_loader.num_train_data//batch_size*num_epochs)#计算训练数据的总组数
arryindex=np.arange(num_batches)
arryloss=np.zeros(num_batches)
#(4)通过梯度下降法对模型参数进行训练,优化模型
for batch_index in range(num_batches):
X,ylabel=data_loader.get_batch(batch_size)#随机获取训练数据
with tf.GradientTape() as tape:
ypred=model(X)#模型计算预测值
#计算损失函数
loss=tf.keras.losses.sparse_categorical_crossentropy(y_true=ylabel,y_pred=ypred)
#计算损失函数的均方根值,表示误差大小
loss=tf.reduce_mean(loss)
print("第%d次训练后:误差%f" % (batch_index,loss.numpy()))
#保存误差值,用于画图
arryloss[batch_index]=loss
#根据误差计算梯度值
grads=tape.gradient(loss,model.variables)
#将梯度值调整模型参数
optimizer.apply_gradients(grads_and_vars=zip(grads,model.variables)) #画出训练误差随训练次数的图片图
plot.plot(arryindex,arryloss,c='r')
plot.show()
#(5)评估模型的准确性
#建立评估器对象
sparse_categorical_accuracy=tf.keras.metrics.SparseCategoricalAccuracy()
#用测试数据集计算预测值
ytestpred=model.predict(data_loader.x_test)
#向评估器输入预测值和真实值,计算准确率
sparse_categorical_accuracy.update_state(y_true=data_loader.y_test,y_pred=ytestpred)
print("test accuracy is %f" % sparse_categorical_accuracy.result())
训练600次,每次误差随训练次数的变化曲线如下图所示,训练比全连接层要耗时,600次大概需要600秒时间,而多层感知器大概只需要15秒。
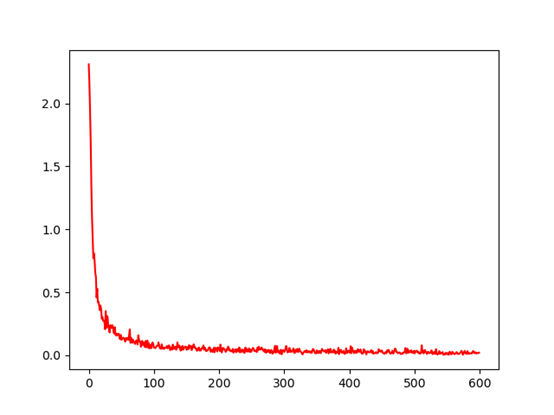
最后几次分析误差已经达到了0.01,以及用测试集上的准确率达到0.99.

1.1.6 MLP和CNN对比
|
属性 |
MLP |
CNN |
|
600次训练时长 |
15秒 |
600秒 |
|
测试集上的准确率 |
0.95 |
0.99 |
|
训练收敛次数 |
350次 |
150次 |
|
测试集最终误差 |
0.08 |
0.01 |
通过对比可知,CNN比MLP,训练收敛更快,误差更小,准确率更好,但是训练时间会更长。
MLP介绍和源码https://www.cnblogs.com/bclshuai/p/14902942.html
4.3CNN卷积神经网络最详细最容易理解--tensorflow源码MLP对比的更多相关文章
- 卷积神经网络CNN介绍:结构框架,源码理解【转】
1. 卷积神经网络结构 卷积神经网络是一个多层的神经网络,每层都是一个变换(映射),常用卷积convention变换和pooling池化变换,每种变换都是对输入数据的一种处理,是输入特征的另一种特征表 ...
- 基于双向BiLstm神经网络的中文分词详解及源码
基于双向BiLstm神经网络的中文分词详解及源码 基于双向BiLstm神经网络的中文分词详解及源码 1 标注序列 2 训练网络 3 Viterbi算法求解最优路径 4 keras代码讲解 最后 源代码 ...
- 『cs231n』卷积神经网络的可视化与进一步理解
cs231n的第18课理解起来很吃力,听后又查了一些资料才算是勉强弄懂,所以这里贴一篇博文(根据自己理解有所修改)和原论文的翻译加深加深理解,其中原论文翻译比博文更容易理解,但是太长,而博文是业者而非 ...
