从 Hadoop 1.0 到 Hadoop 2.0 ,你需要了解这些
学习大数据,刚开始接触的是 Hadoop 1.0,然后过度到 Hadoop 2.0 ,这里为了书写方便,本文中 Hadoop 1.0 采用 HV1 的缩写方式,Hadoop 2.0 采用 HV2 的缩写方式。
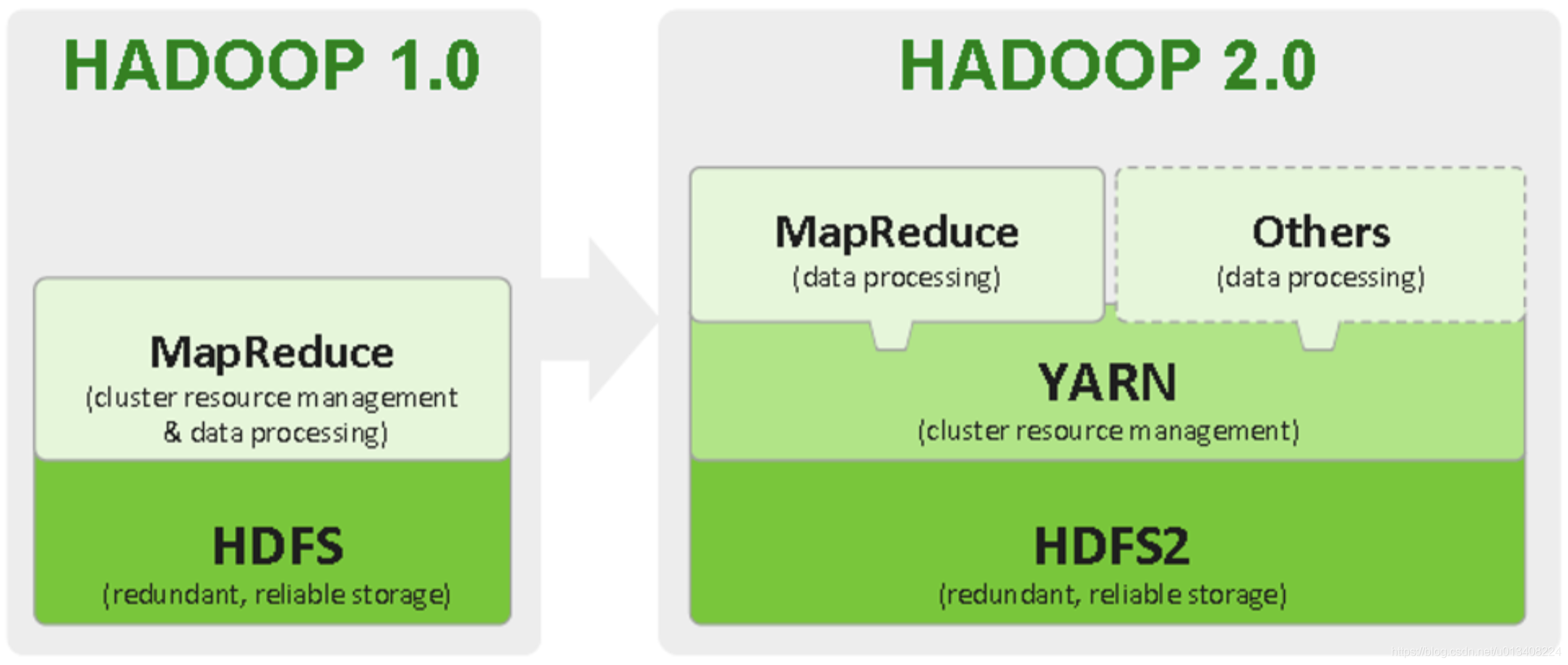
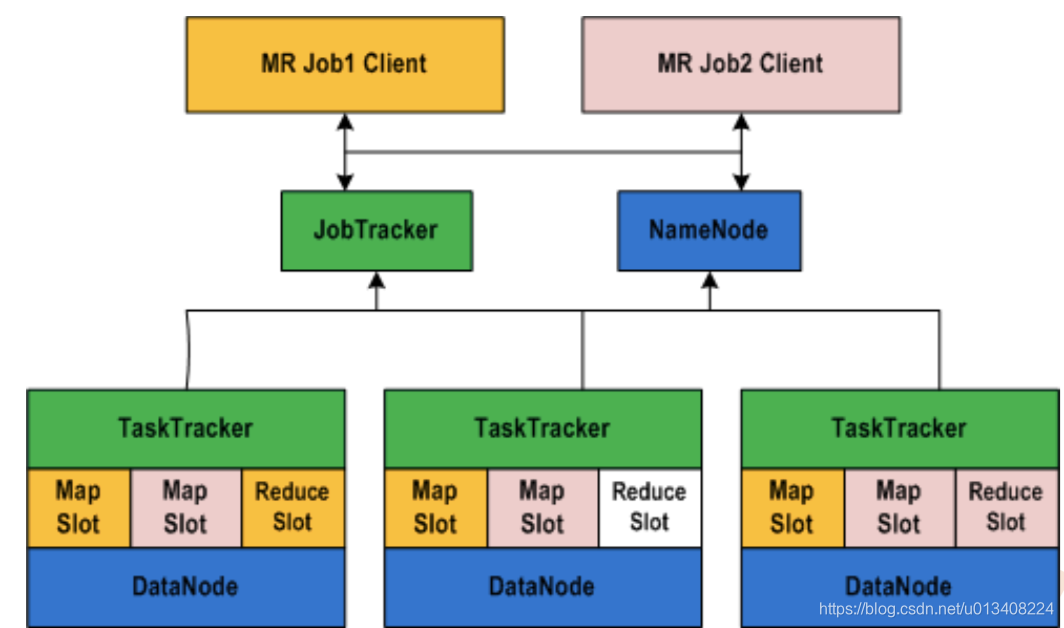
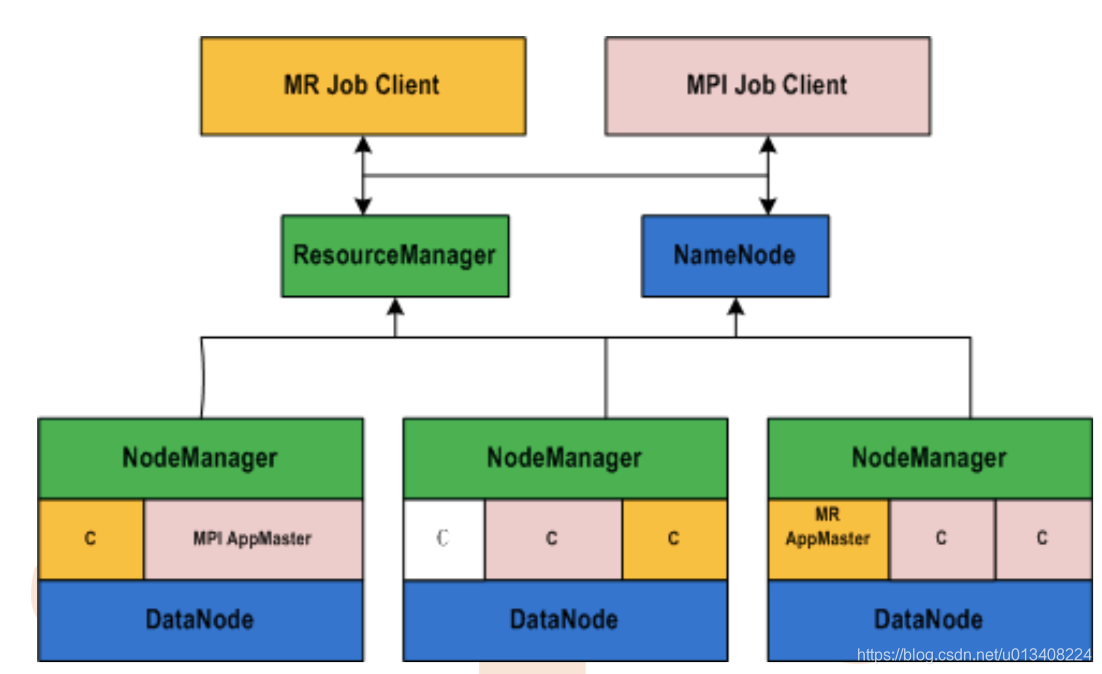
HV1 中不得不提的两个进程:JobTracker 和 TaskTracker。JobTracker 主要负责任务调度和集群资源管理,TaskTracker 主要负责任务执行。在 HV1 向 HV2 变迁后,引入了一个中间件Yarn,负责集群资源调度。可以简单地理解,Yarn 分离出了JobTracker 资源管理的权柄。
Yarn
Yarn 是一个分布式资源调度框架,其架构图如下所示:
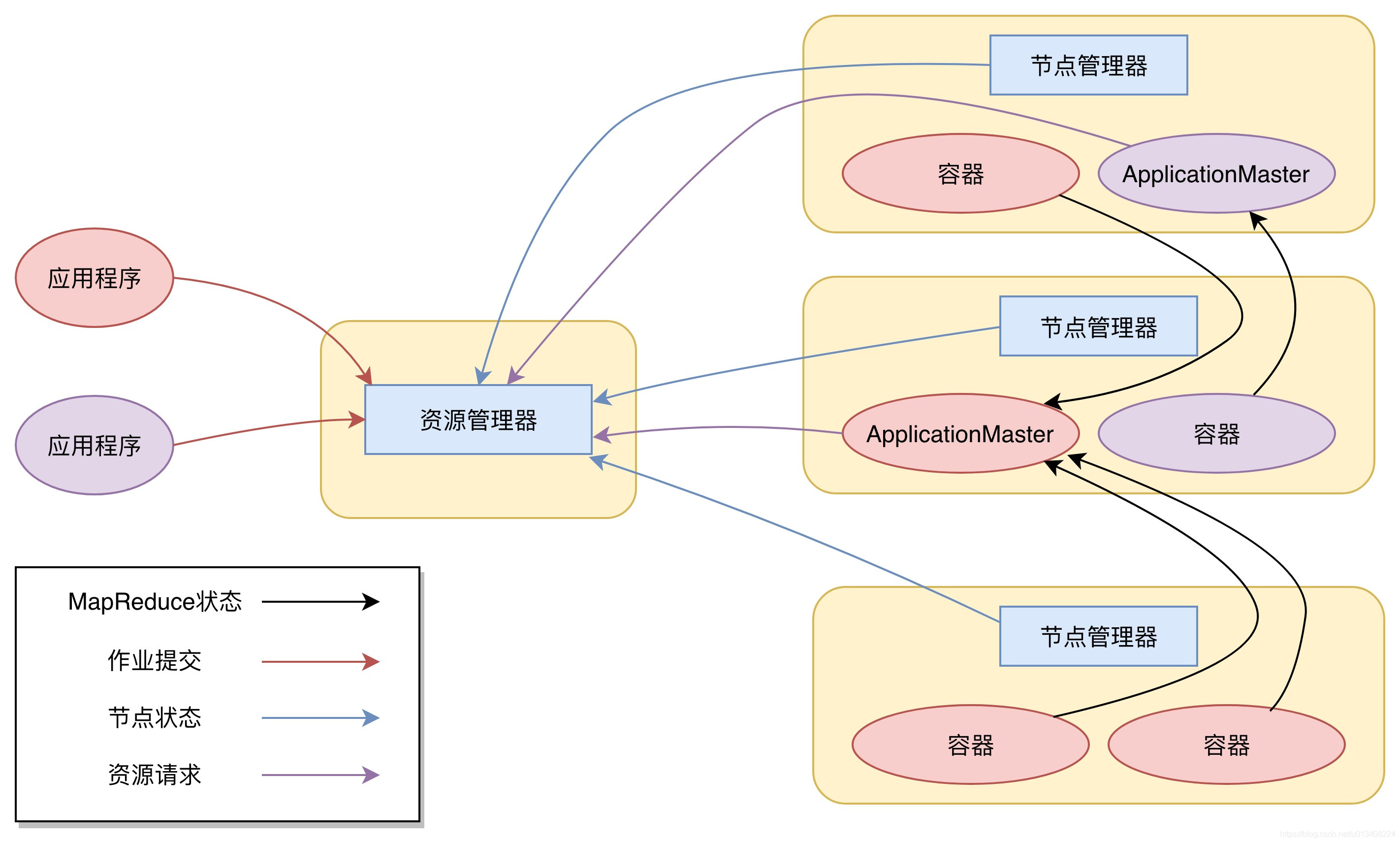
