[DB] MapReduce
概述
- 大数据计算的核心思想:移动计算比移动数据更划算
- MapReduce既是一个编程模型,又是一个计算框架
- 包含Map和Reduce两个过程
- 终极目标:用SQL语句分析大数据(Hive、SparkSQL,将SQL语句转换为MR程序)
- 用于解决海量无结构、半结构化数据的批处理问题,例如生成倒排索引、计算网页的pagerank、日志分析等
- 在设计上缺乏针对海量结构化数据进行交互式分析处理的优化考虑
特性
- 序列化
- java序列化:实现序列化接口(标识接口)
Student.java


1 package serializable;
2
3 import java.io.Serializable;
4
5 public class Student implements Serializable{
6 private int stuID;
7 private String stuName;
8 public int getStuID() {
9 return stuID;
10 }
11 public void setStuID(int stuID) {
12 this.stuID = stuID;
13 }
14 public String getStuName() {
15 return stuName;
16 }
17 public void setStuName(String stuName) {
18 this.stuName = stuName;
19 }
20 }
TestMain.java
1 package serializable;
2
3 import java.io.FileOutputStream;
4 import java.io.ObjectOutputStream;
5 import java.io.OutputStream;
6
7 import serializable.Student;
8
9 public class TestMain {
10
11 public static void main(String[] args) throws Exception{
12 // 创建学生对象
13 Student s = new Student();
14 s.setStuID(1);
15 s.setStuName("Tom");
16
17 // 输出对象到文件
18 OutputStream out = new FileOutputStream("F:\\eclipse-workspace\\student.ooo");
19 ObjectOutputStream oos = new ObjectOutputStream(out);
20 oos.writeObject(s);
21
22 oos.close();
23 out.close();
24 }
25 }
- MapReduce序列化:核心接口Writable,实现了Writeble的类的对象可作为MapReduce的key和value
- 读取员工数据,生成员工对象,直接输出到HDFS
- hadoop jar s2.jar /scott/emp.csv /output/0910/s2
- MapReduce序列化:核心接口Writable,实现了Writeble的类的对象可作为MapReduce的key和value
EmpInfoMain.java
1 import org.apache.hadoop.conf.Configuration;
2 import org.apache.hadoop.fs.Path;
3 import org.apache.hadoop.io.IntWritable;
4 import org.apache.hadoop.mapreduce.Job;
5 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
6 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
7
8 public class EmpInfoMain {
9
10 public static void main(String[] args) throws Exception {
11 Job job = Job.getInstance(new Configuration());
12 job.setJarByClass(EmpInfoMain.class);
13
14 job.setMapperClass(EmpInfoMapper.class);
15 job.setMapOutputKeyClass(IntWritable.class);
16 job.setMapOutputValueClass(Emp.class);
17
18 job.setOutputKeyClass(IntWritable.class);
19 job.setOutputKeyClass(Emp.class);
20
21 FileInputFormat.setInputPaths(job, new Path(args[0]));
22 FileOutputFormat.setOutputPath(job, new Path(args[1]));
23
24 job.waitForCompletion(true);
25 }
26 }
EmpInfoMapper.java
1 import java.io.IOException;
2
3 import org.apache.hadoop.io.IntWritable;
4 import org.apache.hadoop.io.LongWritable;
5 import org.apache.hadoop.io.Text;
6 import org.apache.hadoop.mapreduce.Mapper;
7
8 public class EmpInfoMapper extends Mapper<LongWritable, Text, IntWritable, Emp>{
9
10 @Override
11 protected void map(LongWritable key1, Text value1,
12 Context context)
13 throws IOException, InterruptedException {
14 //数据:7654,MARTIN,SALESMAN,7698,1981/9/28,1250,1400,30
15 String data = value1.toString();
16
17 // 分词
18 String[] words = data.split(",");
19
20 // 生成员工对象
21 Emp emp = new Emp();
22 emp.setEmpno(Integer.parseInt(words[0]));
23 emp.setEname(words[1]);
24 emp.setJob(words[2]);
25 emp.setMgr(Integer.parseInt(words[3]));
26 emp.setHiredate(words[4]);
27 emp.setSal(Integer.parseInt(words[5]));
28 emp.setComm(Integer.parseInt(words[6]));
29 emp.setDeptno(Integer.parseInt(words[7]));
30
31 // 输出员工对象
32 context.write(new IntWritable(emp.getEmpno()), emp);
33 }
34 }
Emp.java
1 import java.io.DataInput;
2 import java.io.DataOutput;
3 import java.io.IOException;
4
5 import org.apache.hadoop.io.Writable;
6
7 public class Emp implements Writable{
8 private int empno;
9 private String ename;
10 private String job;
11 private int mgr;
12 private String hiredate;
13 private int sal;
14 private int comm;
15 private int deptno;
16
17 @Override
18 public void readFields(DataInput input)
19 throws IOException {
20 // 实现反序列化,从输入流中读取对象(与输出流顺序一样)
21 this.empno = input.readInt();
22 this.ename = input.readUTF();
23 this.job = input.readUTF();
24 this.mgr = input.readInt();
25 this.hiredate = input.readUTF();
26 this.sal = input.readInt();
27 this.comm = input.readInt();
28 this.deptno = input.readInt();
29 }
30
