机器学习之路:python 特征降维 特征筛选 feature_selection
特征提取:
特征降维的手段
抛弃对结果没有联系的特征
抛弃对结果联系较少的特征
以这种方式,降低维度 数据集的特征过多,有些对结果没有任何关系,
这个时候,将没有关系的特征删除,反而能获得更好的预测结果 下面使用决策树,预测泰坦尼克号幸存情况,
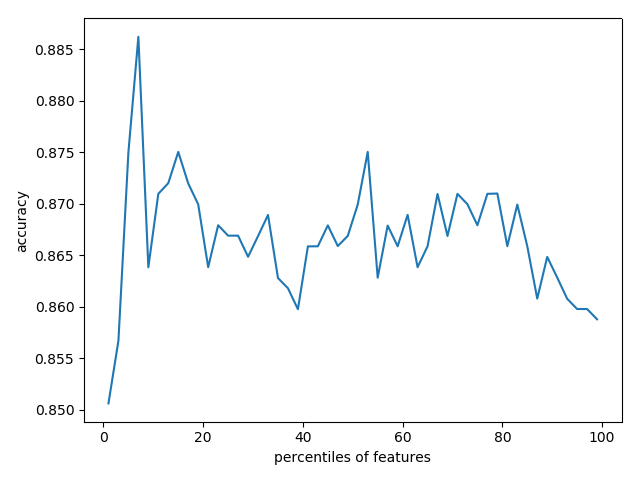
对不同百分比的筛选特征,进行学习和预测,比较准确率
python3学习使用api
使用到联网的数据集,我已经下载到本地,可以到我的git中下载数据集
git: https://github.com/linyi0604/MachineLearning
代码:
import pandas as pd
from sklearn.cross_validation import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.tree import DecisionTreeClassifier
from sklearn import feature_selection
from sklearn.cross_validation import cross_val_score
import numpy as np
import pylab as pl '''
特征提取:
特征降维的手段
抛弃对结果没有联系的特征
抛弃对结果联系较少的特征
以这种方式,降低维度 数据集的特征过多,有些对结果没有任何关系,
这个时候,将没有关系的特征删除,反而能获得更好的预测结果 下面使用决策树,预测泰坦尼克号幸存情况,
对不同百分比的筛选特征,进行学习和预测,比较准确率
''' # 1 准备数据
titanic = pd.read_csv("../data/titanic/titanic.txt")
# 分离数据特征与目标
y = titanic["survived"]
x = titanic.drop(["row.names", "name", "survived"], axis=1)
# 对缺失值进行补充
x['age'].fillna(x['age'].mean(), inplace=True)
x.fillna("UNKNOWN", inplace=True) # 2 分割数据集 25%用于测试 75%用于训练
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25, random_state=33) # 3 类别型特征向量化
vec = DictVectorizer()
x_train = vec.fit_transform(x_train.to_dict(orient='record'))
x_test = vec.transform(x_test.to_dict(orient='record'))
# 输出处理后向量的维度
# print(len(vec.feature_names_)) # 474 # 4 使用决策树对所有特征进行学习和预测
dt = DecisionTreeClassifier(criterion='entropy')
dt.fit(x_train, y_train)
print("全部维度的预测准确率:", dt.score(x_test, y_test)) # 0.8206686930091185 # 5 筛选前20%的特征,使用相同配置的决策树模型进行评估性能
fs = feature_selection.SelectPercentile(feature_selection.chi2, percentile=20)
x_train_fs = fs.fit_transform(x_train, y_train)
x_test_fs = fs.transform(x_test)
dt.fit(x_train_fs, y_train)
print("前20%特征的学习模型预测准确率:", dt.score(x_test_fs, y_test)) # 0.8237082066869301 # 6 通过交叉验证 按照固定间隔百分比筛选特征, 展示性能情况
percentiles = range(1, 100, 2)
results = []
for i in percentiles:
fs = feature_selection.SelectPercentile(feature_selection.chi2, percentile=i)
x_train_fs = fs.fit_transform(x_train, y_train)
scores = cross_val_score(dt, x_train_fs, y_train, cv=5)
results = np.append(results, scores.mean())
# print(results)
'''
[0.85063904 0.85673057 0.87501546 0.88622964 0.86284271 0.86489384
0.87303649 0.86689342 0.87098536 0.86690373 0.86895485 0.86083282
0.86691404 0.86488353 0.86895485 0.86792414 0.86284271 0.86995465
0.86486291 0.86385281 0.86384251 0.86894455 0.86794475 0.86690373
0.86488353 0.86489384 0.86590394 0.87300557 0.86995465 0.86793445
0.87097506 0.86998557 0.86692435 0.86892393 0.86997526 0.87098536
0.87198516 0.86691404 0.86691404 0.87301587 0.87202639 0.8648423
0.86386312 0.86388374 0.86794475 0.8618223 0.85877139 0.86285302
0.86692435 0.8577819 ]
'''
# 找到最佳性能的筛选百分比
opt = np.where(results == results.max())[0][0]
print("最高性能的筛选百分比是:%s%%" % percentiles[opt]) # pl.plot(percentiles, results)
pl.xlabel("特征筛选的百分比")
pl.ylabel("准确率")
pl.show()
生成的准确率图:
机器学习之路:python 特征降维 特征筛选 feature_selection的更多相关文章
- 机器学习之路: python 回归树 DecisionTreeRegressor 预测波士顿房价
python3 学习api的使用 git: https://github.com/linyi0604/MachineLearning 代码: from sklearn.datasets import ...
