微软BI 之SSIS 系列 - Lookup 中的字符串比较大小写处理 Case Sensitive or Insensitive
开篇介绍
前几天碰到这样的一个问题,在 Lookup 中如何设置大小写不敏感比较,即如何在 Lookup 中的字符串比较时不区分大小写?
实际上就这个问题已经有很多人提给微软了,但是得到的结果就是 Closed and Won’t fix。 说白了,这个就是 By Design,包括到现在的 2012 也没有这个配置选项。
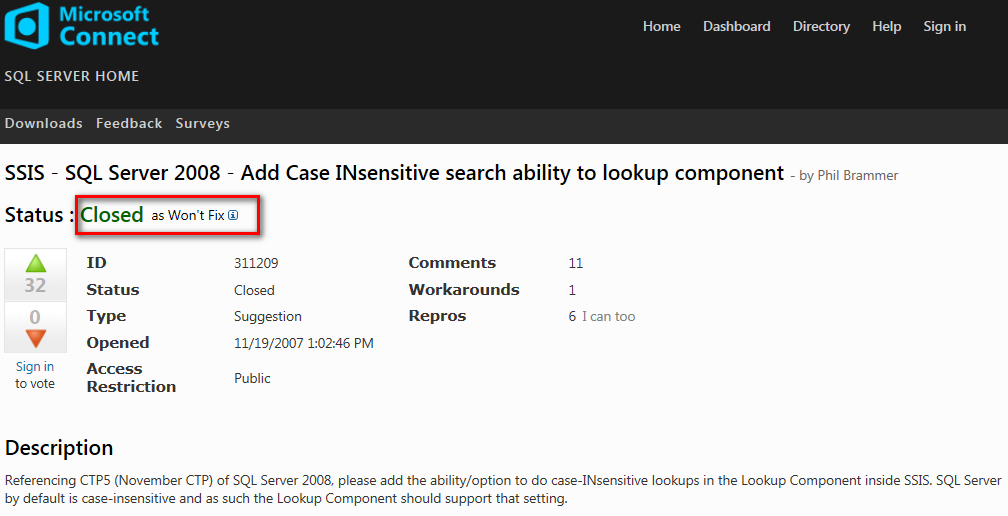
看看大家的抱怨,其实还是非常期望能够加上这个功能的。

Lookup 大小写的处理
还是来了解一下 Lookup 中这个特征吧。
通常情况下,我们一般选择的都是 Full Cache 全缓存模式(关于 Lookup 缓存的几种模式,大家可以参考我的另外一篇文章 - 微软BI 之SSIS 系列 - Lookup 组件的使用与它的几种缓存模式 - Full Cache, Partial Cache, NO Cache)。选择全缓存模式就意味着在这个 Task 真正执行之前,在 Lookup 中的数据将全部首先被缓存,缓存完成之后再开始执行操作。但是在这里就要注意,如果选择的是全缓存,默认的字符串比较就是区分大小写的 CASE SENSITIVE 模式。
Full Cache 的时候采用的是 Windows Collations 中的区分大小写的比较方式。只有不使用 Full Cache 的时候才能使用到 SQL Collations。那我们知道,除了 Full Cache 外,还有 Partial Cache 部分缓存和 No Cache 不缓存。也就是说,如果使用了 Partial Cache 和 No Cache 缓存模式,使用的就是 SQL Collations。
那是不是采用了 Partial Cache 和 No Cache 就可以不区分大小写进行字符串比较呢?这种说法也不全正确!
因为这要取决于你 Lookup 中数据库本身的 Collations 设置 –

如果选择的 Collation 使用的是CI就是不区分大小写 (Case Insensitive),如果是CS(Case Sensitive)就是区分大小写。一般情况下,默认的都是 CI,所以这也就是很多人认为选择了 Partial Cache 或者 No Cache 就能区分大小写的原因,但是这个观点需要被纠正一下。
如何在使用 Lookup 的时候不区分大小写?
方法一
使用 Partial Cache 或者 No Cache 并确认 Lookup 中连接的数据源数据库的 Collation 是 Case Insensitive 方式。但是这种方式就意味着要放弃 Lookup 的 Full Cache,而在通常情况下,使用 Full Cache 的效率更高一些,参看- 微软BI 之SSIS 系列 - Lookup 组件的使用与它的几种缓存模式 - Full Cache, Partial Cache, NO Cache。
方式二
还是使用 Full Cache,但是在进入 Lookup 的 Task 和 Lookup Task 本身的数据查询就不要使用表或者视图方式了,而是改为 T-SQL 查询的方式,那么通过设置两个比较源的 UPPER() / LOWER() 就可以达到忽略大小写比较的目的了! 当然如果上游数据是非数据表而是文件等其它类型,则可以使用其它比如 Derived Column 等使用函数来转变大小写也是可以的。
更多 BI 文章请参看 BI 系列随笔列表 (SSIS, SSRS, SSAS, MDX, SQL Server) 如果觉得这篇文章看了对您有帮助,请帮助推荐,以方便他人在 BIWORK 博客推荐栏中快速看到这些文章。
微软BI 之SSIS 系列 - Lookup 中的字符串比较大小写处理 Case Sensitive or Insensitive的更多相关文章
- 微软BI 之SSIS 系列 - 数据仓库中实现 Slowly Changing Dimension 缓慢渐变维度的三种方式
开篇介绍 关于 Slowly Changing Dimension 缓慢渐变维度的理论概念请参看 数据仓库系列 - 缓慢渐变维度 (Slowly Changing Dimension) 常见的三种类型 ...