31 @Override
32 public void write(DataOutput output) throws IOException {
33 // 实现序列化,把对象输出到输出流
34 output.writeInt(this.empno);
35 output.writeUTF(this.ename);
36 output.writeUTF(this.job);
37 output.writeInt(this.mgr);
38 output.writeUTF(this.hiredate);
39 output.writeInt(this.sal);
40 output.writeInt(this.comm);
41 output.writeInt(this.deptno);
42 }
43
44 public int getEmpno() {
45 return empno;
46 }
47
48 public void setEmpno(int empno) {
49 this.empno = empno;
50 }
51
52 public String getEname() {
53 return ename;
54 }
55
56 public void setEname(String ename) {
57 this.ename = ename;
58 }
59
60 public String getJob() {
61 return job;
62 }
63
64 public void setJob(String job) {
65 this.job = job;
66 }
67
68 public int getMgr() {
69 return mgr;
70 }
71
72 public void setMgr(int mgr) {
73 this.mgr = mgr;
74 }
75
76 public String getHiredate() {
77 return hiredate;
78 }
79
80 public void setHiredate(String hiredate) {
81 this.hiredate = hiredate;
82 }
83
84 public int getSal() {
85 return sal;
86 }
87
88 public void setSal(int sal) {
89 this.sal = sal;
90 }
91
92 public int getComm() {
93 return comm;
94 }
95
96 public void setComm(int comm) {
97 this.comm = comm;
98 }
99
100 public int getDeptno() {
101 return deptno;
102 }
103
104 public void setDeptno(int deptno) {
105 this.deptno = deptno;
106 }
107
108 @Override
109 public String toString() {
110 return "Emp [empno=" + empno + ", ename=" + ename
111 + ", sal=" + sal + ", deptno=" + deptno
112 + "]";
113 }
114
115 }

- 求部门工资总额
- 由于实现了序列化接口,员工可作为key和value
- 相比之前的程序更加简洁
- 对于大对象可能产生性能问题
- 求部门工资总额
EmpInfoMain.java
1 import org.apache.hadoop.conf.Configuration;
2 import org.apache.hadoop.fs.Path;
3 import org.apache.hadoop.io.IntWritable;
4 import org.apache.hadoop.mapreduce.Job;
5 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
6 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
7
8 public class EmpInfoMain {
9
10 public static void main(String[] args) throws Exception {
11 Job job = Job.getInstance(new Configuration());
12 job.setJarByClass(EmpInfoMain.class);
13
14 job.setMapperClass(EmpInfoMapper.class);
15 job.setMapOutputKeyClass(IntWritable.class);
16 job.setMapOutputValueClass(Emp.class); // 输出就是员工对象
17
18 job.setOutputKeyClass(IntWritable.class);
19 job.setOutputValueClass(Emp.class);
20
21 FileInputFormat.setInputPaths(job, new Path(args[0]));
22 FileOutputFormat.setOutputPath(job, new Path(args[1]));
23
24 job.waitForCompletion(true);
25 }
26
27 }
SalaryTotalMapper.java
1 import java.io.IOException;
2 import org.apache.hadoop.io.IntWritable;
3 import org.apache.hadoop.io.LongWritable;
4 import org.apache.hadoop.io.Text;
5 import org.apache.hadoop.mapreduce.Mapper;
6
7 // k2:部门号 v2:员工对象
8 public class SalaryTotalMapper extends Mapper<LongWritable, Text, IntWritable, Emp> {
9
10 @Override
11 protected void map(LongWritable key1, Text value1, Context context)
12 throws IOException, InterruptedException {
13 // 数据:7654,MARTIN,SALESMAN,7698,1981/9/28,1250,1400,30
14 String data = value1.toString();
15
16 // 分词
17 String[] words = data.split(",");
18
19 // 生成员工对象
20 Emp emp = new Emp();
21 emp.setEmpno(Integer.parseInt(words[0]));
22 emp.setEname(words[1]);
23 emp.setJob(words[2]);
24 emp.setMgr(Integer.parseInt(words[3]));
25 emp.setHiredate(words[4]);
26 emp.setSal(Integer.parseInt(words[5]));
27 emp.setComm(Integer.parseInt(words[6]));
28 emp.setDeptno(Integer.parseInt(words[7]));
29
30 // 输出员工对象 k2:部门号 v2:员工对象
31 context.write(new IntWritable(emp.getDeptno()), emp);
32 }
33 }
SalaryTotalReducer.java
1 import java.io.IOException;
2 import org.apache.hadoop.io.IntWritable;
3 import org.apache.hadoop.mapreduce.Reducer;
4
5 public class SalaryTotalReducer extends Reducer<IntWritable, Emp, IntWritable, IntWritable> {
6
7 @Override
8 protected void reduce(IntWritable k3, Iterable<Emp> v3,Context context) throws IOException, InterruptedException {
9 int total = 0;
10
11 //取出员工薪水,并求和
12 for(Emp e:v3){
13 total = total + e.getSal();
14 }
15 context.write(k3, new IntWritable(total));
16 }
17 }
- 排序
- 规则:按照Key2排序
- 基本数据类型
- 数字:默认升序
- 自定义比较器:MyNumberComparator.java