- 机器学习之路: python 线性回归LinearRegression, 随机参数回归SGDRegressor 预测波士顿房价
python3学习使用api 线性回归,和 随机参数回归 git: https://github.com/linyi0604/MachineLearning from sklearn.datasets ...
- 机器学习之路: python 决策树分类DecisionTreeClassifier 预测泰坦尼克号乘客是否幸存
使用python3 学习了决策树分类器的api 涉及到 特征的提取,数据类型保留,分类类型抽取出来新的类型 需要网上下载数据集,我把他们下载到了本地, 可以到我的git下载代码和数据集: https: ...
- 机器学习之路: python k近邻分类器 KNeighborsClassifier 鸢尾花分类预测
使用python语言 学习k近邻分类器的api 欢迎来到我的git查看源代码: https://github.com/linyi0604/MachineLearning from sklearn.da ...
- 机器学习之路--Python
常用数据结构 1.list 列表 有序集合 classmates = ['Michael', 'Bob', 'Tracy'] len(classmates) classmates[0] len(cla ...
- 什么是机器学习的特征工程?【数据集特征抽取(字典,文本TF-Idf)、特征预处理(标准化,归一化)、特征降维(低方差,相关系数,PCA)】
2.特征工程 2.1 数据集 2.1.1 可用数据集 Kaggle网址:https://www.kaggle.com/datasets UCI数据集网址: http://archive.ics.uci ...
- AI学习---特征工程【特征抽取、特征预处理、特征降维】
学习框架 特征工程(Feature Engineering) 数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已 什么是特征工程: 帮助我们使得算法性能更好发挥性能而已 sklearn主 ...
- 特征降维之PCA
目录 PCA思想 问题形式化表述 PCA之协方差矩阵 协方差定义 矩阵-特征值 PCA运算步骤 PCA理论解释 最大方差理论 性质 参数k的选取 数据重建 主观理解 应用 代码示例 PCA思想 PCA ...
- 如何用Python做自动化特征工程
机器学习的模型训练越来越自动化,但特征工程还是一个漫长的手动过程,依赖于专业的领域知识,直觉和数据处理.而特征选取恰恰是机器学习重要的先期步骤,虽然不如模型训练那样能产生直接可用的结果.本文作者将使用 ...
随机推荐
- java后台调用http请求
1:代码 @Value("${sms.username}") 可以将sms.properties配置文件中的值注入到username //这种方式是将sms.properti ...
- hdu 1495 非常可乐 (广搜)
题目链接 Problem Description 大家一定觉的运动以后喝可乐是一件很惬意的事情,但是seeyou却不这么认为.因为每次当seeyou买了可乐以后,阿牛就要求和seeyou一起分享这一瓶 ...
- JDk1.8源码StringBuffer
一.概念 StringBuffer A thread-safe, mutable sequence of characters. A string buffer is like a {@link St ...
- sleep允许休眠, delay不允许
在Linux Driver开发中,经常要用到延迟函数:msleep,mdelay/udelay. 虽然msleep和mdelay都有延迟的作用,但他们是有区别的. 1.)对于模块本身 mdelay是忙 ...
- inspect的使用
# -*- coding: utf-8 -*- # @Time : 2018/9/11 10:29 # @Author : cxa # @File : inspecttest.py # @Softwa ...
- 四、springcloud之服务调用Feign(二)
一.Fegin的常见应用 Feign的Encoder.Decoder和ErrorDecoder Feign将方法签名中方法参数对象序列化为请求参数放到HTTP请求中的过程,是由编码器(Encoder) ...
- 博客转移至github
博客转移到github 鉴于github的各种优势,博客转移!
- UVA10212 【The Last Non-zero Digit.】
暴力可做!!!(十秒还不打暴力!!!)暴力算阶乘边算边取余上代码 #include<iostream> #define int long long //开long long using n ...
- 用命令对sql进行备份
利用T-SQL语句,实现数据库的备份与还原的功能 体现了SQL Server中的四个知识点: 1. 获取SQL Server服务器上的默认目录 2. 备份SQL语句的使用 3. 恢复SQL语句的使用, ...
- GreenPlum学习笔记:create table创建表
二维表同样是GP中重要的存储数据对象,为了更好的支持数据仓库海量数据的访问,GP的表可以分成: 面向行存储的普通堆积表 面向列存储的AOT表(append only table) 当然AOT表也可以是 ...