PySpark 的背后原理
文章正文
Spark主要是由Scala语言开发,为了方便和其他系统集成而不引入scala相关依赖,部分实现使用Java语言开发,例如External Shuffle Service等。总体来说,Spark是由JVM语言实现,会运行在JVM中。然而,Spark除了提供Scala/Java开发接口外,还提供了Python、R等语言的开发接口,为了保证Spark核心实现的独立性,Spark仅在外围做包装,实现对不同语言的开发支持,本文主要介绍Python Spark的实现原理,剖析pyspark应用程序是如何运行起来的。
1、Spark运行时架构
首先我们先回顾下Spark的基本运行时架构,如下图所示,其中橙色部分表示为JVM,Spark应用程序运行时主要分为Driver和Executor,Driver负载总体调度及UI展示,Executor负责Task运行,Spark可以部署在多种资源管理系统中,例如Yarn、Mesos等,同时Spark自身也实现了一种简单的Standalone(独立部署)资源管理系统,可以不用借助其他资源管理系统即可运行。更多细节请参考Spark Scheduler内部原理剖析。

用户的Spark应用程序运行在Driver上(某种程度上说,用户的程序就是Spark Driver程序),经过Spark调度封装成一个个Task,再将这些Task信息发给Executor执行,Task信息包括代码逻辑以及数据信息,Executor不直接运行用户的代码。
2、PySpark运行时架构
为了不破坏Spark已有的运行时架构,Spark在外围包装一层Python API,借助Py4j实现Python和Java的交互,进而实现通过Python编写Spark应用程序,其运行时架构如下图所示。

其中白色部分是新增的Python进程,在Driver端,通过Py4j实现在Python中调用Java的方法,即将用户写的PySpark程序”映射”到JVM中,例如,用户在PySpark中实例化一个Python的SparkContext对象,最终会在JVM中实例化Scala的SparkContext对象;在Executor端,则不需要借助Py4j,因为Executor端运行的Task逻辑是由Driver发过来的,那是序列化后的字节码,虽然里面可能包含有用户定义的Python函数或Lambda表达式,Py4j并不能实现在Java里调用Python的方法,为了能在Executor端运行用户定义的Python函数或Lambda表达式,则需要为每个Task单独启一个Python进程,通过socket通信方式将Python函数或Lambda表达式发给Python进程执行。语言层面的交互总体流程如下图所示,实线表示方法调用,虚线表示结果返回。

下面分别详细剖析PySpark的Driver是如何运行起来的以及Executor是如何运行Task的。
2.1 Driver端运行原理
当我们通过spark-submmit提交pyspark程序,首先会上传python脚本及依赖,并申请Driver资源,当申请到Driver资源后,会通过PythonRunner(其中有main方法)拉起JVM,如下图所示。

PythonRunner入口main函数里主要做两件事:
- 开启Py4j GatewayServer
- 通过Java Process方式运行用户上传的Python脚本
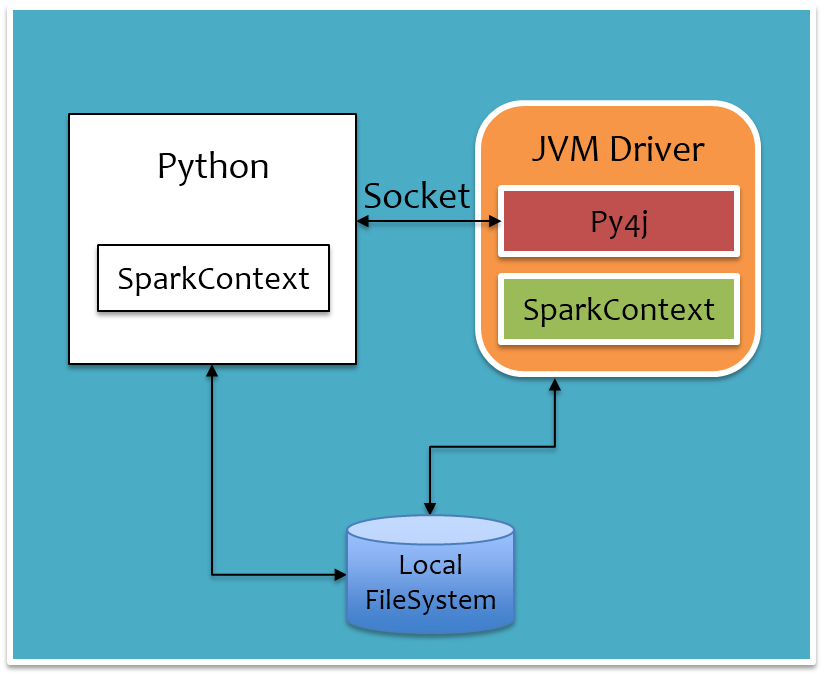
用户Python脚本起来后,首先会实例化Python版的SparkContext对象,在实例化过程中会做两件事:
- 实例化Py4j GatewayClient,连接JVM中的Py4j GatewayServer,后续在Python中调用Java的方法都是借助这个Py4j Gateway
- 通过Py4j Gateway在JVM中实例化SparkContext对象
经过上面两步后,SparkContext对象初始化完毕,Driver已经起来了,开始申请Executor资源,同时开始调度任务。用户Python脚本中定义的一系列处理逻辑最终遇到action方法后会触发Job的提交,提交Job时是直接通过Py4j调用Java的PythonRDD.runJob方法完成,映射到JVM中,会转给sparkContext.runJob方法,Job运行完成后,JVM中会开启一个本地Socket等待Python进程拉取,对应地,Python进程在调用PythonRDD.runJob后就会通过Socket去拉取结果。
把前面运行时架构图中Driver部分单独拉出来,如下图所示,通过PythonRunner入口main函数拉起JVM和Python进程,JVM进程对应下图橙色部分,Python进程对应下图白色部分。Python进程通过Py4j调用Java方法提交Job,Job运行结果通过本地Socket被拉取到Python进程。还有一点是,对于大数据量,例如广播变量等,Python进程和JVM进程是通过本地文件系统来交互,以减少进程间的数据传输。
2.2 Executor端运行原理
为了方便阐述,以Spark On Yarn为例,当Driver申请到Executor资源时,会通过CoarseGrainedExecutorBackend(其中有main方法)拉起JVM,启动一些必要的服务后等待Driver的Task下发,在还没有Task下发过来时,Executor端是没有Python进程的。当收到Driver下发过来的Task后,Executor的内部运行过程如下图所示。