- 主程序中添加比较器:job.setSortComparatorClass(MyNumberCompatator.class)
- 数字:默认升序
MyNumberComparator.java
1 import org.apache.hadoop.io.IntWritable;
2
3 //针对数字创建自己的比较规则,执行降序排序
4 public class MyNumberComparator extends IntWritable.Comparator {
5
6 @Override
7 public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
8 // TODO Auto-generated method stub
9 return -super.compare(b1, s1, l1, b2, s2, l2);
10 }
11 }
- 字符串:默认字典顺序
MyTextComparator.java
1 import org.apache.hadoop.io.Text;
2
3 // 针对Text定义比较规则
4 public class MyTextComparator extends Text.Comparator{
5
6 @Override
7 public int compare(byte[] b1, int s1, int l1, byte[] b2,
8 int s2, int l2) {
9 return -super.compare(b1, s1, l1, b2, s2, l2);
10 }
11 }
- 对象
- SQL排序:order by + 列名 / 表达式 / 列的别名 / 序号 / 多个列(desc作用于最近一列)
- 前提:对象必须是Key2;必须实现Writable接口;必须是可排序对象(类似Java对象排序,要实现Comparable<T>)
- 对象
Student.java
1 //学生对象:按照学生的age年龄进行排序
2 public class Student implements Comparable<Student>{
3
4 private int stuID;
5 private String stuName;
6 private int age;
7
8 @Override
9 public String toString() {
10 return "Student [stuID=" + stuID + ", stuName=" + stuName + ", age=" + age + "]";
11 }
12
13 @Override
14 public int compareTo(Student o) {
15 // 定义排序规则:按照学生的age年龄进行排序
16 if(this.age >= o.getAge()){
17 return 1;
18 }else{
19 return -1;
20 }
21 }
22
23 public int getStuID() {
24 return stuID;
25 }
26 public void setStuID(int stuID) {
27 this.stuID = stuID;
28 }
29 public String getStuName() {
30 return stuName;
31 }
32 public void setStuName(String stuName) {
33 this.stuName = stuName;
34 }
35 public int getAge() {
36 return age;
37 }
38 public void setAge(int age) {
39 this.age = age;
40 }
41
42 }
StudentMain.java
1 import java.util.Arrays;
2
3 public class StudentMain {
4
5 public static void main(String[] args) {
6 //创建几个学生对象
7 Student s1 = new Student();
8 s1.setStuID(1);
9 s1.setStuName("Tom");
10 s1.setAge(24);
11
12 Student s2 = new Student();
13 s2.setStuID(2);
14 s2.setStuName("Mary");
15 s2.setAge(26);
16
17 Student s3 = new Student();
18 s3.setStuID(3);
19 s3.setStuName("Mike");
20 s3.setAge(25);
21
22 //生成一个数组
23 Student[] list = {s1,s2,s3};
24
25 //排序
26 Arrays.sort(list);
27
28 //输出
29 for(Student s:list){
30 System.out.println(s);
31 }
32 }
33 }
- 一个/多个列排序
Emp.java
1 import java.io.DataInput;
2 import java.io.DataOutput;
3 import java.io.IOException;
4
5 import org.apache.hadoop.io.Writable;
6 import org.apache.hadoop.io.WritableComparable;
7
8 //代表员工
9 //数据:7654,MARTIN,SALESMAN,7698,1981/9/28,1250,1400,30
10 public class Emp implements WritableComparable<Emp>{
11
12 private int empno;//员工号
13 private String ename; //员工姓名
14 private String job; //职位
15 private int mgr; //经理的员工号
16 private String hiredate;//入职日期
17 private int sal; //月薪
18 private int comm; //奖金
19 private int deptno; //部门号
20
21 // @Override
22 // public int compareTo(Emp o) {
23 // // 定义自己的排序规则:一个列的排序
24 // // 按照薪水进行排序
25 // if(this.sal >= o.getSal()){
26 // return 1;
27 // }else{
28 // return -1;
29 // }
30 // }
31
32 @Override
33 public int compareTo(Emp o) {
34 // 定义自己的排序规则:多个列的排序
35 // 先按照部门号进行排序,再按照薪水进行排序
36 if(this.deptno > o.getDeptno()){
37 return 1;
38 }else if(this.deptno < o.getDeptno()){
39 return -1;
40 }
41
42 //再按照薪水进行排序
43 if(this.sal >= o.getSal()){
44 return 1;
45 }else{
46 return -1;
47 }
48 }
49
50 @Override
51 public String toString() {
52 return "Emp [empno=" + empno + ", ename=" + ename + ", sal=" + sal + ", deptno=" + deptno + "]";
53 }
54
55 @Override
56 public void readFields(DataInput input) throws IOException {
57 //实现反序列化,从输入流中读取对象
58 this.empno = input.readInt();
59 this.ename = input.readUTF();
60 this.job = input.readUTF();
61 this.mgr = input.readInt();
62 this.hiredate = input.readUTF();
63 this.sal = input.readInt();
64 this.comm = input.readInt();
65 this.deptno = input.readInt();
66 }
67
68 @Override
69 public void write(DataOutput output) throws IOException {
70 // 实现序列化,把对象输出到输出流
71 output.writeInt(this.empno);
72 output.writeUTF(this.ename);
73 output.writeUTF(this.job);
74 output.writeInt(this.mgr);
75 output.writeUTF(this.hiredate);
76 output.writeInt(this.sal);