- 微软BI 之SSIS 系列 - Lookup 组件的使用与它的几种缓存模式 - Full Cache, Partial Cache, NO Cache
开篇介绍 先简单的演示一下使用 Lookup 组件实现一个简单示例 - 从数据源表 A 中导出数据到目标数据表 B,如果 A 数据在 B 中不存在就插入新数据到B,如果存在就更新B 和 A 表数据保持 ...
- 微软BI 之SSIS 系列 - 再谈Lookup 缓存
开篇介绍 关于 Lookup 的缓存其实在之前的一篇文章中已经提到了 微软BI 之SSIS 系列 - Lookup 组件的使用与它的几种缓存模式 - Full Cache, Partial Cache ...
- 微软BI 之SSIS 系列 - 在 SSIS 中导入 ACCESS 数据库中的数据
开篇介绍 来自 天善学院 一个学员的问题,如何在 SSIS 中导入 ACCESS 数据表中的数据. 在 SSIS 中导入 ACCESS 数据库数据 ACCESS 实际上是一个轻量级的桌面数据库,直接使 ...
- 微软BI 之SSIS 系列 - MVP 们也不解的 Scrip Task 脚本任务中的一个 Bug
开篇介绍 前些天自己在整理 SSIS 2012 资料的时候发现了一个功能设计上的疑似Bug,在 Script Task 中是可以给只读列表中的变量赋值.我记得以前在 2008 的版本中为了弄明白这个配 ...
- 微软BI 之SSIS 系列 - 使用 Script Component Destination 和 ADO.NET 解析不规则文件并插入数据
开篇介绍 这一篇文章是 微软BI 之SSIS 系列 - 带有 Header 和 Trailer 的不规则的平面文件输出处理技巧 的续篇,在上篇文章中介绍到了对于这种不规则文件输出的处理方式.比如下图中 ...
- 微软BI 之SSIS 系列 - 使用 Script Task 访问非 Windows 验证下的 SMTP 服务器发送邮件
原文:微软BI 之SSIS 系列 - 使用 Script Task 访问非 Windows 验证下的 SMTP 服务器发送邮件 开篇介绍 大多数情况下我们的 SSIS 包都会配置在 SQL Agent ...
- 微软BI 之SSIS 系列 - 带有 Header 和 Trailer 的不规则的平面文件输出处理技巧
案例背景与需求介绍 之前做过一个美国的医疗保险的项目,保险提供商有大量的文件需要发送给比如像银行,医疗协会,第三方服务商等.比如像与银行交互的 ACH 文件,传送给协会的 ACH Credit 等文件 ...
- 微软BI 之SSIS 系列 - Merge, Merge Join, Union All 合并组件的使用以及Sort 排序组件同步异步的问题
开篇介绍 SSIS Data Flow 中有几个组件可以实现不同数据源的数据合并功能,比如 Merger, Merge Join 和 Union All.它们的功能比较类似,同时也比较容易混淆,下面是 ...
随机推荐
- 通过T4模板实现代码自动生成
1:准备.tt模板 using BBFJ.OA.IBLL; using BBFJ.OA.IDAL; using BBFJ.OA.Model; using System; using System.Co ...
- linux常用软件安装,常用命令
jdk [root@localhost]# tar -zxvf jdk-8u144-linux-x64.tar.gz [root@localhost]# vi /etc/profile 在profil ...
- mysql的基本演示
数据库需要配置 cmd打开doc窗口 net start mysql:启动数据库 net stop mysql :停止数据库 表的定义:列 行 主键
- 2017-2018-2 20155309 南皓芯 Exp5 MSF基础应用
实践内容 本实践目标是掌握metasploit的基本应用方式,重点常用的三种攻击方式的思路.具体需要完成: 1.1一个主动攻击实践,如ms08_067; 1.2 一个针对浏览器的攻击,如ms11_05 ...
- HDFS上创建文件、写入内容
1.创建文件 hdfs dfs -touchz /aaa/aa.txt 2.写入内容 echo "<Text to append>" | hdfs dfs -appen ...
- SqlServer基础语句练习(一)
学了不少东西,感觉自己的sql语句还是很不好,从基础学起吧. 来一段sql脚本: create database tongji go use tongji go create table studen ...
- [转] equals和==的区别小结
==: == 比较的是变量(栈)内存中存放的对象的(堆)内存地址,用来判断两个对象的地址是否相同,即是否是指相同一个对象.比较的是真正意义上的指针操作. 1.比较的是操作符两端的操作数是否是同一个对象 ...
- #8 //HDU 5730 Shell Necklace(CDQ分治+FFT)
Description 给出长度分别为1~n的珠子,长度为i的珠子有a[i]种,每种珠子有无限个,问用这些珠子串成长度为n的链有多少种方案 题解: dp[i]表示组合成包含i个贝壳的项链的总方案数 转 ...
- 【AtCoder】Yahoo Programming Contest 2019
A - Anti-Adjacency K <= (N + 1) / 2 #include <bits/stdc++.h> #define fi first #define se se ...
- python全栈开发day17-常用模块collections,random,time,os,sys,序列化(json pickle shelve)
1.昨日内容回顾 1.正则表达式 # 正则表达式 —— str # 检测字符串是否符合要求 # 从大段的文字中找到符合要求的内容 1).元字符 #. # 匹配除换行 ...