Executor端收到Task后,会通过launchTask运行Task,最后会调用到PythonRDD的compute方法,来处理一个分区的数据,PythonRDD的compute方法的计算流程大致分三步走:
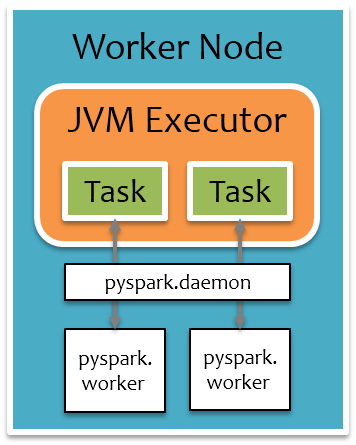
- 如果不存在pyspark.deamon后台Python进程,那么通过Java Process的方式启动pyspark.deamon后台进程,注意每个Executor上只会有一个pyspark.deamon后台进程,否则,直接通过Socket连接pyspark.deamon,请求开启一个pyspark.worker进程运行用户定义的Python函数或Lambda表达式。pyspark.deamon是一个典型的多进程服务器,来一个Socket请求,fork一个pyspark.worker进程处理,一个Executor上同时运行多少个Task,就会有多少个对应的pyspark.worker进程。
- 紧接着会单独开一个线程,给pyspark.worker进程喂数据,pyspark.worker则会调用用户定义的Python函数或Lambda表达式处理计算。
- 在一边喂数据的过程中,另一边则通过Socket去拉取pyspark.worker的计算结果。
把前面运行时架构图中Executor部分单独拉出来,如下图所示,橙色部分为JVM进程,白色部分为Python进程,每个Executor上有一个公共的pyspark.deamon进程,负责接收Task请求,并fork pyspark.worker进程单独处理每个Task,实际数据处理过程中,pyspark.worker进程和JVM Task会较频繁地进行本地Socket数据通信。
3、总结
总体上来说,PySpark是借助Py4j实现Python调用Java,来驱动Spark应用程序,本质上主要还是JVM runtime,Java到Python的结果返回是通过本地Socket完成。虽然这种架构保证了Spark核心代码的独立性,但是在大数据场景下,JVM和Python进程间频繁的数据通信导致其性能损耗较多,恶劣时还可能会直接卡死,所以建议对于大规模机器学习或者Streaming应用场景还是慎用PySpark,尽量使用原生的Scala/Java编写应用程序,对于中小规模数据量下的简单离线任务,可以使用PySpark快速部署提交。
文章来源
http://sharkdtu.com/posts/pyspark-internal.html
PySpark 的背后原理的更多相关文章
- PySpark 的背后原理--在Driver端,通过Py4j实现在Python中调用Java的方法.pyspark.executor 端一个Executor上同时运行多少个Task,就会有多少个对应的pyspark.worker进程。
PySpark 的背后原理 Spark主要是由Scala语言开发,为了方便和其他系统集成而不引入scala相关依赖,部分实现使用Java语言开发,例如External Shuffle Service等 ...
- 再谈angularJS数据绑定机制及背后原理—angularJS常见问题总结
这篇是对angularJS的一些疑点回顾,是对目前angularJS开发的各种常见问题的整理汇总.如果对文中的题目全部了然于胸,觉得对整个angular框架应该掌握的七七八八了.希望志同道合的通知补充 ...
- 再谈HTTP2性能提升之背后原理—HTTP2历史解剖
即使千辛万苦,还是把网站升级到http2了,遇坑如<phpcms v9站http升级到https加http2遇到到坑>. 因为理论相比于 HTTP 1.x ,在同时兼容 HTTP/1.1 ...
- 理解Promise简单实现的背后原理
在写javascript时我们往往离不开异步操作,过去我们往往通过回调函数多层嵌套来解决后一个异步操作依赖前一个异步操作,然后为了解决回调地域的痛点,出现了一些解决方案比如事件订阅/发布的.事件监听的 ...
- git原理学习记录:从基本指令到背后原理,实现一个简单的git