图中的三个重要进程:
- 资源管理器(ResourceManager,RM)
- 节点管理器(NodeManager,NM)
- ApplicationMaster(AM)
两个对比:
- Yarn 中容器(Container)可以对比 HV1 中 slot(槽) ,前者是逻辑层的概念,后者是物理层的概念。Container 是任务运行环境的抽象封装。
- HV1 中一个重要的概念 Job(作业),在 Yarn 中对应 Application(应用程序)。
HV1 和 HV2 对比示例图如下:
Yarn 的执行流程
Yarn 执行流程示意图如下所示:
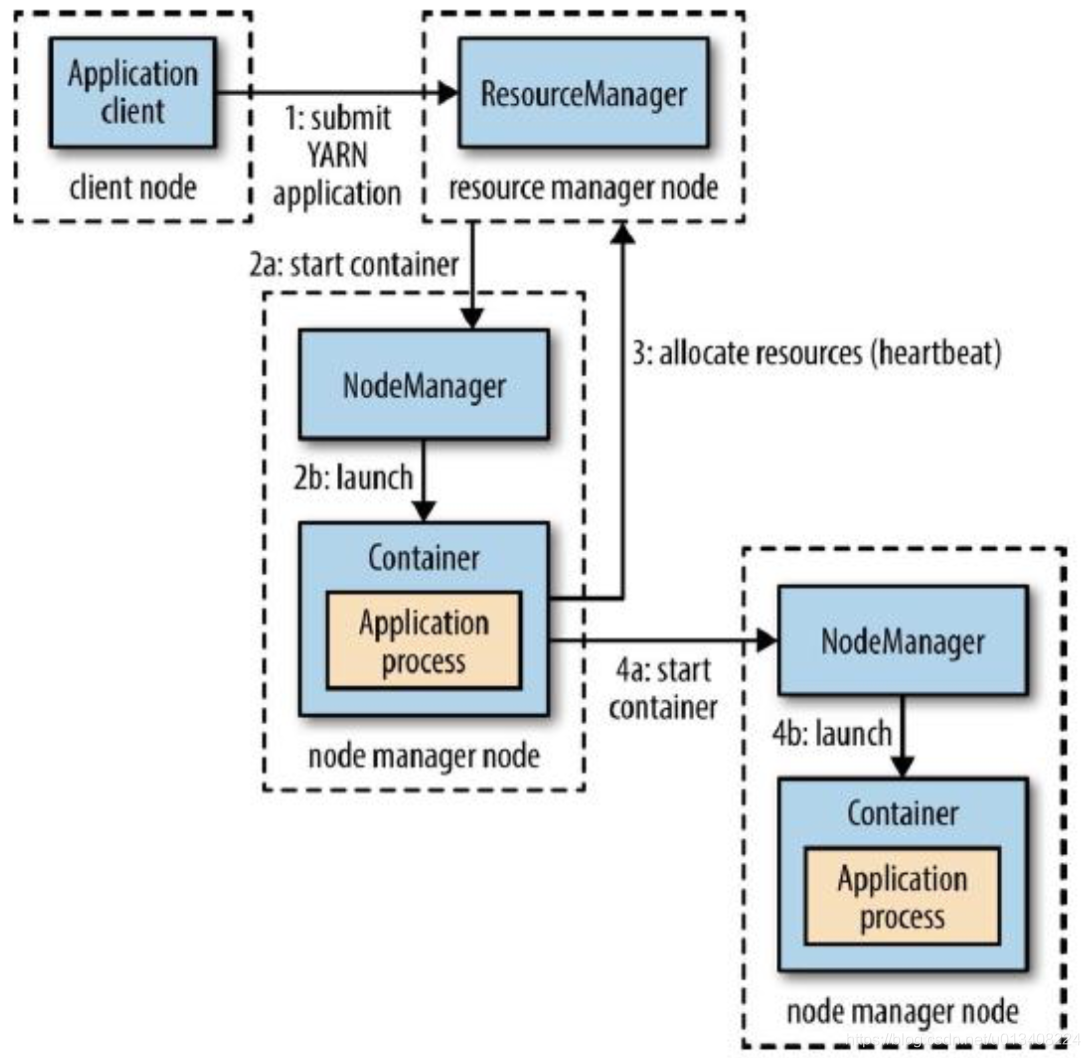
执行流程说明如下:
- Client 请求 ResourceManager 运行一个 ApplicationMaster 实例。
- ResourceManager 选择一个 NodeManager 启动一个 Container 运行 ApplicationMaster 实例。
