初窥scrapy爬虫
2017-10-30 21:49:55
前言:
初步使用scrapy爬虫框架,爬取各个网站信息
系统环境:
64位win10系统,装有64位python3.6,IDE为pycharm,使用cmd命令行工具
预备知识:
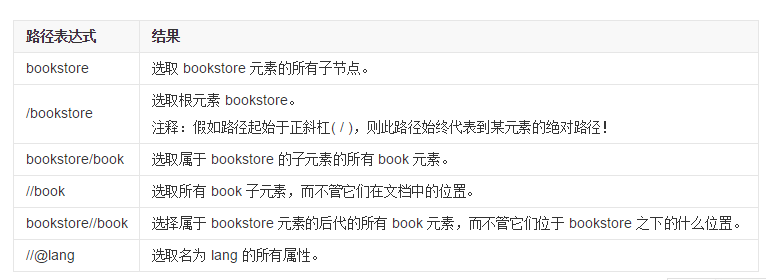
XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似,以下是最有用的路径表达式:

代码:
import scrapy class JulyeduSpider(scrapy.Spider):
name = 'julyedu'
start_urls = ['https://www.julyedu.com/category/index'] def parse(self,response):
for julyedu_class in response.xpath('//div[@class="course_info_box"]'):
print (julyedu_class.xpath('a/h4/text()').extract_first())
print (julyedu_class.xpath('a/p[@class="course-info-tip"]/text()').extract_first())
print (julyedu_class.xpath('a/p[@class="course-info-tip info-time"]/text()').extract_first()) yield {'title':julyedu_class.xpath('a/h4/text()').extract_first(),
'desc':julyedu_class.xpath('a/p[@class="course-info-tip"]/text()').extract_first(),
'time':julyedu_class.xpath('a/p[@class="course-info-tip info-time"]/text()').extract_first()}
代码解释:
首先建立一个文件名为“julyedu_spider”的py文件,导入scrapy框架,然后创建一个JulyeduSpider的类,名字为'juyedu',start_urls为起始的网址。
然后定义解析网页的方法parse,我们需要获取标题,描述,时间等信息,因此右键检查,
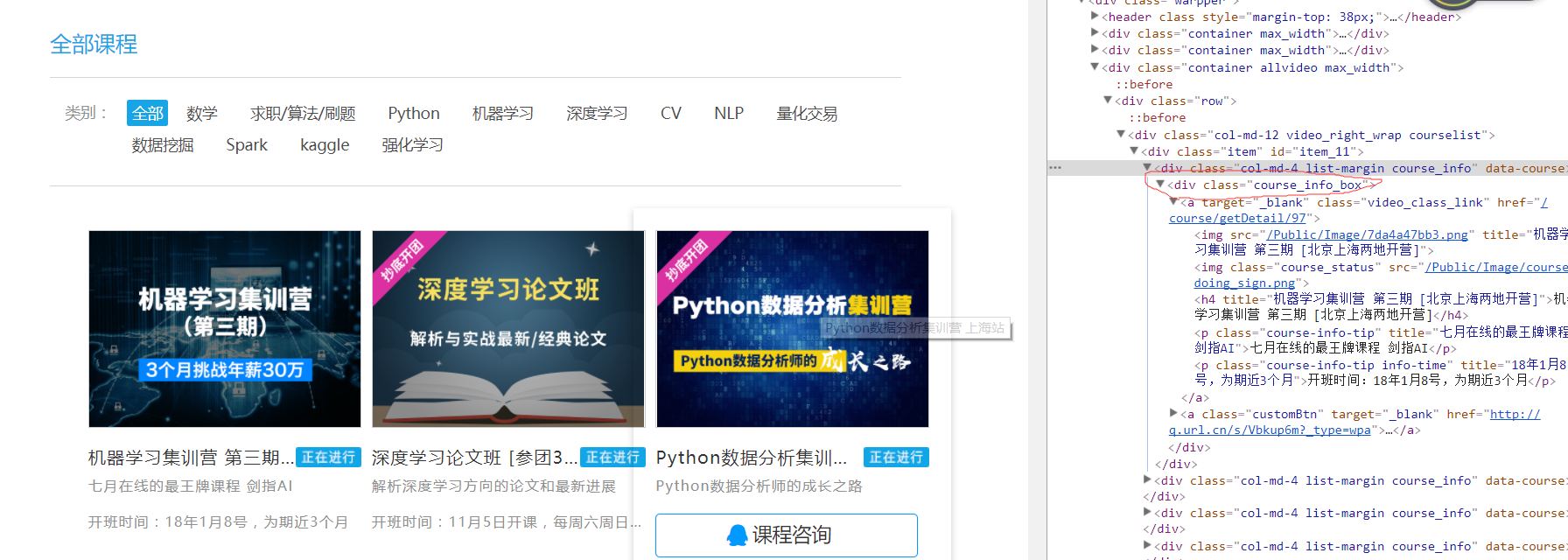
'//div[@class="course_info_box”]'表示选取属性为"course_info_box”标签的子元素,而不管他们的在文档中的位置
'a/h4/text()'表示a标签的子标签h4的文本内容
'a/p[@class="course-info-tip"]/text()'表示a标签的class属性为“..”的p标签的文本内容
'a/p[@class="course-info-tip info-time"]/text()'同理
yield表示创建对应的字典,将数据导入到json,xml,csv等格式的文件中
保存文件后,我们打开cmd窗口,注意要在py文件的目录下打开(按住shift右键即可),输入
scrapy runspider julyedu_spider.py
即可看到打印的内容
再输入
scrapy runspider julyedu_spider.py -o julyedu_class.csv
即可将爬取数据保存到CSV文件中
另外
再补充scrapy shell的用法,同样我们需要在进入项目的根目录,在命令行中输入:
scrapy shell 'https://www.julyedu.com/category/index'
即可加载shell,会获得一个response回应,然后输入
response.xpath('xpath路径')
即可得到所需的内容
初窥scrapy爬虫的更多相关文章
- python爬虫 scrapy2_初窥Scrapy
sklearn实战-乳腺癌细胞数据挖掘 https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campai ...
