Sql server 查询某个时间段,分布有几周,几月和几日
1. 查询:以“周”为单位
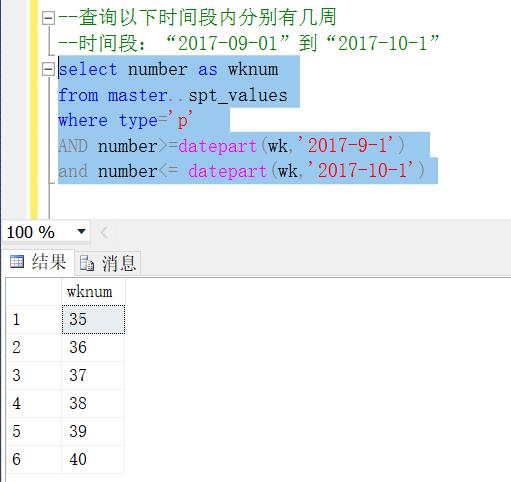
--查询以下时间段内分别有几周
--时间段:“2017-09-01”到“2017-10-1”
select number as wknum
from master..spt_values
where type='p'
AND number>=datepart(wk,'2017-9-1')
and number<= datepart(wk,'2017-10-1')
结果如下图
2. 查询:以“月”为单位
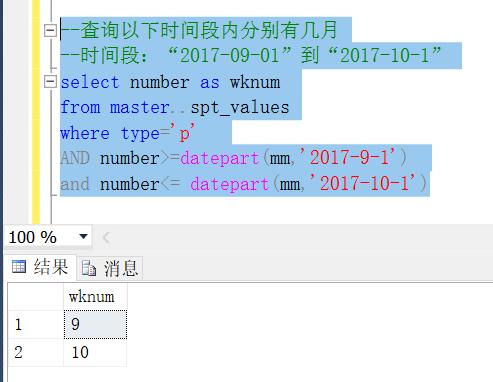
--查询以下时间段内分别有几月
--时间段:“2017-09-01”到“2017-10-1”
select number as wknum
from master..spt_values
where type='p'
AND number>=datepart(mm,'2017-9-1')
and number<= datepart(mm,'2017-10-1')
结果如下图
3. 查询:以“日”为单位
--查询以下时间段内分别有几日
--时间段:“2017-09-29”到“2017-10-3”
select convert(varchar(10),DATEADD(day,number,'2017-9-29') ,120) wknum
from master.dbo.spt_values
where type='p'
AND number<=DATEDIFF(day,'2017-9-29','2017-10-3')
结果如下图

Sql server 查询某个时间段,分布有几周,几月和几日的更多相关文章
- sql server 查询某个时间段共有多少周及每周的日期段
sql 语句 as wknum,dateadd(wk,number,'2017-01-01') as firstday, (,, then '2017-12-31' ,,'2017-01-01')) ...
- [转] 利用SET STATISTICS IO和SET STATISTICS TIME 优化SQL Server查询性能
首先需要说明的是这篇文章的内容并不是如何调节SQL Server查询性能的(有关这方面的内容能写一本书),而是如何在SQL Server查询性能的调节中利用SET STATISTICS IO和SET ...
- SQL SERVER 查询性能优化——分析事务与锁(五)
SQL SERVER 查询性能优化——分析事务与锁(一) SQL SERVER 查询性能优化——分析事务与锁(二) SQL SERVER 查询性能优化——分析事务与锁(三) 上接SQL SERVER ...
- SQL Server 查询性能优化 相关文章
来自: SQL Server 查询性能优化——堆表.碎片与索引(一) SQL Server 查询性能优化——堆表.碎片与索引(二) SQL Server 查询性能优化——覆盖索引(一) SQL Ser ...
- 利用SET STATISTICS IO和SET STATISTICS TIME 优化SQL Server查询性能
首先需要说明的是这篇文章的内容并不是如何调节SQL Server查询性能的(有关这方面的内容能写一本书),而是如何在SQL Server查询性能的调节中利用SET STATISTICS IO和SET ...