77 output.writeInt(this.comm);
78 output.writeInt(this.deptno);
79 }
80
81
82 public int getEmpno() {
83 return empno;
84 }
85 public void setEmpno(int empno) {
86 this.empno = empno;
87 }
88 public String getEname() {
89 return ename;
90 }
91 public void setEname(String ename) {
92 this.ename = ename;
93 }
94 public String getJob() {
95 return job;
96 }
97 public void setJob(String job) {
98 this.job = job;
99 }
100 public int getMgr() {
101 return mgr;
102 }
103 public void setMgr(int mgr) {
104 this.mgr = mgr;
105 }
106 public String getHiredate() {
107 return hiredate;
108 }
109 public void setHiredate(String hiredate) {
110 this.hiredate = hiredate;
111 }
112 public int getSal() {
113 return sal;
114 }
115 public void setSal(int sal) {
116 this.sal = sal;
117 }
118 public int getComm() {
119 return comm;
120 }
121 public void setComm(int comm) {
122 this.comm = comm;
123 }
124 public int getDeptno() {
125 return deptno;
126 }
127 public void setDeptno(int deptno) {
128 this.deptno = deptno;
129 }
130
131 }
EmpSortMapper.java
1 import java.io.IOException;
2
3 import org.apache.hadoop.io.IntWritable;
4 import org.apache.hadoop.io.LongWritable;
5 import org.apache.hadoop.io.NullWritable;
6 import org.apache.hadoop.io.Text;
7 import org.apache.hadoop.mapreduce.Mapper;
8
9 /*
10 * 一定要把Emp作为key2
11 * 没有value2,返回null值
12 */
13
14 public class EmpSortMapper extends Mapper<LongWritable, Text, Emp, NullWritable> {
15
16 @Override
17 protected void map(LongWritable key1, Text value1, Context context)
18 throws IOException, InterruptedException {
19 // 数据:7654,MARTIN,SALESMAN,7698,1981/9/28,1250,1400,30
20 String data = value1.toString();
21
22 //分词
23 String[] words = data.split(",");
24
25 //生成员工对象
26 Emp emp = new Emp();
27 emp.setEmpno(Integer.parseInt(words[0]));
28 emp.setEname(words[1]);
29 emp.setJob(words[2]);
30 emp.setMgr(Integer.parseInt(words[3]));
31 emp.setHiredate(words[4]);
32 emp.setSal(Integer.parseInt(words[5]));
33 emp.setComm(Integer.parseInt(words[6]));
34 emp.setDeptno(Integer.parseInt(words[7]));
35
36 //输出员工对象 k2:员工对象 v2:空值
37 context.write(emp, NullWritable.get());
38 }
39 }
EmpSortMain.java
1 import java.io.IOException;
2
3 import org.apache.hadoop.conf.Configuration;
4 import org.apache.hadoop.fs.Path;
5 import org.apache.hadoop.io.IntWritable;
6 import org.apache.hadoop.io.NullWritable;
7 import org.apache.hadoop.mapreduce.Job;
8 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
9 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
10
11 public class EmpSortMain {
12
13 public static void main(String[] args) throws Exception {
14 Job job = Job.getInstance(new Configuration());
15 job.setJarByClass(EmpSortMain.class);
16
17 job.setMapperClass(EmpSortMapper.class);
18 job.setMapOutputKeyClass(Emp.class); //k2 是员工对象
19 job.setMapOutputValueClass(NullWritable.class); // v2:是空值
20
21 job.setOutputKeyClass(Emp.class);
22 job.setOutputValueClass(NullWritable.class);
23
24 FileInputFormat.setInputPaths(job, new Path(args[0]));
25 FileOutputFormat.setOutputPath(job, new Path(args[1]));
26
27 job.waitForCompletion(true);
28
29 }
30
31 }
- 分区(Partition)
- 关系型数据库分区
- 分区1:sal<=3000,分区2:3000<sal<=5000,分区3:sal>5000
- 查询薪水1000~2000的员工,只扫描分区1即可
- Hash分区:根据数值的Hash结果进行分区,如果一样就放入同一个分区中(数据尽量打散,避免热块)
- Redis Cluster、Hive 桶表、MongoDB 分布式路由
- MR分区
- 根据Map的输出<key2 value2>进行分区
- 默认情况下,MR的输出只有一个分区(一个分区就是一个文件)
- 按部门号分区:不同部门的员工放到不同文件中
- 关系型数据库分区
Emp.java
1 import java.io.DataInput;
2 import java.io.DataOutput;
3 import java.io.IOException;
4
5 import org.apache.hadoop.io.Writable;
6
7 //代表员工
8 //数据:7654,MARTIN,SALESMAN,7698,1981/9/28,1250,1400,30
9 public class Emp implements Writable{
10
11 private int empno;//员工号
12 private String ename; //员工姓名
13 private String job; //职位
14 private int mgr; //经理的员工号
15 private String hiredate;//入职日期
16 private int sal; //月薪
17 private int comm; //奖金
18 private int deptno; //部门号
19
20
21 @Override
22 public String toString() {
23 return "Emp [empno=" + empno + ", ename=" + ename + ", sal=" + sal + ", deptno=" + deptno + "]";
24 }
25
26 @Override
27 public void readFields(DataInput input) throws IOException {