- ApplicationMaster 根据实际需要向 ResourceManager 请求更多的 Container 资源,ApplicationMaster 通过获取到的 Container 资源执行分布式计算。
功能分析
通过执行流程,我们尝试去理解 Yarn 中三个重要进程(RM、NM、AM)对应的职责和功能。
RM 处理客户端请求,接收 JobSubmitter 提交的作业,按照作业的上下文(Context)信息,以及从 NM 收集来的状态信息,启动调度过程,分配一个 Container 作为 AM。RM 拥有系统中所有应用资源的决定权,是中心服务,调度、启动每一个作业所属的 Application,并监测 Application 的存在情况。
NM 处理来自 RM 的任务请求,接收并处理来自 AM 的 Container 启动、停止等请求。NM 负责启动应用程序的 Container ,监控它们的资源使用情况,并汇报给 RM。可以理解 NM 是在单节点上进行任务管理 和 资源管理。
AM 是应用程序的 Master,每一个 应用程序对应一个 AM,在用户提交一个应用程序时,一个 AM 的轻量型进程实例会启动,AM 协调应用程序内所有任务的执行。
HV2 新特性
HV2 的新特性包括:
- NameNode HA
- NameNode Federation
- HDFS 快照
- HDFS ACL
- 异构层级存储结构
本文只详述其中两点:NameNode HA 和NameNode Federation。NameNode HA优化的是单点故障问题,NameNode Federation优化的是集群的横向扩展问题。
NameNode HA
HV2 对 HV1 中存在的很多问题进行了优化。例如,HV1 中 NameNode 的单点故障问题,在 HV2 中可以通过一个集群中运行两个NameNode(active NameNode 和 standby NameNode)来解决。任何时间,只有一台机器处于 Active 状态,另一台机器处于standby 状态,其框架如下图所示:
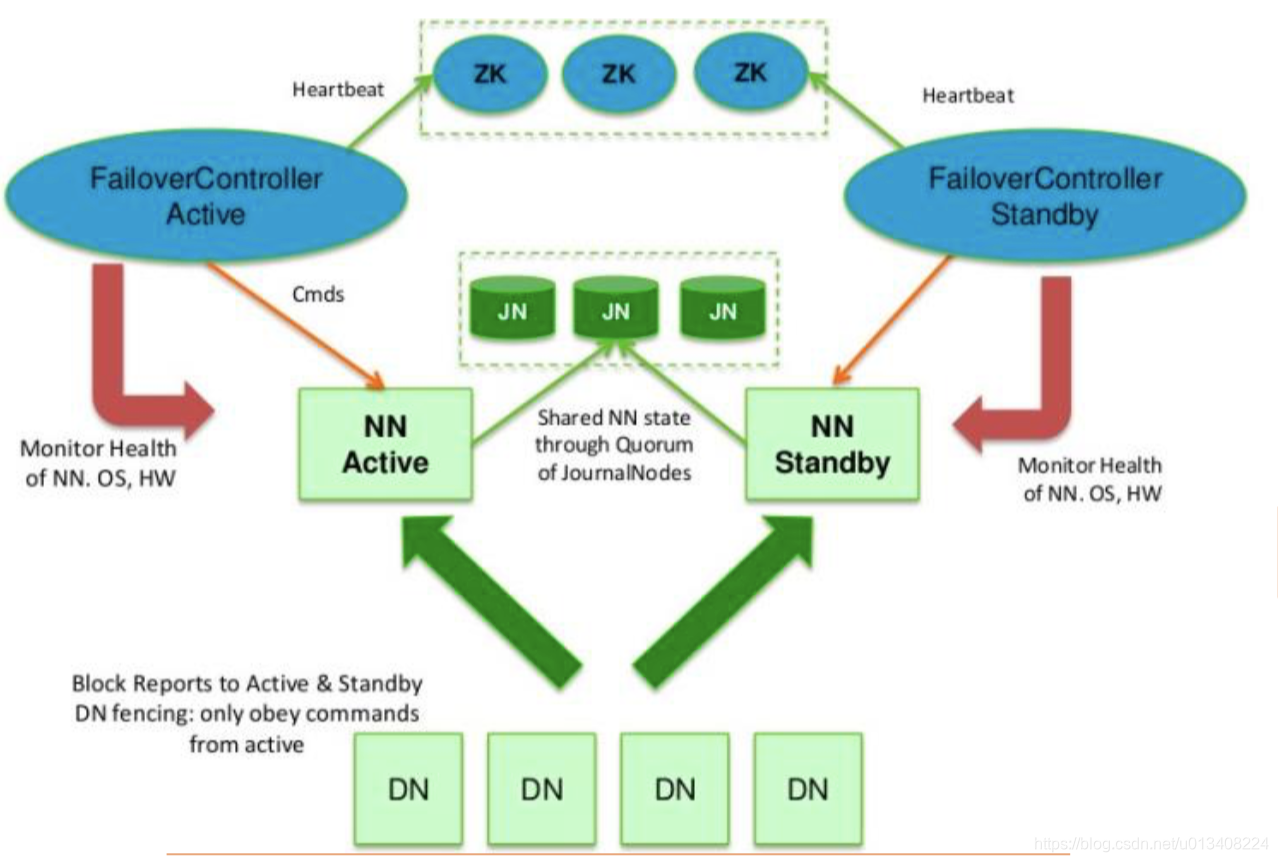
通过zookeeper(ZK)选举确定当前唯一active状态的NameNode,依赖 JournalNodes(JN)守护进程确保两个NameNode 数据同步。
NameNode Federation