- 【神经网络与深度学习】DCGAN及其TensorFlow源码
上一节我们提到G和D由多层感知机定义.深度学习中对图像处理应用最好的模型是CNN,那么如何把CNN与GAN结合?DCGAN是这方面最好的尝试之一.源码:https://github.com/Newmu ...
- Django对中间件的调用思想、csrf中间件详细介绍、Django settings源码剖析、Django的Auth模块
目录 使用Django对中间件的调用思想完成自己的功能 功能要求 importlib模块介绍 功能的实现 csrf中间件详细介绍 跨站请求伪造 Django csrf中间件 form表单 ajax c ...
- 史上最详细的Android消息机制源码解析
本人只是Android菜鸡一个,写技术文章只是为了总结自己最近学习到的知识,从来不敢为人师,如果里面有不正确的地方请大家尽情指出,谢谢! 606页Android最新面试题含答案,有兴趣可以点击获取. ...
- 卷积神经网络(CNN)的理解与总结
卷积神经网络模型的历史演化: 0. 核心思想 two main ideas: use only local features 在不同位置上使用同样的特征: 池化层的涵义在于,更高的层次能捕捉图像中更大 ...
- [tensorflow源码分析] Conv2d卷积运算 (前向计算,反向梯度计算)
- 人脸检测及识别python实现系列(4)——卷积神经网络(CNN)入门
人脸检测及识别python实现系列(4)——卷积神经网络(CNN)入门 上篇博文我们准备好了2000张训练数据,接下来的几节我们将详细讲述如何利用这些数据训练我们的识别模型.前面说过,原博文给出的训练 ...
随机推荐
- Educational Codeforces Round 101 (Rated for Div. 2)
A. Regular Bracket Sequence 题意:题目中给(和)还有?,其中?可以转换成为()中的任何一个,并且所给样例中只出现一次(),问能不能括号匹配 思路:直接看第一个和最后一个能不 ...
- 03.28,周六,12:00-17:00,ICPC训练联盟周赛,选用试题:UCF Local Programming Contest 2016正式赛。
A. Majestic 10 题意:三个数均大于10则输出"triple-double",如果两个数大于10则输出"double-double",如果一个大于1 ...
- 在Visual Studio 中使用git——文件管理-下(六)
在Visual Studio 中使用git--什么是Git(一) 在Visual Studio 中使用git--给Visual Studio安装 git插件(二) 在Visual Studio 中使用 ...
- 通过Cloudflare开启全站https
Cloudflare 添加域名后,会自动生成通用证书,快速开启全站HTTPS,服务端不用做任何修改,还可以选择多种开启模式 一.注册Cloudflare账号 直接打开网站:https://www.cl ...
- DOM0和DOM2事件的应用和区别详细对比
1.触发次数 零级事件只能注册一次,如果注册多次,后面的会覆盖前面的 btn.onclick = function () { alert(1) } btn.onclick = function () ...
- 探索专有领域的端到端ASR解决之道
摘要:本文从<Shallow-Fusion End-to-End Contextual Biasing>入手,探索解决专有领域的端到端ASR. 本文分享自华为云社区<语境偏移如何解决 ...
- 【二】Kubernetes 集群部署-kubeadm方式(亲测)
一.概述 本次部署 Kubernetes 集群是通过 kubeadm 工具来进行部署, kubeadm 是 Kubernetes 官⽅提供的⽤于快速部署 Kubernetes 集群的⼯具,利⽤其来部署 ...
- envoy 官方example运行失败问题处理
镜像内安装包失败处理 方法一:修改Dockerfile,在Dockerfile中增加如下 ubuntu示例 RUN sed -i 's/archive.ubuntu.com/mirrors.aliyu ...
- Docker Swarm(十)Portainer 集群可视化管理
前言 搭建好我们的容器编排集群,那我们总不能日常的时候也在命令行进行操作,所以我们需要使用到一些可视化的工具,Docker图形化管理提供了很多工具,有Portainer.Docker UI.Shipy ...
- 使用cockpit管理kvm虚拟机
在Centos8.2主机上部署kvm,使用cockpit管理 首先检测cpu是否支持虚拟化 [root@localhost ~]# cat /proc/cpuinfo | grep vmx flags ...