【Hadoop 分布式部署 三:基于Hadoop 2.x 伪分布式部署进行修改配置文件】
1.规划好哪些服务运行在那个服务器上

需要配置的配置文件

2. 修改配置文件,设置服务运行机器节点
首先在 hadoop-senior 的这台主机上 进行 解压 hadoop2.5 按照伪分布式的配置文件来进行配置
使用命令 :tar -zxvf hadoop-2.5.0.tar.gz -C /opt/app/ (解压 hadoop 2.5)
然后进入 cd /opt/app/hadoop-2.5.0/etc
将里面一开始的配置文件重命令 mv hadoop backup-hadoop
然后将一开始伪分布式中的配置文件复制过来 使用命令 cp -r /opt/moudles/hadoop-2.5.0/etc/hadoop ./
(如果在Windows下 想使用方便,可以在C:\Windows\System32\drivers\etc目录下 修改hosts文件 配置 虚拟机的主机IP)

开始配置
使用notepad 进行配置hadoop 的配置文件
hadoop.env export JAVA_HOME=/opt/modules/jdk1.7.0_67 (默认已经配置好了,不用更改)
core-site.xml 文件中的内容配置
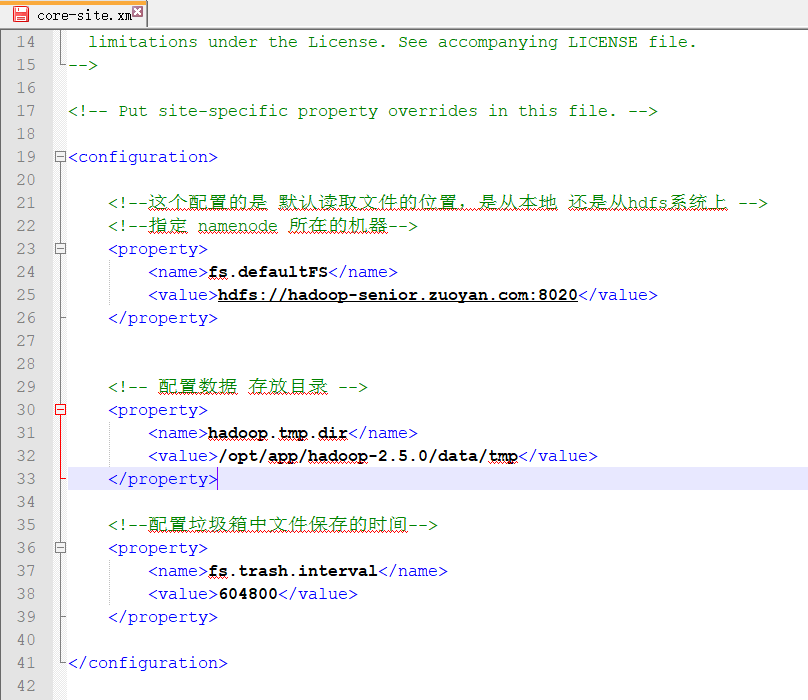
<configuration> <!--这个配置的是 默认读取文件的位置,是从本地 还是从hdfs系统上 -->
<!--指定 namenode 所在的机器-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-senior.zuoyan.com:8020</value>
</property> <!-- 配置数据 存放目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/app/hadoop-2.5.0/data/tmp</value>
</property> <!--配置垃圾箱中文件保存的时间-->
<property>
<name>fs.trash.interval</name>
<value>604800</value>
</property> </configuration>
因为没有数据存放的目录 所以需要配置一下 hadoop.tmp.dir 的目录
命令 : mkdir -p /opt/app/hadoop-2.5.0/data/tmp
配置hdfs
首先配置hdfs-site.xml 文件
因为是分布式 所以不需要配置副本数 去掉 dfs.replication
配置SecondaryNameNode 所在的节点 dfs.namenode.secondary.http-address hadoop-senior03.zuoyan.com
<configuration>
<!--配置secondary namenode 所在的主机-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop-senior03.zuoyan.com:</value>
</property>
</configuration>
配置slaves 也就是配制 DataNode NodeManager
配置的内容为
hadoop-senior.zuoyan.com
hadoop-senior02.zuoyan.com
hadoop-senior03.zuoyan.com
配置yarn
首先配置 yarn.env 配置yarn的环境变量 (我这里已经配置好了,就不用更改了)