28 //实现反序列化,从输入流中读取对象
29 this.empno = input.readInt();
30 this.ename = input.readUTF();
31 this.job = input.readUTF();
32 this.mgr = input.readInt();
33 this.hiredate = input.readUTF();
34 this.sal = input.readInt();
35 this.comm = input.readInt();
36 this.deptno = input.readInt();
37 }
38
39 @Override
40 public void write(DataOutput output) throws IOException {
41 // 实现序列化,把对象输出到输出流
42 output.writeInt(this.empno);
43 output.writeUTF(this.ename);
44 output.writeUTF(this.job);
45 output.writeInt(this.mgr);
46 output.writeUTF(this.hiredate);
47 output.writeInt(this.sal);
48 output.writeInt(this.comm);
49 output.writeInt(this.deptno);
50 }
51
52
53 public int getEmpno() {
54 return empno;
55 }
56 public void setEmpno(int empno) {
57 this.empno = empno;
58 }
59 public String getEname() {
60 return ename;
61 }
62 public void setEname(String ename) {
63 this.ename = ename;
64 }
65 public String getJob() {
66 return job;
67 }
68 public void setJob(String job) {
69 this.job = job;
70 }
71 public int getMgr() {
72 return mgr;
73 }
74 public void setMgr(int mgr) {
75 this.mgr = mgr;
76 }
77 public String getHiredate() {
78 return hiredate;
79 }
80 public void setHiredate(String hiredate) {
81 this.hiredate = hiredate;
82 }
83 public int getSal() {
84 return sal;
85 }
86 public void setSal(int sal) {
87 this.sal = sal;
88 }
89 public int getComm() {
90 return comm;
91 }
92 public void setComm(int comm) {
93 this.comm = comm;
94 }
95 public int getDeptno() {
96 return deptno;
97 }
98 public void setDeptno(int deptno) {
99 this.deptno = deptno;
100 }
101 }
MyPartitionerMain.java
1 import java.io.IOException;
2
3 import org.apache.hadoop.conf.Configuration;
4 import org.apache.hadoop.fs.Path;
5 import org.apache.hadoop.io.IntWritable;
6 import org.apache.hadoop.mapreduce.Job;
7 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
8 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
9
10 public class MyPartitionerMain {
11
12 public static void main(String[] args) throws Exception {
13 Job job = Job.getInstance(new Configuration());
14 job.setJarByClass(MyPartitionerMain.class);
15
16 job.setMapperClass(MyPartitionerMapper.class);
17 job.setMapOutputKeyClass(IntWritable.class); //k2 是部门号
18 job.setMapOutputValueClass(Emp.class); // v2输出就是员工对象
19
20 //加入分区规则
21 job.setPartitionerClass(MyPartitioner.class);
22 //指定分区的个数
23 job.setNumReduceTasks(3);
24
25 job.setReducerClass(MyPartitionerReducer.class);
26 job.setOutputKeyClass(IntWritable.class);
27 job.setOutputValueClass(Emp.class);
28
29 FileInputFormat.setInputPaths(job, new Path(args[0]));
30 FileOutputFormat.setOutputPath(job, new Path(args[1]));
31
32 job.waitForCompletion(true);
33 }
34 }
MyPartitionerMapper.java
1 import java.io.IOException;
2
3 import org.apache.hadoop.io.IntWritable;
4 import org.apache.hadoop.io.LongWritable;
5 import org.apache.hadoop.io.Text;
6 import org.apache.hadoop.mapreduce.Mapper;
7
8 // k2 部门号 v2 员工
9 public class MyPartitionerMapper extends Mapper<LongWritable, Text, IntWritable, Emp> {
10
11 @Override
12 protected void map(LongWritable key1, Text value1, Context context)
13 throws IOException, InterruptedException {
14 // 数据:7654,MARTIN,SALESMAN,7698,1981/9/28,1250,1400,30
15 String data = value1.toString();
16
17 //分词
18 String[] words = data.split(",");
19
20 //生成员工对象
21 Emp emp = new Emp();
22 emp.setEmpno(Integer.parseInt(words[0]));
23 emp.setEname(words[1]);
24 emp.setJob(words[2]);
25 emp.setMgr(Integer.parseInt(words[3]));
26 emp.setHiredate(words[4]);
27 emp.setSal(Integer.parseInt(words[5]));
28 emp.setComm(Integer.parseInt(words[6]));
29 emp.setDeptno(Integer.parseInt(words[7]));
30
31 //输出员工对象 k2:部门号 v2:员工对象
32 context.write(new IntWritable(emp.getDeptno()), emp);
33 }
34 }
MyPartitionerReducer.java
1 import java.io.IOException;
2
3 import org.apache.hadoop.io.IntWritable;
4 import org.apache.hadoop.mapreduce.Reducer;
5
6 //就是同一个部门的员工
7 public class MyPartitionerReducer extends Reducer<IntWritable, Emp, IntWritable, Emp> {
8
9 @Override
10 protected void reduce(IntWritable k3, Iterable<Emp> v3,Context context) throws IOException, InterruptedException {