- scrapy2_初窥Scrapy
递归知识:oop,xpath,jsp,items,pipline等专业网络知识,初级水平并不是很scrapy,可以从简单模块自己写. 初窥Scrapy Scrapy是一个为了爬取网站数据,提取结构性数 ...
- Scrapy 1.4 文档 01 初窥 Scrapy
初窥 Scrapy Scrapy 是用于抓取网站并提取结构化数据的应用程序框架,其应用非常广泛,如数据挖掘,信息处理或历史存档. 尽管 Scrapy 最初设计用于网络数据采集(web scraping ...
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- [Python爬虫] scrapy爬虫系列 <一>.安装及入门介绍
前面介绍了很多Selenium基于自动测试的Python爬虫程序,主要利用它的xpath语句,通过分析网页DOM树结构进行爬取内容,同时可以结合Phantomjs模拟浏览器进行鼠标或键盘操作.但是,更 ...
- Scrapy001-框架初窥
Scrapy001-框架初窥 @(Spider)[POSTS] 1.Scrapy简介 Scrapy是一个应用于抓取.提取.处理.存储等网站数据的框架(类似Django). 应用: 数据挖掘 信息处理 ...
- scrapy爬虫结果插入mysql数据库
1.通过工具创建数据库scrapy
- 初窥Kaggle竞赛
初窥Kaggle竞赛 原文地址: https://www.dataquest.io/mission/74/getting-started-with-kaggle 1: Kaggle竞赛 我们接下来将要 ...
- Linux搭建Scrapy爬虫集成开发环境
安装Python 下载地址:http://www.python.org/, Python 有 Python 2 和 Python 3 两个版本, 语法有些区别,ubuntu上自带了python2.7. ...
随机推荐
- 微软BI 之SSIS 系列 - 带有 Header 和 Trailer 的不规则的平面文件输出处理技巧
案例背景与需求介绍 之前做过一个美国的医疗保险的项目,保险提供商有大量的文件需要发送给比如像银行,医疗协会,第三方服务商等.比如像与银行交互的 ACH 文件,传送给协会的 ACH Credit 等文件 ...
- Linux-文件描述符的本质及与文件指针的区别
文章参考:文件描述符的本质.文件描述符和文件指针的区别.文件描述符fd和文件指针flip的理解 推荐:task_struct 和文件系统的关系 系统中文件相关表 右侧的表称为i节点表,在整个系统中只有 ...
- Android——SQLite/数据库 相关知识总结贴
android SQLite简介 http://www.apkbus.com/android-1780-1-1.html Android SQLite基础 http://www.apkbus.com/ ...
- Easyui datagrid 特殊处理,记录笔记
1. 特殊的单元格样式 columns中 { field: , styler: function (value, row, index) { ') { return 'background-color ...
- Linux使用图形LVM(Logical Volume Manager)工具进行分区的动态扩展
- FTP上传、下载(简单小例子)
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.I ...
- cmd命令中截取日期字符
%date:~0,10% 表示年份
- [svc]linux下网桥-docker网桥
网桥和交换机 2口交换机=网桥 交换机: 工作在数据链路层,根据源mac学习(控制层),目的mac转发(数据层). linux的网卡 vmware workstation中的桥接 参考: http:/ ...
- Java Lombok
Reducing Boilerplate Code with Project Lombok https://projectlombok.org/features/all https://github. ...
- linux每日命令(33):diff命令
diff 命令是 linux上非常重要的工具,用于比较文件的内容,特别是比较两个版本不同的文件以找到改动的地方.diff在命令行中打印每一个行的改动.最新版本的diff还支持二进制文件.diff程序的 ...