Hadoop:开发机运行spark程序,抛出异常:ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
问题:
windows开发机运行spark程序,抛出异常:ERROR Shell: Failed to locate the winutils binary in the hadoop binary path,但是可以正常执行,并不影响结果。
// :: WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
// :: ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:)
at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:)
at org.apache.hadoop.util.Shell.<clinit>(Shell.java:)
at org.apache.hadoop.util.StringUtils.<clinit>(StringUtils.java:)
at org.apache.hadoop.security.Groups.parseStaticMapping(Groups.java:)
at org.apache.hadoop.security.Groups.<init>(Groups.java:)
at org.apache.hadoop.security.Groups.<init>(Groups.java:)
at org.apache.hadoop.security.Groups.getUserToGroupsMappingService(Groups.java:)
at org.apache.hadoop.security.UserGroupInformation.initialize(UserGroupInformation.java:)
at org.apache.hadoop.security.UserGroupInformation.ensureInitialized(UserGroupInformation.java:)
at org.apache.hadoop.security.UserGroupInformation.loginUserFromSubject(UserGroupInformation.java:)
at org.apache.hadoop.security.UserGroupInformation.getLoginUser(UserGroupInformation.java:)
at org.apache.hadoop.security.UserGroupInformation.getCurrentUser(UserGroupInformation.java:)
at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$.apply(Utils.scala:)
at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$.apply(Utils.scala:)
at scala.Option.getOrElse(Option.scala:)
at org.apache.spark.util.Utils$.getCurrentUserName(Utils.scala:)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:)
at org.apache.spark.api.java.JavaSparkContext.<init>(JavaSparkContext.scala:)
at com.lm.sparkLearning.utils.SparkUtils.getJavaSparkContext(SparkUtils.java:)
at com.lm.sparkLearning.rdd.RddLearning.main(RddLearning.java:)
// :: WARN RddLearning: singleOperateRdd mapRdd->[, , , ]
// :: WARN RddLearning: singleOperateRdd flatMapRdd->[, , , , , , , ]
// :: WARN RddLearning: singleOperateRdd filterRdd->[, ]
// :: WARN RddLearning: singleOperateRdd distinctRdd->[, , ]
// :: WARN RddLearning: singleOperateRdd sampleRdd->[, ]
// :: WARN RddLearning: the program end
这里所执行的程序是:
package com.lm.sparkLearning.rdd; import java.util.Arrays;
import java.util.Iterator;
import java.util.List; import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.VoidFunction;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory; import com.lm.sparkLearning.utils.SparkUtils; public class RddLearning {
private static Logger logger = LoggerFactory.getLogger(RddLearning.class); public static void main(String[] args) { JavaSparkContext jsc = SparkUtils.getJavaSparkContext("RDDLearning", "local[2]", "WARN"); SparkUtils.createRddExternal(jsc, "D:/README.txt");