11 // 直接输出
12 for(Emp e:v3){
13 context.write(k3, e);
14 }
15 }
16 }
- 合并(Combiner)
- 一种特殊的Reducer,部署在Mapper端
- 在Mapper端执行一次合并,用于减少Mapper输出到Reducer的数据量,提高效率
- 在wordCountMain.java中添加job.setCombinerClass(WordCountReducer.class)
- 谨慎使用Combiner,有些情况不能使用(如求平均值)
- 不管有没有Combiner,都不能改变Map和Reduce对应的数据类型
- 程序出错,可将Reducer的k3 类型改为DoubleWritable
AvgSalaryMain.java
1 import java.io.IOException;
2
3 import org.apache.hadoop.conf.Configuration;
4 import org.apache.hadoop.fs.Path;
5 import org.apache.hadoop.io.DoubleWritable;
6 import org.apache.hadoop.io.IntWritable;
7 import org.apache.hadoop.io.Text;
8 import org.apache.hadoop.mapreduce.Job;
9 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
10 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
11
12 public class AvgSalaryMain {
13
14 public static void main(String[] args) throws Exception {
15 //1、创建任务、指定任务的入口
16 Job job = Job.getInstance(new Configuration());
17 job.setJarByClass(AvgSalaryMain.class);
18
19 //2、指定任务的map和map输出的数据类型
20 job.setMapperClass(AvgSalaryMapper.class);
21 job.setMapOutputKeyClass(Text.class);
22 job.setMapOutputValueClass(IntWritable.class);
23
24 //加入Combiner
25 job.setCombinerClass(AvgSalaryReducer.class);
26
27 //3、指定任务的reducer和reducer输出的类型
28 job.setReducerClass(AvgSalaryReducer.class);
29 job.setOutputKeyClass(Text.class);
30 job.setOutputValueClass(DoubleWritable.class);
31
32 //4、指定任务输入路径和输出路径
33 FileInputFormat.setInputPaths(job, new Path(args[0]));
34 FileOutputFormat.setOutputPath(job, new Path(args[1]));
35
36 //5、执行任务
37 job.waitForCompletion(true);
38
39 }
40 }
AvgSalaryMapper.java
1 import java.io.IOException;
2
3 import org.apache.hadoop.io.IntWritable;
4 import org.apache.hadoop.io.LongWritable;
5 import org.apache.hadoop.io.Text;
6 import org.apache.hadoop.mapreduce.Mapper;
7
8 // k2 常量 v2:薪水
9 public class AvgSalaryMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
10
11 @Override
12 protected void map(LongWritable key1, Text value1, Context context)
13 throws IOException, InterruptedException {
14 // 数据:7654,MARTIN,SALESMAN,7698,1981/9/28,1250,1400,30
15 String data = value1.toString();
16
17 //分词
18 String[] words = data.split(",");
19
20 //输出 k2 常量 v2 薪水
21 context.write(new Text("salary"), new IntWritable(Integer.parseInt(words[5])));
22 }
23 }
AvgSalaryReducer.java
1 import java.io.IOException;
2
3 import org.apache.hadoop.io.DoubleWritable;
4 import org.apache.hadoop.io.IntWritable;
5 import org.apache.hadoop.io.Text;
6 import org.apache.hadoop.mapreduce.Reducer;
7
8 // v4:平均工资
9 public class AvgSalaryReducer extends Reducer<Text, IntWritable, Text, DoubleWritable> {
10
11 @Override
12 protected void reduce(Text k3, Iterable<IntWritable> v3,Context context) throws IOException, InterruptedException {
13 int total = 0;
14 int count = 0;
15
16 for(IntWritable salary:v3){
17 //工资求和
18 total = total + salary.get();
19 //人数加一
20 count ++;
21 }
22
23 //输出
24 context.write(new Text("The avg salary is :"), new DoubleWritable(total/count));
25 }
26
27 }

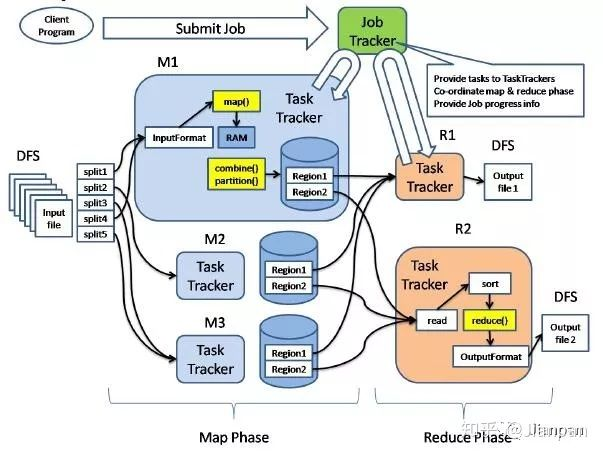
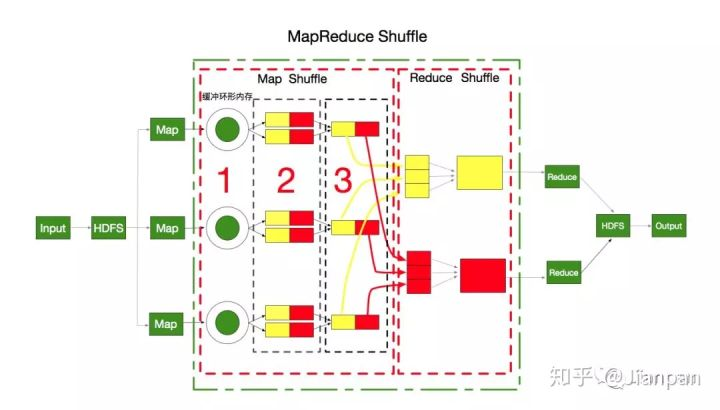
Shuffle
- MapReduce的核心
- map输出后到reduce接收前
- Hadoop 3.x以前: 会有数据落地(I/O操作)
- Spark只有两次I/O操作(读+写),中间运算在内存中完成
Yarn
- MapReduce 2.0 后运行在Yarn上
- 默认NodeManager和DataNode在一台机器上

MRUnit
- 类似JUnit
- 添加相应jar包,去掉mockito-all-1.8.5.jar
- 用Hadoop在windows上的安装包设置环境变量
WordCountMapper.java
1 import java.io.IOException;
2
3 import org.apache.hadoop.io.IntWritable;
4 import org.apache.hadoop.io.LongWritable;
5 import org.apache.hadoop.io.Text;
6 import org.apache.hadoop.mapreduce.Mapper;
7
8 //实现Map的功能
9 // k1 v1 k2 v2
10 public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
11
12 @Override
13 protected void map(LongWritable key1, Text value1, Context context)
14 throws IOException, InterruptedException {
15 /*
16 * context: map的上下文
17 * 上文:HDFS
18 * 下文:Reducer
19 */
20 //得到数据 I love Beijing
21 String data = value1.toString();
22
23 //分词
24 String[] words = data.split(" ");
25
26 //输出 k2 v2
27 for(String w:words){
28 // k2 v2
29 context.write(new Text(w), new IntWritable(1));