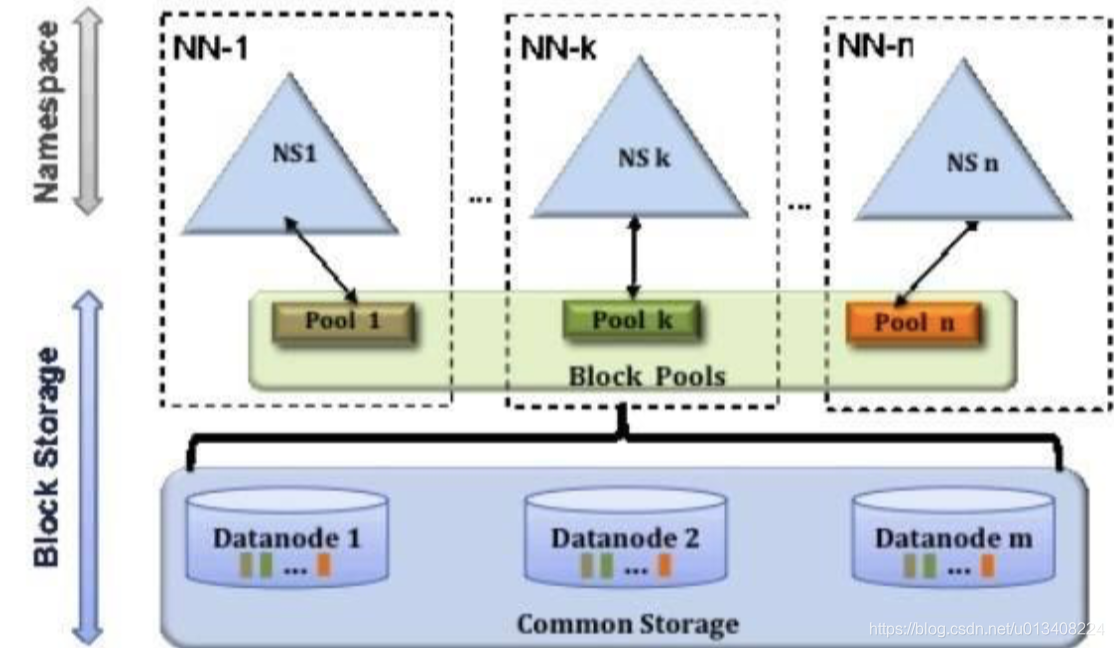
HV1 中 HDFS 只有一个NameSpace,元数据信息是存储在NameNode 上的,单一存储会使得 NameNode 的资源使用率达到上限,同时负载能力越来越高,影响 HDFS性能。HV2 中对NameNode 进行了一个横向扩展,引入了NameNode “城邦”特性。该特性允许在集群中提供多个 NameNode ,同时对外提供服务,每个 NameNode 管理一部分 DataNode。其框架如下图所示:
再谈
引入Yarn资源管理框架,将HV1中资源管理和任务调度的功能解耦,带来的好处如下:
- 减少了JobTracker(也就是现在的RM)的资源消耗,并且让监测每一个Job子任务(tasks)状态的程序分布式化了,更安全。
- AM是一个可变更的部分,用户可以对不同的编程模型编写自己的AM,让更多类型的编程模型能够跑在Hadoop集群中。
- 对于资源的表示以内存为单位,比以前以剩余slot数目更合理。
- 老的框架中,jobTracker一个很大的负担就是监控Job下的Task的运行情况,现在,这部分扔给ApplicationMaster做了。