一开始我还担心 git 的原理会不会很难懂,但在阅读了官方文档后我发现其实并不难懂,似乎可以动手实现一个简单的 git,于是就有了下面这篇学习记录. 本文的叙述思路参照了官方文档Book的原理介绍部分 ...
- 【拖拽可视化大屏】全流程讲解用python的pyecharts库实现拖拽可视化大屏的背后原理,简单粗暴!
"整篇文章较长,干货很多!建议收藏后,分章节阅读." 一.设计方案 整体设计方案思维导图: 整篇文章,也将按照这个结构来讲解. 若有重点关注部分,可点击章节目录直接跳转! 二.项目 ...
- Spark 精品文章转载(目录)
学习 Spark 中,别人整理不错的文章,转载至本博客,方便自己学习,并按照不同的模块归档整理.每个文章作者能力不同,写文章所处的时间点不同,可能会略有差异,在阅读的同时,注意当时的文章的内容是否已经 ...
- [源码解析] 深度学习分布式训练框架 horovod (8) --- on spark
[源码解析] 深度学习分布式训练框架 horovod (8) --- on spark 目录 [源码解析] 深度学习分布式训练框架 horovod (8) --- on spark 0x00 摘要 0 ...
- 手把手教你实现热更新功能,带你了解 Arthas 热更新背后的原理
文章来源:https://studyidea.cn/java-hotswap 一.前言 一天下午正在摸鱼的时候,测试小姐姐走了过来求助,说是需要改动测试环境 mock 应用.但是这个应用一时半会又找不 ...
随机推荐
- 诡异的楼梯 HDU1180
这题做了很久 做好了感觉很简单... 现在做题思路更加清晰了 一个要点就是 当楼梯过不去的时候不能是先过去时间加2 必须得回去等一秒 否则queue的时间顺序会被打破 #include< ...
- python selenium-webdriver 元素定位(三)
上两篇的博文中介绍了python selenium的环境搭建和编写的第一个自动化测试脚本,从第二篇的例子中看出来再做UI级别的自动化测试的时候,有一个至关重要的因素,那就是元素的定位,只有从页面上找到 ...
- Linux —— 目录(文件夹)及文件相关处理指令
可参考这篇文章:https://mp.weixin.qq.com/s?__biz=MzU4MTU3OTI0Mg==&mid=2247484269&idx=1&sn=38869a ...
- [OpenCV-Python] OpenCV 中计算摄影学 部分 IX 对象检测 部分 X
部分 IX计算摄影学 OpenCV-Python 中文教程(搬运)目录 49 图像去噪目标 • 学习使用非局部平均值去噪算法去除图像中的噪音 • 学习函数 cv2.fastNlMeansDenoisi ...
- copy 深浅复制
- Golang vs PHP 之文件服务器
前面的话 作者为golang脑残粉,本篇内容可能会引起phper不适,请慎读! 前两天有同事遇到一个问题,需要一个能支持上传.下载功能的HTTP服务器做一个数据中心.我刚好弄过,于是答应帮他搭一个. ...
- 【*】CAS 是什么,Java8是如何优化 CAS 的
文章结构 前言 想要读懂 Java 中的并发包,就是要先读懂 CAS 机制,因为 CAS 是并发包的底层实现原理.本文主要讨论 CAS 是如何保证操作的原子性的 Java8 对 CAS 进行了哪些 ...
- ubuntu14.06 Lts开启ssh服务
(1) apt-get install openssh-server (2)检查ssh服务开启状态 (3)通过以下命令启动ssh服务 service ssh stop service ssh star ...
- django-用户验证系统
django提供了一套用户验证系统,但是要使用这个系统,必须要使用django内置的用户模型:django.contrib.auth.models.User,这个模型中预先定义了一些字段,其中只有us ...
- android 按钮特效 波纹 Android button effects ripple
android 按钮特效 波纹 Android button effects ripple 作者:韩梦飞沙 Author:han_meng_fei_sha 邮箱:313134555@qq.com E- ...