30 }
31 }
32 }
WordCountReducer.java
1 import java.io.IOException;
2
3 import org.apache.hadoop.io.IntWritable;
4 import org.apache.hadoop.io.Text;
5 import org.apache.hadoop.mapreduce.Reducer;
6
7 //实现Reducer的功能
8 // k3 v3 k4 v4
9 public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
10
11 @Override
12 protected void reduce(Text k3, Iterable<IntWritable> v3,Context context) throws IOException, InterruptedException {
13 /*
14 * context是Reducer的上下文
15 * 上文:Map
16 * 下文:HDFS
17 */
18 int total = 0;
19 for(IntWritable v:v3){
20 //求和
21 total = total + v.get();
22 }
23
24 //输出 k4 v4
25 context.write(k3, new IntWritable(total));
26 }
27 }
WordCountUnitTest.java
1 import java.util.ArrayList;
2 import java.util.List;
3
4 import org.apache.hadoop.io.IntWritable;
5 import org.apache.hadoop.io.LongWritable;
6 import org.apache.hadoop.io.Text;
7 import org.apache.hadoop.mrunit.mapreduce.MapDriver;
8 import org.apache.hadoop.mrunit.mapreduce.MapReduceDriver;
9 import org.apache.hadoop.mrunit.mapreduce.ReduceDriver;
10 import org.junit.Test;
11
12 public class WordCountUnitTest {
13
14 @Test
15 public void testMapper() throws Exception{
16 /*
17 * java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries
18 * 设置环境变量就可以,用到Hadoop在windows上的安装包
19 */
20 System.setProperty("hadoop.home.dir", "E:\\tools\\hadoop-common-2.2.0-bin-master");
21
22 //创建一个Map的对象:测试对象
23 WordCountMapper mapper = new WordCountMapper();
24
25 //创建一个MapDriver进行单元测试
26 MapDriver<LongWritable, Text, Text, IntWritable> driver = new MapDriver<>(mapper);
27
28 //指定map的输入:k1 v1
29 driver.withInput(new LongWritable(1), new Text("I love Beijing"));
30
31 //指定map的输出: k2 v2 ------> 我们期望得到结果
32 driver.withOutput(new Text("I"), new IntWritable(1))
33 .withOutput(new Text("love"), new IntWritable(1))
34 .withOutput(new Text("Beijing"), new IntWritable(1));
35
36 //执行单元测试:对比 期望的结果 和 实际的结果
37 driver.runTest();
38 }
39
40 @Test
41 public void testReducer() throws Exception{
42 System.setProperty("hadoop.home.dir", "D:\\temp\\hadoop-2.4.1\\hadoop-2.4.1");
43
44 //创建一个测试对象
45 WordCountReducer reducer = new WordCountReducer();
46
47 // 创建一个Driver
48 ReduceDriver<Text, IntWritable, Text, IntWritable> driver = new ReduceDriver<>(reducer);
49
50 //指定Driver的输入:k3 v3
51 //构造一下v3 是一个集合
52 List<IntWritable> value3 = new ArrayList<>();
53 value3.add(new IntWritable(1));
54 value3.add(new IntWritable(1));
55 value3.add(new IntWritable(1));
56
57 driver.withInput(new Text("Beijing"), value3);
58
59 //指定输出的数据 指定 k4 v4
60 driver.withOutput(new Text("Beijing"), new IntWritable(3));
61
62 //执行单元测试
63 driver.runTest();
64 }
65
66 @Test
67 public void testJob() throws Exception{
68 System.setProperty("hadoop.home.dir", "D:\\temp\\hadoop-2.4.1\\hadoop-2.4.1");
69
70 //创建测试的对象
71 WordCountMapper mapper = new WordCountMapper();
72 WordCountReducer reducer = new WordCountReducer();
73
74 //创建一个Driver
75 //MapReduceDriver<K1, V1, K2, V2, K4, V4>
76 MapReduceDriver<LongWritable, Text, Text, IntWritable,Text, IntWritable>
77 driver = new MapReduceDriver<>(mapper,reducer);
78
79 //指定Map的输入
80 driver.withInput(new LongWritable(1), new Text("I love Beijing"))
81 .withInput(new LongWritable(4), new Text("I love China"))
82 .withInput(new LongWritable(6), new Text("Beijing is the capital of China"));
83
84 //指定Reducer的输出
85 driver.withOutput(new Text("Beijing"), new IntWritable(2))
86 .withOutput(new Text("China"), new IntWritable(2))
87 .withOutput(new Text("I"), new IntWritable(2))
88 .withOutput(new Text("capital"), new IntWritable(1))
89 .withOutput(new Text("is"), new IntWritable(1))
90 .withOutput(new Text("love"), new IntWritable(2))
91 .withOutput(new Text("of"), new IntWritable(1))
92 .withOutput(new Text("the"), new IntWritable(1));
93
94 driver.runTest();
95 }
96 }
参考
Hadoop 新 MapReduce 框架 Yarn 详解
https://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-yarn/
基于MapReduce模型的范围查询分析优化技术研究
https://www.doc88.com/p-7708885315214.html
[DB] MapReduce的更多相关文章
- [DB] MapReduce 例题
词频统计(word count) 一篇文章用哈希表统计即可 对互联网所有网页的词频进行统计(Google搜索引擎的需求),无法将所有网页读入内存 map:将单词提取出来,对每个单词输入一个<wo ...