配置yarn-site.xml 这个文件
这个配置文件只需要 将 resourcesmanager 所在的主机节点更改成第二台主机就可以了
剩下的配置文件不用修改,配置文件内容如下
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--配置resourcemanager 所在的主机名 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-senior02.zuoyan.com</value>
</property>
<!--启用历史服务器的日志聚集功能-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!--设置日志在文件系统上的存放时间-->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>640800</value>
</property>
<!--配置NodeManager Resource-->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>4</value>
</property>
</configuration>
配置 mapred-site.xml
配置 JobHistoryServer 的配置文件 资源设计的时候 就把他放在了第一台主机上,所以 保持默认配置文件即可,修改一下主机名就行
配置文件的内容如下
<configuration> <property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property> <!--配置历史记录服务器所在地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop-senior.zuoyan.com:10020</value> </property> <property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop-senior.zuoyan.com:19888</value>
</property> </configuration>
到此,配置文件就配置完成了!下一步就是分发到各个机器上去
(还有一个小点就是 删除 在 /opt/app/hadoop-2.5.0/share 下的 doc文件夹,这个文件是文档,我们一般,不用,而且还占用磁盘空间 大概占用的磁盘空间是1.5G )
好了,这篇随笔就到这里了,下一篇继续!
【Hadoop 分布式部署 三:基于Hadoop 2.x 伪分布式部署进行修改配置文件】的更多相关文章
- 网站用户行为分析——Hadoop的安装与配置(单机和伪分布式)
Hadoop安装方式 Hadoop的安装方式有三种,分别是单机模式,伪分布式模式,伪分布式模式,分布式模式. 单机模式:Hadoop默认模式为非分布式模式(本地模式),无需进行其他配置即可运行.非分布 ...
- Hadoop整理五(基于Hadoop的数据仓库Hive)
数据仓库,是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合.它是单个数据存储,出于分析性报告和决策支持目的而创建. 为需要业务智能的企业,提供指导业务流程改进.监视时间.成本.质量以及控 ...
- 【连载】redis库存操作,分布式锁的四种实现方式[三]--基于Redis watch机制实现分布式锁
一.redis的事务介绍 1. Redis保证一个事务中的所有命令要么都执行,要么都不执行.如果在发送EXEC命令前客户端断线了,则Redis会清空事务队列,事务中的所有命令都不会执行.而一旦客户端发 ...
- hadoop搭建伪分布式集群(centos7+hadoop-3.1.0/2.7.7)
目录: Hadoop三种安装模式 搭建伪分布式集群准备条件 第一部分 安装前部署 1.查看虚拟机版本2.查看IP地址3.修改主机名为hadoop4.修改 /etc/hosts5.关闭防火墙6.关闭SE ...
- hadoop 2.7.3伪分布式环境运行官方wordcount
hadoop 2.7.3伪分布式模式运行wordcount 基本环境: 系统:win7 虚机环境:virtualBox 虚机:centos 7 hadoop版本:2.7.3 本次以伪分布式模式来运行w ...
- hadoop伪分布式
一.安装jdk 1.下载解压 2.配置环境变量 配置成功: 二.ssh免密码登录 https://www.cnblogs.com/suwy/p/9326087.html 三.hadoop伪分布式配置 ...
- 云计算课程实验之安装Hadoop及配置伪分布式模式的Hadoop
一.实验目的 1. 掌握Linux虚拟机的安装方法. 2. 掌握Hadoop的伪分布式安装方法. 二.实验内容 (一)Linux基本操作命令 Linux常用基本命令包括: ls,cd,mkdir,rm ...
- java大数据最全课程学习笔记(1)--Hadoop简介和安装及伪分布式
Hadoop简介和安装及伪分布式 大数据概念 大数据概论 大数据(Big Data): 指无法在一定时间范围内用常规软件工具进行捕捉,管理和处理的数据集合,是需要新处理模式才能具有更强的决策力,洞察发 ...
- Hadoop学习笔记(一):ubuntu虚拟机下的hadoop伪分布式集群搭建
hadoop百度百科:https://baike.baidu.com/item/Hadoop/3526507?fr=aladdin hadoop官网:http://hadoop.apache.org/ ...
- Hadoop 2.7 伪分布式环境搭建
1.安装环境 ①.一台Linux CentOS6.7 系统 hostname ipaddress subnet mask ...
随机推荐
- Runtime(IV) - 序列化与反序列化
准备条件 父类 Biology Biology.h #import <Foundation/Foundation.h> @interface Biology : NSObject { NS ...
- GridFS Example
http://api.mongodb.com/python/current/examples/gridfs.html This example shows how to use gridfs to s ...
- 计算属性(computed)、方法(methods)和侦听属性(watch)的区别与使用场景
1,computed 能实现的,methods 肯定也能够实现. 2,不同之处在于,computed 是基于他的依赖进行缓存的,computed 只有在他的的相关依赖发生改变的时候才会重新计算. 如果 ...
- python SQLite说一点点, python使用数据库需要注意的几点
SQLite是一种嵌入式数据库,它的数据库就是一个文件.由于SQLite本身是C写的,而且体积很小,所以,经常被集成到各种应用程序中,甚至在iOS和Android的App中都可以集成. Python就 ...
- 【swiper轮播插件】解决swiper轮播插件触控屏问题
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Linux基础命令---管理组gpasswd
gpasswd gpasswd指令用来管理组文件“/etc/group”和“/etc/gshadow”,每个组可以设置管理员.组员.密码.系统管理员可以使用-A选项定义组管理员,使用-M选项定义成员. ...
- linux 下 tomcat 运行报错 Broken pipe
linux 下 tomcat 运行报错 Broken pipe 感谢:http://hi.baidu.com/liupenglover/blog/item/4048c23ff19f1cd67d1e71 ...
- SpringAOP单元测试时找不到文件。
...applicationContext.xml] cannot be opened because it does not exist. 刚才在进行单元测试时,报这个错,我把它放到了src的某个包 ...
- python字符格式化
使用%格式化字符串 字符串格式化使用格式化操作符即百分号. 在%号的左侧放置一个字符串(格式化字符串),而右侧则放置希望格式化的值. In [17]: name = "wxz" I ...
- mysql备份与还原-mysqldump备份、mysql与source还原
以下都以在linux操作系统上的mysql为例 mysqldump备份 mysqldump实际就是将数据库中的数据转化为建库.建表和插入记录的sql语句 1.备份一个数据库 [或其中几个表],不指定表 ...