singleOperateRdd(jsc); jsc.stop(); logger.warn("the program end");
} public static void singleOperateRdd(JavaSparkContext jsc) {
List<Integer> nums = Arrays.asList(new Integer[] { 1, 2, 3, 3 });
JavaRDD<Integer> numsRdd = SparkUtils.createRddCollect(jsc, nums); // map
JavaRDD<Integer> mapRdd = numsRdd.map(new Function<Integer, Integer>() {
private static final long serialVersionUID = 1L; @Override
public Integer call(Integer v1) throws Exception {
return (v1 + 1);
}
}); logger.warn("singleOperateRdd mapRdd->" + mapRdd.collect().toString()); JavaRDD<Integer> flatMapRdd = numsRdd.flatMap(new FlatMapFunction<Integer, Integer>() {
private static final long serialVersionUID = 1L; @Override
public Iterable<Integer> call(Integer t) throws Exception {
return Arrays.asList(new Integer[] { 2, 3 });
}
}); logger.warn("singleOperateRdd flatMapRdd->" + flatMapRdd.collect().toString()); JavaRDD<Integer> filterRdd = numsRdd.filter(new Function<Integer, Boolean>() {
private static final long serialVersionUID = 1L; @Override
public Boolean call(Integer v1) throws Exception {
return v1 > 2;
}
}); logger.warn("singleOperateRdd filterRdd->" + filterRdd.collect().toString()); JavaRDD<Integer> distinctRdd = numsRdd.distinct(); logger.warn("singleOperateRdd distinctRdd->" + distinctRdd.collect().toString()); JavaRDD<Integer> sampleRdd = numsRdd.sample(false, 0.5); logger.warn("singleOperateRdd sampleRdd->" + sampleRdd.collect().toString());
}
}
解决方案:
1.下载winutils的windows版本
GitHub上,有人提供了winutils的windows的版本,项目地址是:https://github.com/srccodes/hadoop-common-2.2.0-bin,直接下载此项目的zip包,下载后是文件名是hadoop-common-2.2.0-bin-master.zip,随便解压到一个目录。
2.配置环境变量
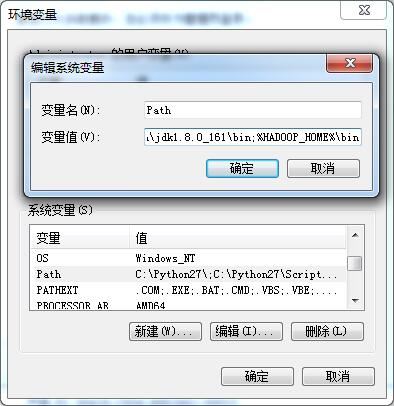
增加用户变量HADOOP_HOME,值是下载的zip包解压的目录,然后在系统变量path里增加$HADOOP_HOME\bin 即可。
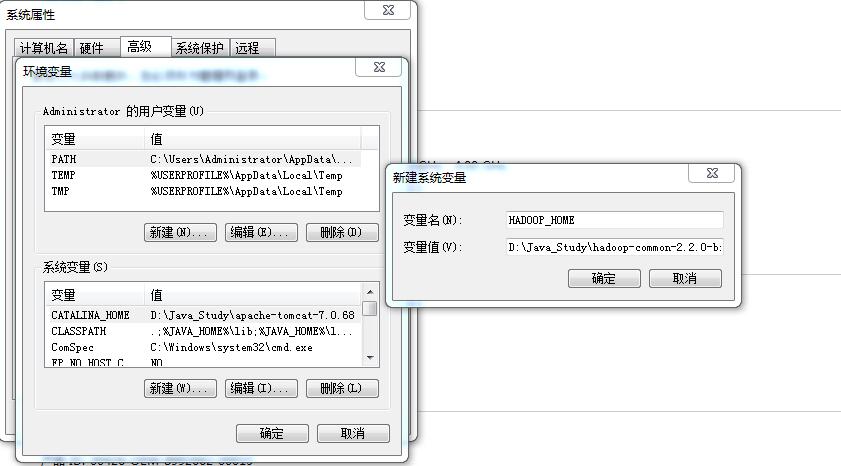
添加“%HADOOP%\bin”到path
再次运行程序,正常执行。
Hadoop:开发机运行spark程序,抛出异常:ERROR Shell: Failed to locate the winutils binary in the hadoop binary path的更多相关文章
- ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
文章发自:http://www.cnblogs.com/hark0623/p/4170172.html 转发请注明 14/12/17 19:18:53 ERROR Shell: Failed to ...
- Spark- ERROR Shell: Failed to locate the winutils binary in the hadoop binary path java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
运行 mport org.apache.log4j.{Level, Logger} import org.apache.spark.rdd.RDD import org.apache.spark.{S ...
- Windows本地运行调试Spark或Hadoop程序失败:ERROR util.Shell: Failed to locate the winutils binary in the hadoop binary path
报错内容 ERROR util.Shell: Failed to locate the winutils binary in the hadoop binary path java.io.IOExce ...