- 资源表示成内存量,那就没有了之前的map slot/reduce slot分开造成集群资源闲置的尴尬情况。
好了,今天的博客就到这里了,期待你的指正。
从 Hadoop 1.0 到 Hadoop 2.0 ,你需要了解这些的更多相关文章
- 编译hadoop eclipse的插件(hadoop1.0)
原创文章,转载请注明: 转载自工学1号馆 欢迎关注我的个人博客:www.wuyudong.com, 更多云计算与大数据的精彩文章 在hadoop-1.0中,不像0.20.2版本,有现成的eclipse ...
- hadoop1.0 和 Hadoop 2.0 的区别
1.Hadoop概述 在Google三篇大数据论文发表之后,Cloudera公司在这几篇论文的基础上,开发出了现在的Hadoop.但Hadoop开发出来也并非一帆风顺的,Hadoop1.0版本有诸多局 ...
- Ambari2.7.3 和HDP3.1.0搭建Hadoop集群
一.环境及软件准备 1.集群规划 hdp01/10.1.1.11 hdp02/10.1.1.12 hdp03/10.1.1.13 hdp04/10.1.1.14 hdp05/10.1.1.15 a ...
- hadoop 遇到java.net.ConnectException: to 0.0.0.0:10020 failed on connection
hadoop 遇到java.net.ConnectException: to 0.0.0.0:10020 failed on connection 这个问题一般是在hadoop2.x版本里会出 ...
- failed to launch: nice -n 0 /home/hadoop/spark-2.3.3-bin-hadoop2.7/bin/spark-class org.apache.spark.deploy.worker.Worker --webui-port 8081 spark://namenode1:7077
spark2.3.3安装完成之后启动报错: [hadoop@namenode1 sbin]$ ./start-all.shstarting org.apache.spark.deploy.master ...