- Hadoop 中利用 mapreduce 读写 mysql 数据
Hadoop 中利用 mapreduce 读写 mysql 数据 有时候我们在项目中会遇到输入结果集很大,但是输出结果很小,比如一些 pv.uv 数据,然后为了实时查询的需求,或者一些 OLAP ...
- MapReduce
2016-12-21 16:53:49 mapred-default.xml mapreduce.input.fileinputformat.split.minsize 0 The minimum ...
- 在MongoDB的MapReduce上踩过的坑
太久没动这里,目前人生处于一个新的开始.这次博客的内容很久前就想更新上来,但是一直没找到合适的时间点(哈哈,其实就是懒),主要内容集中在使用Mongodb时的一些隐蔽的MapReduce问题: 1.R ...
- MongoDB进行MapReduce的数据类型
有很长一段时间没更新博客了,因为最近都比较忙,今天算是有点空闲吧.本文主要是介绍MapReduce在MongoDB上的使用,它与sql的分组.聚集类似,也是先map分组,再用reduce统计,最后还可 ...
- MongoDB聚合运算之mapReduce函数的使用(11)
mapReduce 随着"大数据"概念而流行. 其实mapReduce的概念非常简单, 从功能上说,相当于RDBMS的 group 操作 mapReduce的真正强项在哪? 答:在 ...
- mongo DB的一般操作
最近接触了一些mongoDB .将一些指令操作记录下来,便于查询和使用 登录 [root@logs ~]# mongo -u loguser -p log123456 --authentication ...
- Sqoop:Could not load db driver class: com.microsoft.sqlserver.jdbc.SQLServerDriver
Sqoop version:1.4.6-cdh Hadoop version:2.6.0-cdh5.8.2 场景:使用Sqoop从MSSqlserver导数据 虽然1.4.6的官网说 Even if ...
- mapreduce导出MSSQL的数据到HDFS
今天想通过一些数据,来测试一下我的<基于信息熵的无字典分词算法>这篇文章的正确性.就写了一下MapReduce程序从MSSQL SERVER2008数据库里取数据分析.程序发布到hadoo ...
随机推荐
- 开源一个比雪花算法更好用的ID生成算法(雪花漂移)
比雪花算法更好用的ID生成算法(单机或分布式唯一ID) 转载及版权声明 本人从未在博客园之外的网站,发表过本算法长文,其它网站所现文章,均属他人拷贝之作. 所有拷贝之作,均须保留项目开源链接,否则禁止 ...
- 「HTML+CSS」--自定义加载动画【010】
前言 Hello!小伙伴! 首先非常感谢您阅读海轰的文章,倘若文中有错误的地方,欢迎您指出- 哈哈 自我介绍一下 昵称:海轰 标签:程序猿一只|C++选手|学生 简介:因C语言结识编程,随后转入计算机 ...
- Vulkan移植GpuImage(三)从A到C的滤镜
前面移植了几个比较复杂的效果后,算是确认了复杂滤镜不会对框架造成比较大的改动,开始从头移植,现已把A到C的所有滤镜用vulkan的ComputeShader实现了,讲一些其中实现的过程. Averag ...
- addeventlistener回调函数中的黑科技
dom.addEventListener('click',callback/obj){},这里的callback除了传递一个函数之外,还可以传递一个属性带有 HandleEvent 方法的对象obj, ...
- 004-Java中的运算符
@ 目录 一.运算符 一.分类 二.算数运算符 三.关系运算符 四.逻辑运算符 五.赋值运算符 六.条件运算符(三目运算符) 七.+运算符 一.运算符 一.分类 二.算数运算符 加 $+$ 减 $ ...
- k8s集群移除node
先drain节点上的pod 使用kubectl drain node03 --delete-local-data --force --ignore-daemonsets 之后删除node [root@ ...
- 漫谈SCA(软件成分分析)测试技术:原理、工具与准确性
摘要:本文介绍了SCA技术的基本原理.应用场景,业界TOP SCA商用工具的分析说明以及技术发展趋势:让读者对SCA技术有一个基本初步的了解,能更好的准确的应用SCA工具来发现应用软件中一些安全问题, ...
- 976. Largest Perimeter Triangle
Given an array A of positive lengths, return the largest perimeter of a triangle with non-zero area, ...
- PHP版DES算法加密数据
php7之后的版本 php的mcrypt 扩展已经过时了大约10年,并且用起来很复杂.因此它被废弃并且被 OpenSSL 所取代. 从PHP 7.2起它将被从核心代码中移除并且移到PECL中.PHP手 ...
- php与mysql 绑定变量和预定义处理
非select 语句(没有结果集的) 1.建立连接数据库 $mysqli=new mysqli("localhost","root","", ...