- idea 提示:ERROR util.Shell: Failed to locate the winutils binary in the hadoop binary path java.io.IOException解决方法
Windows系统中的IDEA链接Linux里面的Hadoop的api时出现的问题 提示:ERROR util.Shell: Failed to locate the winutils binary ...
- windows本地调试安装hadoop(idea) : ERROR util.Shell: Failed to locate the winutils binary in the hadoop binary path
1,本地安装hadoop https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/ 下载hadoop对应版本 (我本意是想下载hadoop ...
- ERROR [org.apache.hadoop.util.Shell] - Failed to locate the winutils binary in the hadoop binary path
错误日志如下: -- ::, DEBUG [org.apache.hadoop.metrics2.lib.MutableMetricsFactory] - field org.apache.hadoo ...
- WIN7下运行hadoop程序报:Failed to locate the winutils binary in the hadoop binary path
之前在mac上调试hadoop程序(mac之前配置过hadoop环境)一直都是正常的.因为工作需要,需要在windows上先调试该程序,然后再转到linux下.程序运行的过程中,报Failed to ...
- Windows7系统运行hadoop报Failed to locate the winutils binary in the hadoop binary path错误
程序运行的过程中,报Failed to locate the winutils binary in the hadoop binary path Java.io.IOException: Could ...
- Spark报错:Failed to locate the winutils binary in the hadoop binary path
之前在mac上调试hadoop程序(mac之前配置过hadoop环境)一直都是正常的.因为工作需要,需要在windows上先调试该程序,然后再转到linux下.程序运行的过程中,报 Failed to ...
随机推荐
- sql 计算两个经纬度点之间的距离
这里用到的算法和地球半径等数据均来自网络,此文只作整理记录. 地球半径值采用赤道半径 6378137.0米,这是1980年的国际标准数据. //存储过程 CREATE FUNCTION [f_GetD ...
- spring-boot 速成(4) 自定义配置
spring-boot 提供了很多默认的配置项,但是开发过程中,总会有一些业务自己的配置项,下面示例了,如何添加一个自定义的配置: 一.写一个自定义配置的类 package com.example.c ...
- 从Redis的数据丢失说起(转)
碰到一个悲催的事情:一台Redis服务器,4核,16G内存且没有任何硬件上的问题.持续高压运行了大约3个月,保存了大约14G的数据,设置了比较完备的Save参数.而就是这台主机,在一次重起之后,丢失了 ...
- POJ 2337 Catenyms (有向图欧拉路径,求字典序最小的解)
Catenyms Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 8756 Accepted: 2306 Descript ...
- HTML一些标签注意事项
最近在IE10下运行一个以前的做web系统发现了两个小问题: 一.图片上使用"alt"属性来添加一些文字提示信息在IE10下无法正常显示出来 上网查了一下原因:原来是现在一些较新的 ...
- 对一个前端使用AngularJS后端使用ASP.NET Web API项目的理解(4)
chsakell分享了一个前端使用AngularJS,后端使用ASP.NET Web API的项目. 源码: https://github.com/chsakell/spa-webapi-angula ...
- 在ASP.NET MVC中使用Knockout实践08,使用foreach绑定集合
本篇体验使用 foreach 绑定一个Product集合. 首先使用构造创建一个View Model. var Product = function(data) { this.name = ko.ob ...
- 查看Android源码版本
from://http://www.cnblogs.com/flyme/archive/2011/10/14/2211143.html 有时候我们辛苦取到Android的源代码,想知道它的确切版本号, ...
- java对象的六大原则
对象的六大原则: 1.单一职责原则(Single Responsibility Principle SRP) 2.开闭原则(Open Close Principle OCP) 3.里氏替换原则(Li ...
- 如何生成安全的密码 Hash:MD5, SHA, PBKDF2, BCrypt 示例
密码 Hash 值的产生是将用户所提供的密码通过使用一定的算法计算后得到的加密字符序列.在 Java 中提供很多被证明能有效保证密码安全的 Hash 算法实现,我将在这篇文章中讨论其中的部分算法. 需 ...