- 如何找出你性能最差的SQL Server查询
我经常会被反复问到这样的问题:”我有一个性能很差的SQL Server.我如何找出最差性能的查询?“.因此在今天的文章里会给你一些让你很容易找到问题答案的信息向导. 问SQL Server! SQL ...
- 使用WinDbg调试SQL Server查询
上一篇文章我给你介绍了WinDbg的入门,还有你如何能附加到SQL Server.今天的文章,我们继续往前一步,我会向你展示使用WinDbg调试SQL Server查询需要的步骤.听起来很有意思?我们 ...
- sql server 查询分析器消息栏里去掉“(5 行受影响)”
sql server 查询分析器消息栏里去掉"(5 行受影响)" 在你代码的开始部分加上这个命令: set nocount on 记住在代码结尾的地方再加上: set ...
- Sql Server查询性能优化之走出索引的误区
据了解绝大多数开发人员对于索引的理解都是一知半解,局限于大多数日常工作没有机会.也什么没有必要去关心.了解索引,实在哪天某个查询太慢了找到查询条件建个索引就ok,哪天又有个查询慢了,再建立个索引就是, ...
随机推荐
- pgm14
这部分讨论在有数据缺失情况下的 learning 问题,这里仍然假定了图结构是已知的. 首先需要讨论的是为什么会缺失,很多情况下缺失并不是“随机”的:有的缺失是人为的,那么某些情况下缺失的可以直接补上 ...
- Leetcode 242.有效的字母异位词 By Python
给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的一个字母异位词. 示例 1: 输入: s = "anagram", t = "nagaram" ...
- 自学Aruba5.3.1-Aruba安全认证-有PEFNG 许可证环境的认证配置OPEN、PSK
点击返回:自学Aruba之路 自学Aruba5.3.1-Aruba安全认证-有PEFNG 许可证环境的认证配置OPEN.PSK OPEN.PSK都需要设置Initial Role角色, 但是角色派生完 ...
- BZOJ 4552 [Tjoi2016&Heoi2016]排序 | 二分答案 线段树
题目链接 题面 题目描述 在2016年,佳媛姐姐喜欢上了数字序列.因而他经常研究关于序列的一些奇奇怪怪的问题,现在他在研究一个难题,需要你来帮助他.这个难题是这样子的:给出一个1到n的全排列,现在对这 ...
- codeforces 793B - Igor and his way to work(dfs、bfs)
题目链接:http://codeforces.com/problemset/problem/793/B 题目大意:告诉你起点和终点,要求你在只能转弯两次的情况下能不能到达终点.能就输出“YES”,不能 ...
- 【CF711D】Directed Roads
题目大意:给定一个 N 个点,N 条边的无向图,现给每条边定向,求有多少种定向方式使得定向后的有向图中无环. 题解:显然,这是一个外向树森林,定向后存在环的情况只能发生在基环树中环的位置,环分成顺时针 ...
- 简单的使用gulp生成雪碧图
有一个在线工具:https://www.toptal.com/developers/css/sprite-generator.生成雪碧图是极其方便的. 现在呢,我们来试试用gulp来生成雪碧图. 第一 ...
- Shell变量的取用、删除、取代与替换
<<鸟哥的私房菜>> 注意: 通配符适用的地方:shell命令行或者shell脚本中 正则表达式适用的地方:字符串处理时,一般有一般正则和Perl正则. 在文本过滤工具里,都是 ...
- Python自定义Module中__init__.py文件介绍
./pyModuleTest/├── addutil│ ├── add.py│ ├── add.pyc│ ├── __init__.py│ ├── __init__.pyc│ └─ ...
- php框架:Flight 简介
Flight是一个php的极简的有着微内核的框架,能过快速的构建RESTful的应用 官网地址: http://flightphp.com/ github地址:https://github.com/m ...