- Data - Hadoop单机配置 - 使用Hadoop2.8.0和Ubuntu16.04
系统版本 anliven@Ubuntu1604:~$ uname -a Linux Ubuntu1604 4.8.0-36-generic #36~16.04.1-Ubuntu SMP Sun Feb ...
- Linux上安装Hadoop集群(CentOS7+hadoop-2.8.0)
1下载hadoop 2安装3个虚拟机并实现ssh免密码登录 2.1安装3个机器 2.2检查机器名称 2.3修改/etc/hosts文件 2.4 给3个机器生成秘钥文件 2.5 在hserver1上创建 ...
- 通过tarball形式安装HBASE Cluster(CDH5.0.2)——重新编译CDH5.0.2 HADOOP点滴
本文参考博文Hadoop2.2.0遇到64位操作系统平台报错,重新编译Hadoop 由于我采用的tarball方式安装hadoop,其lib/native下根本没有内容,启动hdfs时报这个经典的na ...
- [转]hadoop运行mapreduce作业无法连接0.0.0.0/0.0.0.0:10020
14/04/04 17:15:12 INFO mapreduce.Job: map 0% reduce 0% 14/04/04 17:19:42 INFO mapreduce.Job: map 4 ...
- Hadoop集群搭建-Hadoop2.8.0安装(三)
一.准备安装介质 a).hadoop-2.8.0.tar b).jdk-7u71-linux-x64.tar 二.节点部署图 三.安装步骤 环境介绍: 主服务器ip:192.168.80.128(ma ...
随机推荐
- “全栈2019”Java多线程第二十三章:活锁(Livelock)详解
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java多 ...
- javascript中的数据类型和变量
Number JavaScript不区分整数和浮点数,统一用Number表示,以下都是合法的Number类型: 123; // 整数123 0.456; // 浮点数0.456 1.2345e3; / ...
- 静态分析第三发 so文件分析(小黄人快跑)
本文作者:i春秋作家——HAI_ 0×00 工具 1.IDA pro 2.Android Killer 0×01 环境 小黄人快跑 下载地址http://download.csdn.net/downl ...
- mybatis单表操作实现完全java代码封装
之前在项目中用到mybtis操作数据库时都是手动写sql,对于我这种sql水平不是很好地人来说痛苦死了:动态查询的sql我表示到现在还不会写呀! 还好,利用数据库表反向生成的工具可以帮我解决大部分的s ...
- python里面如何拷贝一个对象?deepcopy 和 copy 有什么区别 ?
深拷贝就是说原内容改变但是拷贝的性内容不会改变,copy.copy和deepcopy对一个不可变类型进行拷贝, name结果相同都是浅拷贝指向引用如果是可变的话, 即使元组在最外层, 那么deepco ...
- mysql编写存储过程(1)
存储过程:其实就是存储在数据库中,有一些逻辑语句与SQL语句组成的函数.由于是已经编译好的语句,所以执行速度快,而且也安全. 打开mysql的控制台,开始编写存储过程. 实例1: 编写存储过程: 执行 ...
- Python面试题整理-更新中
几个链接: 编程零基础应当如何开始学习 Python ? - 路人甲的回答 网易云课堂上有哪些值得推荐的 Python 教程? - 路人甲的回答 怎么用最短时间高效而踏实地学习 Python? - 路 ...
- day 45 Django 的初识2 路由层,视图层,模板层
前情提要: 今天继续学习Django 的内容, 今天主要和渲染相关 1>配置路由 >2:写函数 >3 指向url 一:路由层 1:配置静态支持文件 1:路由层的简单配置 >dj ...
- Java基础梳理(一)
List和Set比较,各自的子类比较 对比一:Arraylist与LinkedList的比较 1.ArrayList是实现了基于动态数组的数据结构,因为地址连续,一旦数据存储好了,查询操作效率会比较高 ...
- vue聊天室|h5+vue仿微信聊天界面|vue仿微信
一.项目简介 基于Vue2.0+Vuex+vue-router+webpack2.0+es6+vuePhotoPreview+wcPop等技术架构开发的仿微信界面聊天室——vueChatRoom,实现 ...